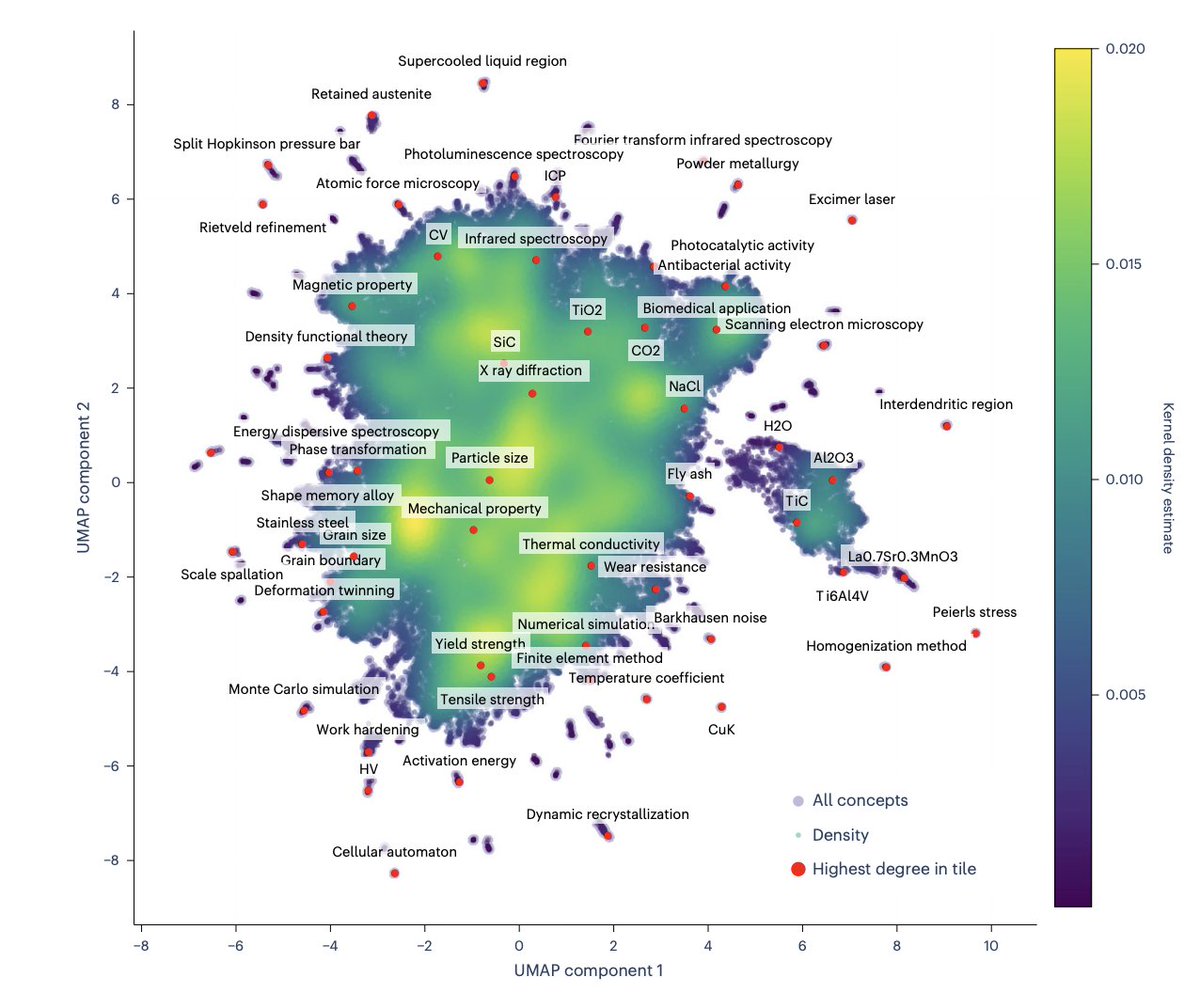
Can AI predict what your next research paper should be about?
Science grows faster than any single researcher can read. In materials science alone, hundreds of thousands of papers now exist, and the most promising ideas often live at the intersection of concepts no one has yet thought to combine.
Marwitz and coauthors take this challenge head on. Starting from ~221,000 materials science abstracts, they fine-tune a LLaMA-2-13B model to extract key concepts — not just keywords, but normalized, semantically meaningful phrases — and build a concept graph with ~137,000 nodes and 13 million edges, where each edge reflects the co-occurrence of two concepts in a published abstract.
The graph evolves over time, and that temporal signal becomes the basis for link prediction: which pairs of currently unconnected concepts will appear together in a future paper? They test several model families — a graph topology baseline (NN on hand-crafted features), concept embeddings from MatSciBERT, a GraphSAGE GNN, and hybrid mixtures of these. The best single metric goes to the Mixture of GNN + Embeddings, reaching AUC 0.943.
The most interesting finding is about distance. Most concept pairs in the graph are already connected through just one or two intermediate nodes. The baseline model is excellent at predicting nearby connections (dprev = 2, recall 73%) but nearly blind to more distant ones (dprev = 3, recall 5.9%). Adding semantic embeddings raises recall at distance 3 to 35% — and those are exactly the combinations most likely to represent genuinely novel research directions.
To validate this beyond metrics, they ran 30-minute interviews with ten materials scientists, each receiving a personalized report of AI-suggested concept pairs. Of 292 evaluated suggestions, 26% were rated as novel and inspiring — including combinations like "conventional ceramic + graphene oxide" and "in-plane polarization + organic solar cell" — ideas the experts had not previously considered.
For R&D teams in industry, this is a concrete step toward AI-assisted hypothesis generation. In sectors like battery materials, catalysis, or specialty coatings, where the literature is vast and cross-domain insight is rare, a system that surfaces non-obvious concept bridges could meaningfully compress the time between literature review and experimental design.
Paper: Marwitz et al., Nature Machine Intelligence (2026) — CC BY 4.0 | https://t.co/I6E4knsD0r
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: https://t.co/nNfpSV5e5I
Blog: https://t.co/i6h8LVQOdl
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,�� our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_ @cong_ml @RobertTLange @_yutaroyamada @shengranhu @j_foerst @hardmaru @jeffclune
“After careful evaluation, Apple determined that Google's Al technology provides the most capable foundation for Apple Foundation Models and is excited about the innovative new experiences it will unlock for Apple users.”
: )
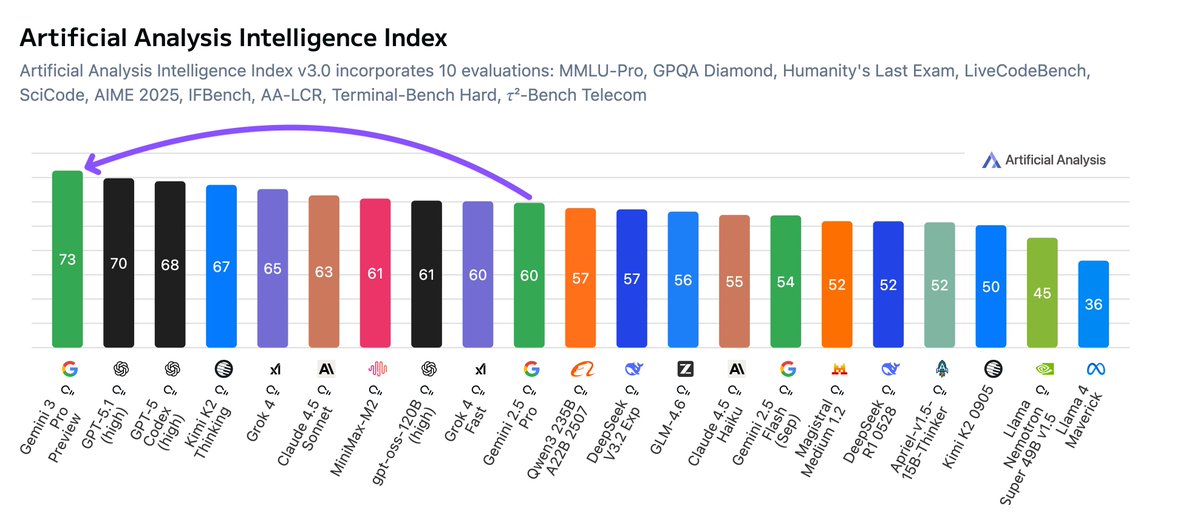
Gemini 3 Pro is the new leader in AI. Google has the leading language model for the first time, with Gemini 3 Pro debuting +3 points above GPT-5.1 in our Artificial Analysis Intelligence Index
@GoogleDeepMind gave us pre-release access to Gemini 3 Pro Preview. The model outperforms all other models in Artificial Analysis Intelligence Index. It demonstrates strength across the board, coming in first in 5 of the 10 evaluations that make up Intelligence Index. Despite these intelligence gains, Gemini 3 Pro Preview shows improved token efficiency from Gemini 2.5 Pro, using significantly fewer tokens on the Intelligence Index than other leading models such as Kimi K2 Thinking and Grok 4. However, given its premium pricing ($2/$12 per million input/output tokens for <200K context), Gemini 3 Pro is among the most expensive models to run our Intelligence Index evaluations.
Key takeaways:
📖 Leading intelligence: Gemini 3 Pro Preview is the leading model in 5 of 10 evals in the Artificial Analysis Intelligence Index, including GPQA Diamond, MMLU-Pro, HLE, LiveCodeBench and SciCode. Its score of 37% on Humanity’s Last Exam is particularly impressive, improving on the previous best model by more than 10 percentage points. It also is leading in AA-Omniscience, Artificial Analysis’ new knowledge and hallucination evaluation, coming first in both Omniscience Index (our lead metric that takes off points for incorrect answers) and Omniscience Accuracy (percentage correct). Given that factual recall correlates closely with model size, this may point to Gemini 3 Pro being a much larger model than its competitors
💻 Advanced coding and agentic capabilities: Gemini 3 Pro Preview leads two of the three coding evaluations in the Artificial Analysis Intelligence Index, including an impressive 56% in SciCode, an improvement of over 10 percentage points from the previous highest score. It is also strong in agentic contexts, achieving the second highest score in Terminal-Bench Hard and Tau2-Bench Telecom
🖼️ Multimodal capabilities: Gemini 3 Pro Preview is a multi-modal model, with the ability to take text, images, video and audio as input. It scores the highest of any model on MMMU-Pro, a benchmark that tests reasoning abilities with image inputs. Google now occupies the first, third and fourth position in our MMMU-Pro leaderboard (with GPT-5.1 taking out second place just last week)
💲Premium Pricing: To measure cost, we report Cost to Run the Artificial Analysis Intelligence Index, which combines input and output token prices with token efficiency to reflect true usage cost. Despite the improvement in token efficiency from Gemini 2.5 Pro, Gemini 3 Pro Preview costs more to run. Its higher token pricing of $2/$12 USD per million input/output tokens (≤200k token context) results in a 12% increase in the cost to run the Artificial Analysis Intelligence Index compared to its predecessor, and the model is among the most expensive to run on our Intelligence Index. Google also continues to price long context workloads higher than lower context workloads, charging $4/$18 per million input/output tokens for ≥200k token context.
⚡ Speed: Gemini 3 Pro Preview has comparable speeds to Gemini 2.5 Pro, with 128 output tokens per second. This places it ahead of other frontier models including GPT-5.1 (high), Kimi K2 Thinking and Grok 4. This is potentially supported by Google’s first-party TPU accelerators
Other details: Gemini 3 Pro Preview has a 1 million token context window, and includes support for tool calling, structured outputs, and JSON mode
See below for further analysis
94% of the universe’s galaxies are permanently beyond our reach. If we could travel at the speed of light and left today, we'd still only be able to reach 6% of them
[read more: https://t.co/BoQfTS8kXN]
https://t.co/MrASyafblA
#Antarctic sea ice area has set a new daily record low so far for all of January...
[Other visualizations perspectives at https://t.co/V0Lt0w1sTi. Data from @NSIDC at https://t.co/aUqFYm698E.]
“Multilayer networks for text analysis with multiple data types”, new paper with C. Hyland, Y. Tao, L. Azizi, @martgerlach, & @tiagopeixoto published today at @epj_ds
Paper: https://t.co/UYemtXOgl2
Codes: https://t.co/sBVBBkhKBJ
Our course on "Networks and high- dimensional" inference is available through the @DiscoverAMSI ACE program for masters and honours students in Australia. Running semester 1 2021 at the School of Maths and Stats at @Sydney_Science
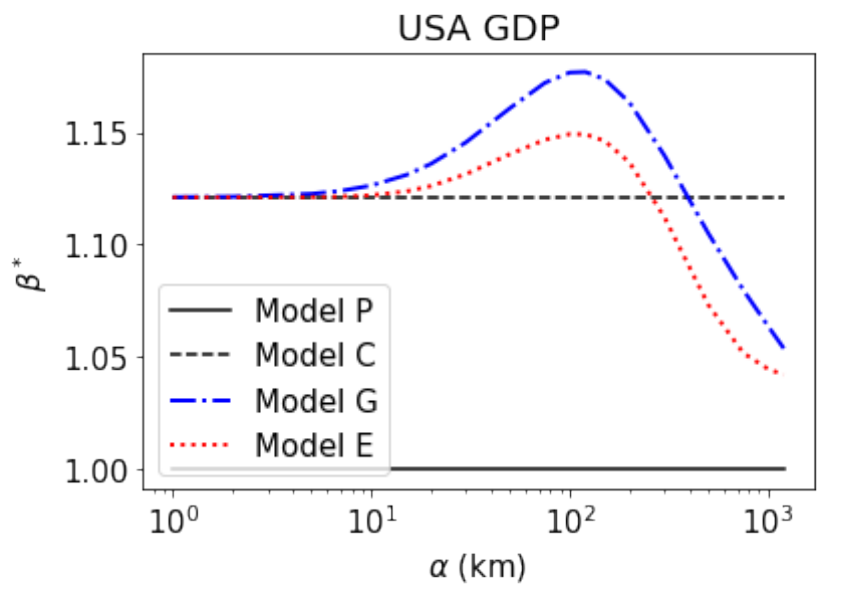
... to consider a generative process that allocates the observations y to the population x accounting for spatial distances.
Bayesian Model comparison confirms the improvement and reveals that β depends on the interaction distance α.
Thanks @somwrita_sarkar@ElsaArcaute
Urban scaling laws state that observables "y" scale with population "x" of cities as
y ~ x^β
Empirical support is based on linear fitting log-transformed variables, which has serious problems, noted eg by @ClementineCttn @DiegoRybski@remilouf
An alternative is ... [2/3]
"Spatial interactions in urban scaling laws", my new pre-print at: https://t.co/ZHLQHnXm71
Codes and data available at:
https://t.co/tt5jyR3eN4
It shows how to account for the location of cities and to compare alternative models beyond least-square fitting.
[1/3]
Looking on the information about the models, it is reassuring that the govt is making decisions based on solid scientific advice. Still, it is surprising how easily it is said that the models “can’t predict the future”, don’t use Australian data, and should be used qualitatively
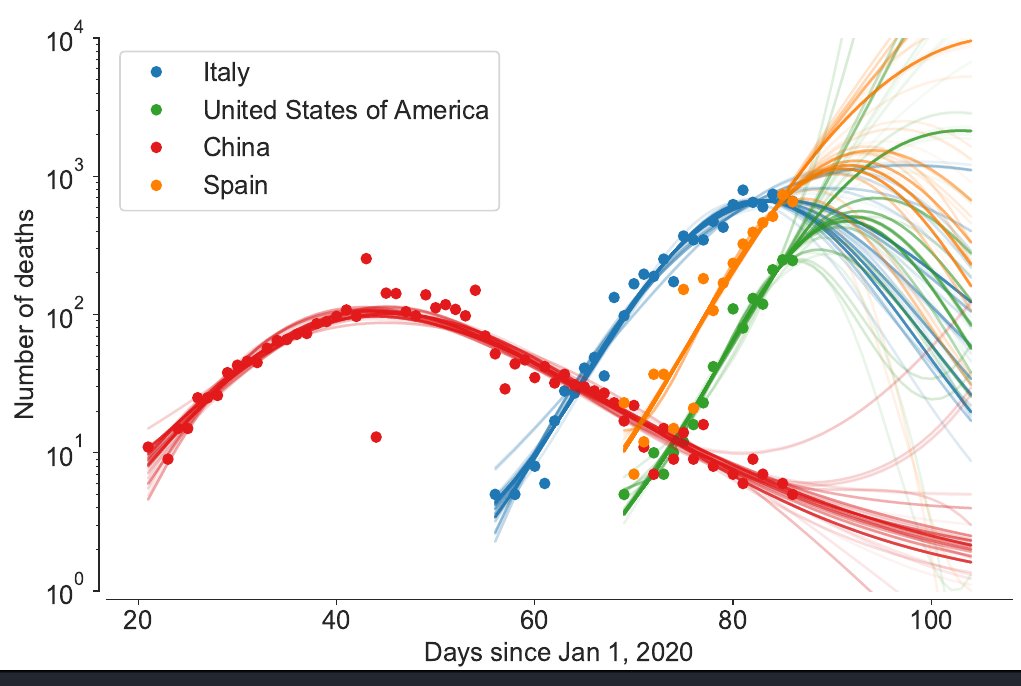
During the last week, we have been using the Bayesian machine scientist to model the spread of #COVID19. Here are the sampled models for the number of daily deaths with data up to March 27



















![ZLabe's tweet photo. #Antarctic sea ice area has set a new daily record low so far for all of January...
[Other visualizations perspectives at https://t.co/V0Lt0w1sTi. Data from @NSIDC at https://t.co/aUqFYm698E.] https://t.co/fBXmBxLbgj](https://pbs.twimg.com/media/FnG7SMsXkAAeeah.jpg)


![EduardoGAltmann's tweet photo. "Spatial interactions in urban scaling laws", my new pre-print at: https://t.co/ZHLQHnXm71
Codes and data available at:
https://t.co/tt5jyR3eN4
It shows how to account for the location of cities and to compare alternative models beyond least-square fitting.
[1/3] https://t.co/UUY6lzBfju](https://pbs.twimg.com/media/EbZ-Ff0UMAEquD7.jpg)