We are back again :) After three weeks of quiet building.
Introducing Genesis World 1.0, our latest simulation platform, the second release in our full-stack suite. Open-sourced.
Robotics is still bottlenecked by the 1× speed of the physical world. Every model, checkpoint, and data recipe eventually needs to be tested on physical hardware, slowly, expensively, and with limited coverage.
One hour in reality can become 100 days in simulation. That is how robotics model iteration moves from a wall-clock bottleneck to a compute problem.
To make this work, simulation has to be both fast and trustworthy.
Over the past year, we rebuilt the entire stack: a GPU-accelerated cross-platform compiler, penetration-free multi-physics contact solvers, unified rigid and deformable physics, and a photo-realistic renderer purpose-built for physical AI applications.
We built Nyx, a high-performance path-traced rendering engine for robotics application.
Genesis World 1.0 achieves near realtime performance with our latest development for penetration-free IPC solver, supporting various types of deformables beyond rigid bodies. It supports contact-rich, dexterous manipulation simulation across different embodiments: unitree, sharpa, wuji, genesis hand and various types of grippers.
Under the hood is Quadrants, our effort in pushing forward cross-platform GPU-accelerated computation. Quadrants started as a fork of Taichi, and we rebuilt most of the critical parts for optimizing simulation workloads, giving 10x faster launch time and up to 4.6x runtime performance compared to the initial Genesis release.
Together, they bring us to an unprecedentedly low sim-to-real gap, enabling zero-shot real-to-sim model evaluation and much faster iteration of GENE.
All available today.
Genesis World 1.0: https://t.co/aknCM3eqws
Quadrants: https://t.co/uXqPNI4cb6
Nyx: https://t.co/R8j0djqGnV
Since @chaidosa asked about shell sim — quick extension of #RigidFormer to non-rigid bodies/thin shells (by replacing differentiable Kabsch alignment with a blending module).
Each thin shell becomes 8 "patches" (as new object-level tokens) with 4 anchors.
The video contains results on the eval set. Blended viz comes from RBF skinning; final dynamics = RBF skinning + a residual neural displacement; didn't push neural skinning much.
Full neural dynamics results: https://t.co/7yt9ATdVw3
Here are more results from #RigidFormer: predicting physical dynamics with purely neural simulators — an attempt to learn physical dynamics in a scalable manner.
🤖 1) Controllable Articulated Body Simulation — More Results
Additional Unitree G1 humanoid rollouts under controlled motion. Each sample uses a different initial state and control signal (direction and velocity).
🏺 2) Object Fragmentation
Simulating the cracking and fragmentation process of objects. Thanks @zzigakovacic for suggesting this experiment!
🎬 3) Combining Rigidformer with Diffusion-as-Shader for controllable video generation.
Note: the meshes shown here are only for visualization — the network takes point clouds as input and predicts the updated state of each point.
Introducing ✨RigidFormer: Learning Rigid Dynamics with Transformers - our attempt to scale learning-based physical dynamics with Transformers.
RigidFormer learns rigid dynamics with Transformers. It is a mesh-free, object-centric Transformer for multi-object rigid-body contact dynamics from point clouds.
Learning physics with purely neural simulators, without relying on traditional physics engines, is an important and widely studied problem. Prior SOTA methods often use graph neural networks for accuracy and generalization, but still struggle with efficient, high-fidelity simulation at scale.
RigidFormer uses only point inputs, matches or outperforms mesh-based baselines on standard benchmarks, runs much faster, generalizes across point resolutions and datasets, and scales to 200+ objects. We also show a preliminary extension to command-conditioned articulated bodies by treating body parts as interacting object-level components.
RigidFormer is mesh-free: it does not require mesh connectivity, SDFs, or vertex-level message passing, making it well-suited for point-cloud observations and scalable simulation.
This architecture can also be adapted to learn soft-body dynamics by replacing the rigid-body module (differentiable Kabsch alignment).
🎬See our video for more details.
Many thanks to my amazing collaborators: Minghao Guo @GuoMh14, Haixu Wu @Haixu_Wu_1998, Doug Roble, Tuur Stuyck @TuurStuyck, and Wojciech Matusik @wojmatusik.
Project page: https://t.co/6TBaRPVEYo
Paper: https://t.co/3OQUSJSND3
Excited to share that our work NeuralActuator: Neural Actuation Modeling for Robot Dynamics and External Force Perception has been accepted to #RSS2026!
Your robot — even a low-cost one — can feel external forces without torque or tactile sensors.
TL;DR: NeuralActuator is a neural actuator model that jointly predicts 1️⃣torque to capture the nonlinear and time-varying current–to–torque relationship of low-cost servos, 2️⃣external contact forces (and force detection gates) for sensorless force perception, 3️⃣and motor conditions that indicate each motor’s operating regime.
Here is a fast-forward video clip ⬇️ We are also covering more robots like LeRobot-S101 and Franka Panda.
More details coming soon.
This January, I decided to give it a shot and wrote my first paper
Today, I am happy to share that it was accepted by #SIGGRAPH2026
SAD is a differentiable image representation with soft, anisotropic partitioning, with up to 20x faster encoding time🧵
https://t.co/qhzxVZUvZ2
SAD: Soft Anisotropic Diagrams for Differentiable Image Representation has been accepted by #SIGGRAPH2026
Check it out, and huge congrats to Lucky! @Luckyballa#SAD represents an image as a soft, anisotropic, differentiable diagram over learnable sites. Each pixel is modeled as a softmax blend over its top-K nearby sites under a site-dependent distance, yielding a differentiable partition of unity with explicit ownership and content-aligned boundaries. A GPU-friendly top-K propagation scheme keeps the cost constant per pixel, enabling fast fitting at matched or better quality.
Classical geometric structures can still inspire fresh perspectives in modern visual computing.
Voronoi and Power diagrams have long been elegant tools for 3D shape analysis, reconstruction, and geometric reasoning; here, related diagram ideas, with connections to Apollonius-style diagrams, are explored for image representations.
Homepage: https://t.co/9woOAGRBPp
arXiv: https://t.co/yAIiplhDN5
#SIGGRAPH2026 #SIGGRAPH #CV #Vision #Graphics #CG
Excited to share our work, Know3D, which connects LLMs' reasoning ability and knowledge to 3D generative models. This increases the controllability and plausibility of unseen parts in the generated 3D shapes.
Paper: https://t.co/qPi4Pmkzgg
Project page: https://t.co/nHnP5O5NWy
Happy to share our work, PartSAM, which is a promptable 3D part segmentation model trained directly on large-scale 3D data. Inference codes and the pre-trained model are released!
Code: https://t.co/KaAGlAjj5E
Project page: https://t.co/PTz1slIqba
Paper: https://t.co/XSSWelFyVm
Excited to share Track4World, feedforward 3D tracking of all pixels in the world-centric coordinate system. Code has been released, and welcome to try it!
Homepage: https://t.co/OIiaEl8KJP
Code: https://t.co/VgLAkCLPCZ
Paper: https://t.co/bCPEVFaQUW
We present EgoReAct: Real-time 3D human reaction generation from streaming egocentric video.
🌟Reacting to streaming egocentric video is something humans do every day. We hope EgoReAct makes human motion more human-like.
🔎 What we found: existing ego-reaction data can be spatially inconsistent (e.g., moving reactions paired with fixed-camera videos), which breaks 3D grounding.
📷 What we built: HRD, a spatially aligned egocentric video–reaction dataset (3,500 pairs, 32 categories), plus a spatially aligned ViMo fix for fair evaluation. (Instead of collecting expensive ground-truth motion, we employ VDM to generate the egocentric videos.)
👁️⚡🏃 Our simple yet effective pipeline: motion tokenization for compact discrete codes + an autoregressive Transformer for online, strictly-causal generation. Metric depth and head dynamics further improve 3D spatial consistency.
Project Page: https://t.co/ITQhxS5jcI
ArXiv: https://t.co/jQSxvSw0MX
#HumanMotion #EgocentricVision #3D #ARVR #Animation #AIGC #DeepLearning #GenerativeAI #Graphics #ComputerVision #Motion
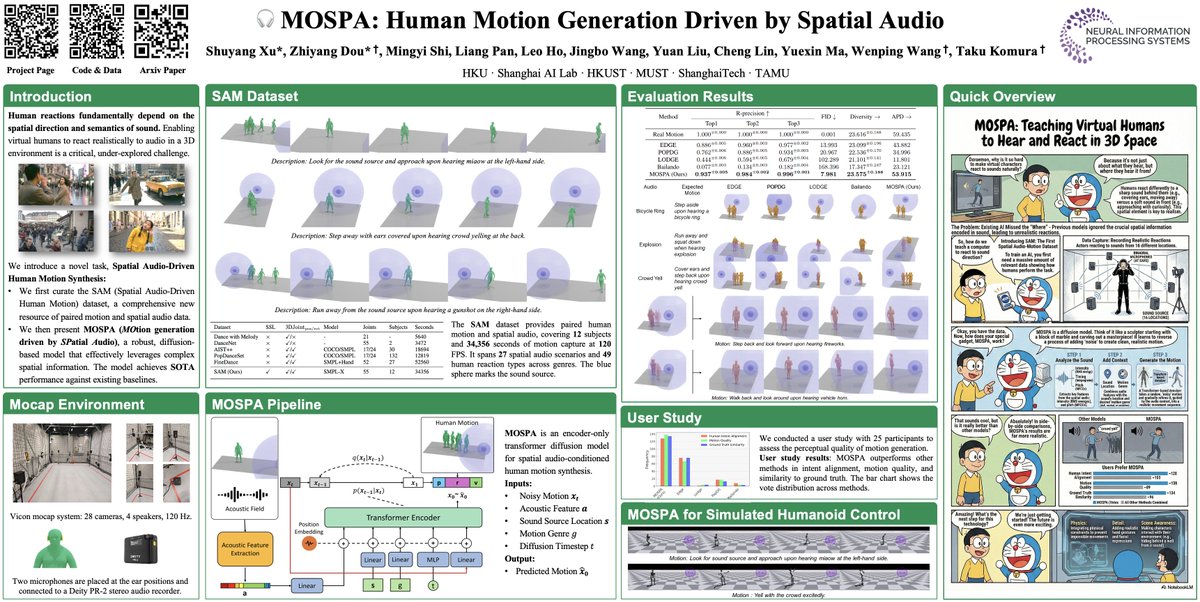
Please check out paper #MOSPA "🎧Human Motion Generation Driven by Spatial Audio” at #NeurIPS2025 (🌟Spotlight)!
😊We have released our dataset and models : )
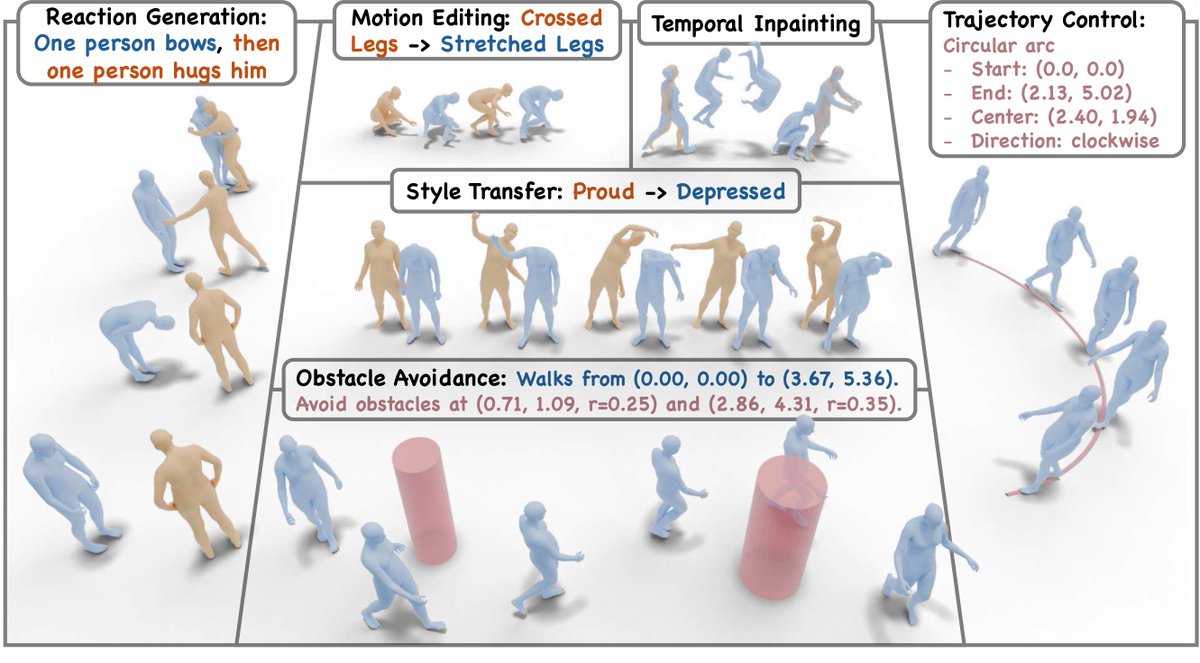
💡The paper tackles the challenge of spatial-audio-driven human motion generation, enabling virtual humans to respond dynamically and realistically to diverse spatial sounds — not just “what” is sounding, but also “where” and “how” it sounds in space.
💡We introduce SAM, the first comprehensive Spatial Audio-Driven Human Motion dataset, with diverse spatial audio scenarios and high-quality 3D motion pairs, providing a solid benchmark for studying human motion conditioned on spatial audio.
💡Building on this, MOSPA is a diffusion-based generative framework that fuses semantic and spatial features of the audio to synthesize diverse, realistic motions aligned with spatial audio cues, achieving state-of-the-art performance on this new task and offering a strong baseline for future research.
If you work on virtual humans, spatial audio, XR, or humanoid / embodied control, this can be a good motion skill learning source.
Please come meet the team at our #NeurIPS2025 San Diego Spotlight poster!
📍 Exhibit Hall C,D,E — #4310
🕚 Fri, Dec 5 | 11 a.m.–2 p.m. PST
Homepage: https://t.co/qEGbJWOO3d
Paper: https://t.co/wMuCj7ODlp
Code and Data: https://t.co/TTs78cWVgD
#NeurIPS #NeurIPS2025 #MOSPA #motion #Animation #SpatialAudio #VirtualHuman #Robotics #Robot #AI #Deeplearning #GenerativeAI #AIGC
Please check out Chen (@chenwangcw) and Chuhao (@MorPhLingXD)’s work “PhysCtrl: Generative Physics for Controllable and Physics-Grounded Video Generation” today (Dec 3, 2025) at #NeurIPS2025!
🕚 11:00 AM – 2:00 PM PST
📍 Exhibit Hall C, D, E — Poster #4315