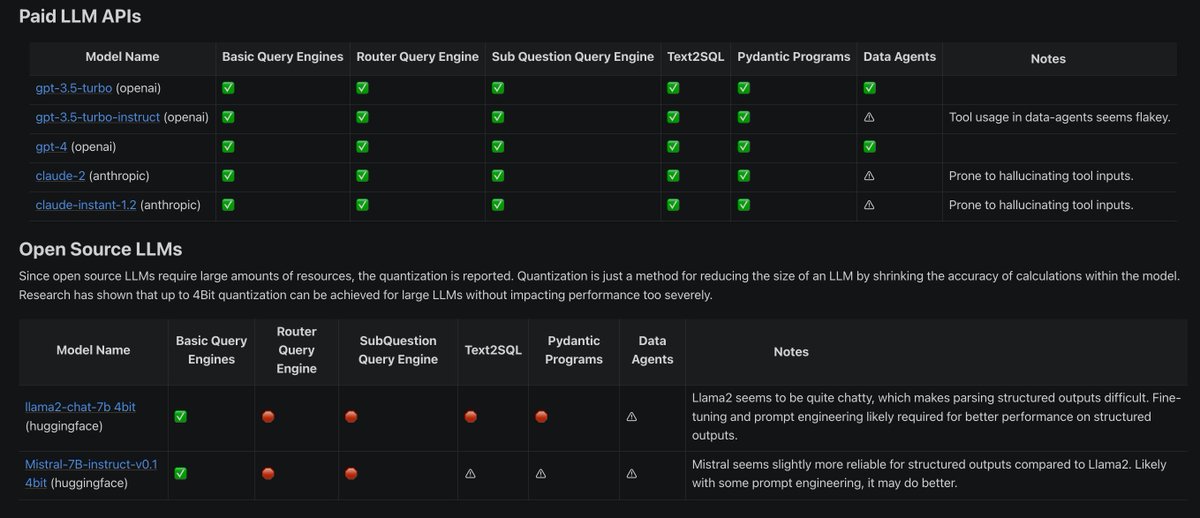
There’s a LOT of LLMs, but how do we know which ones work well from “simple” tasks (single prompt, top-k RAG) to “hard” tasks (advanced RAG, agents)?
We’re excited to launch a comprehensive survey of different LLMs performing simple to hard LLM/RAG/agent tasks 📝. For each model, learn which tasks work out-of-the-box, which would okay but need some prompt engineering, and which ones are unreliable.
Models used:
✅ OpenAI models (gpt-3.5-turbo, gpt-3.5-turbo-instruct, gpt-4)
✅ Anthropic models (claude-2, Claude-instant-2)
✅ llama2-chat-7b 4bit
✅ Mistral-7b
Tasks 🛠️: Basic RAG, routing, query planning, text-to-SQL, structured data extraction, agents!
Results/Notebooks 🧑🔬:
Docs page is here: https://t.co/8BZtmoy7Z7
We have comprehensive notebooks for each model
Contributions 🙌:
Have a model / task in mind? Anyone is welcome to contribute new LLMs to our docs, or modify an existing one! (e.g. if you think our defaults/prompts can be improved).
Credits:
Huge shoutout to our very own @LoganMarkewich for driving this entire effort ⚡️
https://t.co/otkdfgjVlW it's going to be a full house this thursday! only a few spots left for our inaugral #GenerativeAI meetup in #Toronto@forumventures
Forum Ventures & @Caden__AI are hosting a Generative AI Meetup to unravel insights, trends, and opportunities in the #GenAI landscape.
Register: https://t.co/LIr6nu0j7J
🗓 September 14th, 2023
🕕 6:00 PM - 9:00 PM (Fireside chat kicks off at 7 PM)
🏠 Toronto
Space is limited! 🎫