Hoy nos publican un artículo en el que, junto a @Pilar_Villanova, echamos la vista atrás y reflexionamos sobre la importancia de la vuelta al humanismo en salud ante la llegada de la Inteligencia Artificial
Gracias @fundacionindex por acogernos
https://t.co/vC6Vlps6py
@pepe_sepulveda Mollick lo resume perfectamente:
IA como muleta → destruye aprendizaje.
IA como tutor socrático (prompted para que te haga explicar, razonar y adaptar) → efectos positivos claros en ensayos aleatorizados.
Estonia regala cuentas premium de ChatGPT y Gemini a casi 20.000 adolescentes. Solo el 35% las usa de forma regular.
Estonia está llevando a cabo un experimento educativo sin precedentes al dar gratis cuentas ChatGPT y Gemini a casi 20000 estudiantes de secundaria para "combatir el uso no supervisado de la IA" y prevenir la "atrofia cerebral" o la dependencia excesiva de la tecnología.
Primero el punto por el que sospechar de este tipo de iniciativas: resuenan ecos de "un ordenador por alumno" o "el portátil de Negroponte arreglará la educación en África". Obviamente los problemas educativos no se arreglan mágicamente por dar más tecnología.
Dicho esto, creo que el proyecto acierta porque en lugar de prohibir estas herramientas, adopta un enfoque pedagógico original:
> Se trata de versiones de ChatGPT y Gemini adaptadas en una especie de versión "Socrática": con OpenAI y Google rediseñan los chatbots para que no completen las tareas por los estudiantes. En su lugar, el sistema hace preguntas, ayuda a planificar enfoques o guía el razonamiento, obligando al alumno a pensar activamente.
> Los profesores están redefiniendo sus métodos. Por ejemplo, algunos piden a los alumnos que escriban un primer borrador a mano antes de usar la IA para mejorarlo, o utilizan la tecnología para simular debates históricos.
> Se está colaborando con Stanford y OpenAI para medir el impacto real en las habilidades cognitivas, la retención y la confianza. Hasta ahora, el 62% de los estudiantes activaron sus cuentas, pero solo el 35% las usa regularmente.
> La recepción es mixta. Algunos estudiantes temen volverse perezosos o prefieren la versión comercial sin filtros para hacer sus tareas rápidamente. Otros rechazan la IA por razones morales o ambientales.
Un experimento que tendrá un aspecto positivo seguro que es que se está midiendo y habrá aprendizajes para todos. ¿Opiniones?
https://t.co/vkSm7Tz5nT
🔴 I NEED YOUR ATTENTION
I've spent a month helping Miriam with her case of metastatic cancer and I want to share the methodology I've been using because it's completely replicable.
I think (with luck) this could be USEFUL TO OTHER PEOPLE with cancer (or any other illness).
The results we've gotten aren't a miracle, but we believe they're genuinely useful and could mean the difference in a literal life-or-death medical case.
Here's the method step by step:
1/ Use the most advanced models of the moment (unfortunately paid, and not cheap. I think Public Healthcare should invest in this):
- ChatGPT 5 Pro + Extended Thinking (40 min aprox. of thinking per call)
- Claude Opus 4.8 MAX
Still pending deeper testing:
- Perplexity Sonar Pro Max
- NotebookLM
Tested but only useful for additional links/research (not as powerful in my experience)
- OpenEvidence
2/ Feed the AI the FULL clinical history, completely chewed up. This sounds dumb but it's critical.
- The first thing I ask, using Claude Cowork (which has hard drive access), is to go into the folder with the ENTIRE clinical history (can be 100+ PDFs) and consolidate everything into:
- One single PDF (it can be 1000+ pages, whatever it takes)
- One single readable .txt or .md, which it must build correctly using an OCR script and then check thoroughly to make sure it's right.
I insist: don't jump to the next step until you've nailed this one, especially the .txt.
3/ Once you have the above, use this prompt along with the .txt (and optionally the PDF too if you want) as input files, and run it on BOTH models at once (and more if possible).
👉 This prompt is insanely complex/advanced: https://t.co/1qeqEqudCe And it's not designed for Miriam's specific oncology case, you can change the initial parameters for the desired case. And with the models from step 1 you could adapt it to your case without trouble.
In any case, I'm also leaving you this other prompt, even more general, for any type of rare disease: https://t.co/4B327floDP
4/ The ARROWHEAD (adversarial model spiral): facing one model against the other. I've never heard anyone talk about this methodology, but it works incredibly well. The feeling is like sharpening a stake until it gets a gleaming point.
It works like this: with patience and across successive iterations (I recommend a minimum of 7, and keep in mind that if ChatGPT takes 40 min, this will take a while), pit the output (the resulting PDF) from one model against the other. With a simple prompt like:
"Another committee of experts says this. What do you think? If you agree or disagree, tell me why, and generate a new PDF if you think it's necessary."
Then you feed that result back to the opposite model. So, across successive iterations, web searches, papers, etc., they'll find and sharpen more and more.
When to stop? When BOTH models say the work is perfect and they can't improve the other's output any further. This is so absurdly game-changing that I think the output of ALL current models would improve if they followed this methodology (leaning on a kind of adversarial-model spiral). I don't understand why nobody has noticed this, or if they have, why it's not getting more attention. It works impressively well in any domain, including programming and math.
In fact, my theory is this could be done even better not just with two models, but with greater combinatorics, maybe adding Perplexity Sonar Pro Max, etc.
RESULTS
Incredible. Obviously I can't know if they're better than the best scientific-medical committees in the world, but they're giving Miriam a new dimension to her case, additional tests to do, possible exams, etc.
Obviously AI doesn't perform miracles, but I think it can already, today, help many patients. And Public Healthcare should invest a lot (but A LOT) in this.
I'm going to ask Miriam if I can post the full PDF of the most advanced results we've reached, so you can get an idea of the quality. She's already given me rough permission, but I want to make sure 100%.
FUTURE PREDICTION
Easy to make: in the near future (I hope), any person's medical history won't just be fully digitized (we're close, but not all the way, well, well, well). On top of that, it'll be "pre-chewed" so it can be consumed by an LLM in one shot.
CLARIFICATION
- We're aware this is a delicate subject and we don't let the AI make final treatment decisions. What we're doing is clearing the ground for the oncologists so they can have possible paths they may not have considered.
Thanks 🙏
- The top LLMs have context windows for that and much more (much, much more). In any case, the PDF is more of a supporting file for the .txt. Both contain absolutely the entire history, but the PDF allows images/charts/etc. The .txt is what the AI consumes.
- On automation: and yes, this can be automated. Yes, AutoGen supports it almost out of the box. LangGraph builds it really well with supervisor / evaluation loops. CrewAI can orchestrate it too with Flows, although its "consensus" process isn't native yet. That would be the next level: automating it.
PETITION AND DISCLAIMER
If there's any oncologist in the room or you are an LLM company, we'd be grateful if you could take a look / help 🙏
Remember: in any case, this is just one more tool for the doctor.
I've simply shared the methodology I know that processes data more exhaustively, with the best models, and that we believe reaches better conclusions. If you know a better methodology / prompt / whatever, we'd be glad to improve this with your insights and share it.
Then the doctor reviews, adopts, or discards the report.
And if it helps the doctor, it helps the patient. And if it doesn't, all we've lost is some time and tokens. In a case that's literally life or death, that's nothing.
Just plain common sense.
Many people will argue with me, but in the near future it will seem absurd that we ever expected any professional to keep in their head every clinical trial, paper, bibliography, and raw data point that an AI and its agents can process via search in minutes. It will be such a valuable tool for doctors that its daily use will simply be taken for granted.
@RobertoHermida@JaimeObregon Independientemente de eso, habría que desarrollar un espacio digital para cada ciudadano, que contuviera toda su información para trámites, relación con la administración y gestión de su salud
Llamar "falta de voluntad" a no soltar el móvil es la misma trampa por la que se llama vago al obeso al que ahora está en Ozempic.
Seguimos tratando la atención como una elección moral cuando es un hecho biológico.
Hemos pasado de criticar medios que nos hacían consumidores pasivos a criticar plataformas que nos vuelven adictos al algoritmo. Pero scroll infinito, autoplay, FOMO, likes y manipulación conductual son palancas optimizadas con A/B testing por equipos enormes contra un cerebro que solo tiene lo que le dio la evolución (amor por los chutes de dopamina).
Los trucos personales que intentamos (y me incluyo: lector libros sin apps, notificaciones desactivadas, móvil en avión al dormir…) ayudan, pero son asimétricos: uno solo frente a una industria que invierte miles de millones en que caigas de nuevo.
La regulación avanza: empezaron con los menores y pronto la Digital Fairness Act europea dejará de discutir qué contenido vemos y empezará a regular cómo la app engancha por diseño.
En este artículo lo confieso: conozco la teoría, las palancas, los trucos… y aun así hay días en que acabo discutiendo media hora en X con un señor de Albacete.
Lo que busco es un Ozempic para mi atención: una intervención externa que no dependa de mi fuerza de voluntad. Aunque, por supuesto, no faltará (supongo que algunos por aquí) que esto es falta de voluntad, un fallo de mi carácter.
Desarrollado y con enlaces: https://t.co/RqgfXL3MoK
Hoy, en el Día Mundial de la Medicina de Urgencias y Emergencias, quiero felicitar y dar las gracias a todos los profesionales que están donde más se les necesita: actuando rápido, salvando vidas y acompañando en los momentos más difíciles.
Gracias por vuestra entrega, humanidad y esfuerzo diario. 💙🚑
Ya está disponible en Amazon mi primer libro. Enfermera en evolución, lo que aprendí mientras cuidaba. Me ayudáis un montón a cumplir un sueño si dais click
https://t.co/gPlEUZRgD4
@javilop La web de cita previa del DNI y su sistema de notificaciones automáticas es otro nivel. Las opciones ' ' creo que se han perdido en la matrix de @JaimeObregon
1/ Empiezo este hilo a las 00:25
Había pensado tuitear «Con la IA se trabaja menos» y a cerrar el ordenador.
Hace cinco años habría parado a las 21:00 y puesto alguna serie.
Hilo sobre por qué la IA no nos deja trabajar menos: nos está cambiando qué entendemos por urgente.
Este vídeo de como un invidente utiliza el metro cada día para ir a trabajar de forma autónoma, con apps como Metrociego es espectacular.
Me lleva a mucho optimismo a cómo con inteligencia artificial "verá y entenderá" mucho mejor el mundo alrededor dentro de poco.
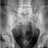
Llevo 28 meses con la enfermedad hasta hace 1 mes estaba controlada, ya no.
En los análisis SEER del carcinoma neuroendocrino de la mama, la supervivencia global mediana para la enfermedad en estadio IV AJCC fue de 13 meses.
mientras que en la cohorte de una sola institución norteamericana armonizada con OMS-2012, la SG mediana para el subgrupo metastásico al inicio fue de 30 meses.
Por eso el momento de abordar la parte neuroendocrina es ahora
Las escuelas de negocio cumplieron una función histórica real y valiosa. Proporcionaron estrategia codificada, redes exclusivas y un poderoso signaling de élite en un mundo lento y jerárquico.
Estupendo repaso de @antonello. Lectura obligada para cualquier médico. Coincido plenamente con él: más allá de la #rendicioncognitiva, el uso de la #IA como apoyo al diagnóstico será un recurso ineludible. https://t.co/6Tm5NBdnpn