Most AI doesn't know Amazon.
We just changed that.
Built @AlkemiAI so you can ask Claude things like "who's beating my brand on Amazon?" and get real data back. https://t.co/yAoT5Fu91W
Most Amazon operators spend the week reporting the news. Always a step behind.
So we built Alkemi: 13 Amazon Skills you run by just asking in Claude or ChatGPT.
The AI is the easy part. Unifying the data is what makes it work. https://t.co/yievs90PG8
AI doesn't need more Amazon dashboards. It needs the data, and the context to act on it.
That's the bet behind Alkemi's Amazon Skills.
Connect to Amazon expertise → https://t.co/yAoT5Fu91W
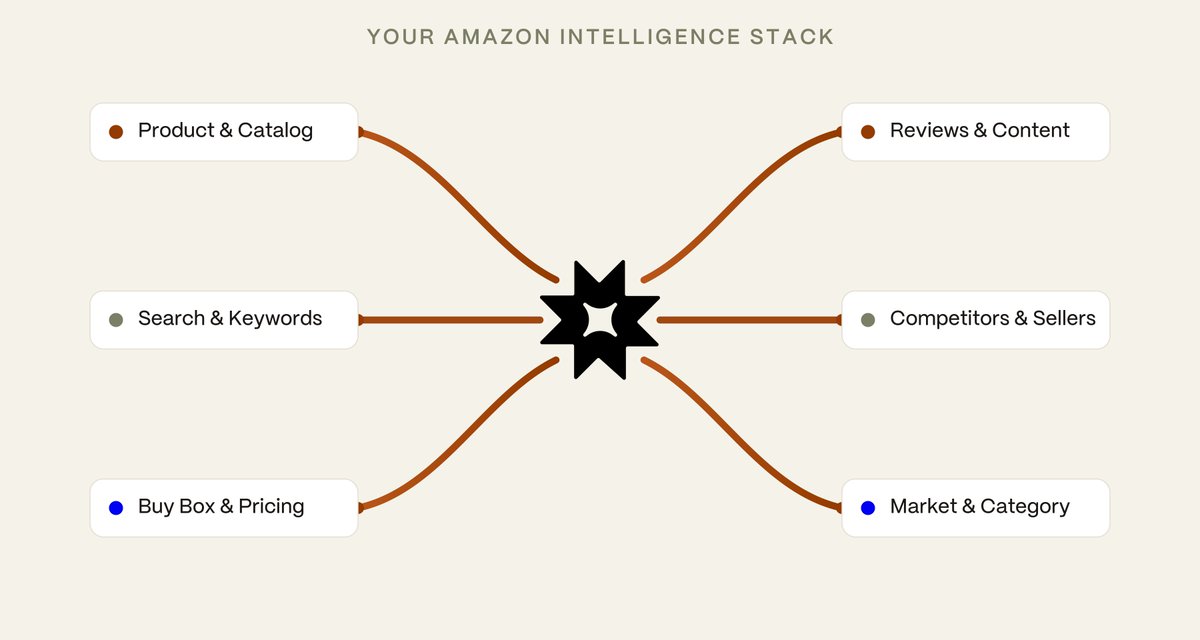
Real Amazon signals with the context to act on them.
Keyword rank, share of voice, sales velocity, competitor share, without logging into a dashboard. Just the answer.
Alkemi's Amazon Skills plug real Amazon expertise into Claude or ChatGPT → https://t.co/U3UpYonmN1
We started Alkemi to remove the gap between data and decisions.
Teams work in Slack.
Their data doesn’t.
We’re fixing that.
Live on @ProductHunt
https://t.co/y2LqwoB0F1
Teams work in Slack.
Their data doesn’t.
The Alkemi Slack Agent brings answers to the moment of decision — your AI data teammate.
Live today on @ProductHunt 🚀
We’d love your feedback and support:
https://t.co/PkL7X9wFua
Today we launch the @AlkemiAI Slack Agent — your AI data teammate in Slack 🚀
Decisions happen in Slack.
Data doesn’t.
We’re closing that gap and bringing answers to the moment of decision.
Ask. Get answers. Decide.
Now live on @ProductHunt
https://t.co/WTSM2XodsH
Another big launch at @AlkemiAI today with the release of our Data Provider experience. The high-value data these firms sell will allow AI agents to address a wave of new AI use cases. Today, we are taking a big step towards unlocking that supply. https://t.co/Zlrl8wAQkg
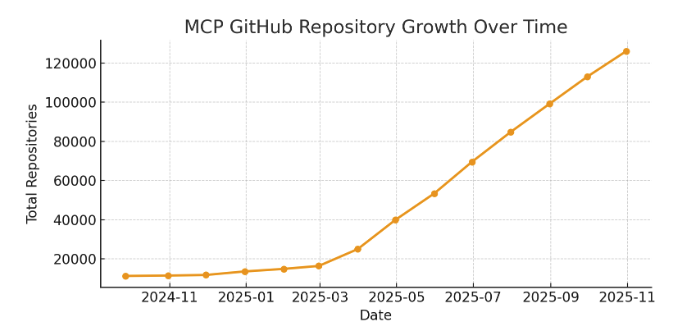
MCP adoption is exploding.
In the past 7 months, GitHub repos mentioning “MCP” have grown 5×! It seems devs everywhere are building new servers, tools, and clients.
That’s a lot of code.
Make your data portable across ChatGPT, Claude, n8n, and any AI client—without exposing it.
Query terabytes from Snowflake, BigQuery, Databricks, and more—all securely, all in natural language.
Powered by Alkemi’s MCP Server https://t.co/BByy7ZTT6P
Exciting launch for Alkemi!
DataLab is the AI thinking partner powered by your data!
Don't let BI backlogs stall critical decisions.
What if you could ask your data questions in plain English — and get instant answers?
👉 Try it free: https://t.co/Qx0oz8cBD2
Tired of BI backlogs stalling critical decisions?
What if you could just ask your data — and trust the answer?
Meet DataLab, your AI thinking partner for instant insights.
Ask in plain English. Get answers in seconds.
🚀 Try it free → https://t.co/qVBvvCtiml
The modern AI stack has democratized access to pre-trained models, orchestration tools, & RAG. Millions of devs are building AI apps, empowered with the picks & shovels to stake their claim on a $200B AI market. But, barriers to accessing relevant data throttles innovation.
Data providers want to sell the data AI developers need. So, why hasn’t a thriving AI data market emerged? At its core, this is a problem of product-market fit. https://t.co/bLMu3EcXcI
@pmddomingos If factual information is required to resolve a user’s query, an LLM can’t provide an accurate response without access to those facts and the ability to distinguish facts from fiction.
No matter how powerful the reasoning of future AI models, if factual information is required to resolve a user’s query, the model can’t provide an accurate response without access to those facts. Model reasoning and factual recall are often conflated as intelligence, but improving the latter will require augmenting the LLM with new infrastructure and data partnerships.
One hard problem with AI right now is retrieval augmented generation (RAG) with wide-ranging heterogeneous information. A common architecture pattern in AI right now is that you connect up a large amount of data to an AI model, and when a user or machine sends in a query, you find the best matches from the underlying data set and then send that information to the AI model to answer the user's prompt. This is a very efficient way to be able to have an AI access information that is frequently changing (like web data) or potentially wouldn't be appropriate to have in an underlying training set of the AI model (like private corporate data).
This is a relatively fundamental and breakthrough architecture in AI, but there's a small catch. The AI's answer is only as good as the underlying information that you serve it in the prompt. And because the user isn't the one giving it the data, but instead a computer, you're at the mercy of how good that computer is at finding the right information to give the AI to answer the question. Which means, of course, you're also at the mercy of how good, accurate, up-to-date, and authoritative your underlying information is that you're feeding the AI model in the prompt.
Let's take a very basic example. Say you ask an AI that's connected to the web, "who are the top movie studio heads right now?". The issue is that there's not many authorative webpages on the internet that are the singular list of movie studio heads *right now* (or for any esoteric topic for that matter). A human would do lots of browsing, compare answers between sites, check corporate webpages, and more just to decide an answer. With AI, we're often at the mercy of a search engine going across the web and trying to find various articles and determining their accuracy and authoritativeness to try and eventually find enough information to produce an answer. Chances are some of those articles are out of date within a year or even were wrong to begin with, but the AI has no reason to know that -- so it will still use that information in its underlying prompt, and lo and behold it can produce an inaccurate answer.
The challenge also occurs on smaller data sets, as well. Imagine an AI assistant that has access to all of your documents, emails, and calendar, and you ask a simple question like "what was last quarter's revenue?" Not only does the AI have to figure out how to assess the information that is tied specifically to "last quarter", but also it has to wrangle the possibly conflicting information in your underlying data. You may have an email that had early -but not verified- revenue results, that are different from draft documents that the finance team created, which are different yet again from the final documents with the results. AI is still quite constrained in its "intelligence" to be able to triage these conflicting answers *today* to produce an accurate result, no matter how confident it sounds.
There are some awesome efforts to try and solve this problem, and it's clear this will continue to become less and less of an issue. With Box AI, to address this challenge, we just launched a new feature in beta called Box Hubs. With Hubs, users pre-curate content that is the "authoritative" source of truth for particular topics and information -- say for instance, Sales materials, HR documents, or R&D files. When you ask an AI question in a Hub, you are aiming that question at the most up-to-date and relevant information for that topic. In our early testing and rolling out it dramatically reduces the issue of getting confusing data, and delivers more accurate answers.
I'm excited to see many other breakthroughs in this space -- from better ways of organizing the web over time to AI agents that can fully browse the web and do more of the "research" that a human would when finding information.
Who's sending traffic to the open web?
Google? Social media? And are the major platforms sending less traffic than they did a year ago?
These are frustrating questions. But thanks to our partnership with Datos, we can finally dive in.
https://t.co/DLmipvZj5b
I 100% agree with @aleksizy that DaaS hasn't found a market with LLMs due to a misalignment in value. DaaS emphasizes the value of marginal data points, while LLMs benefit more from the volume of historical data. However, the value chain has expanded with the emerging paradigm of vertical AI apps using retrieval frameworks and pre-trained LLMs. Adding this link to the value chain moves the responsibility for generating high-veracity responses, and thus, the value of good data truth sets downstream to the AI app. At the AI app layer, the DaaS buyer and seller are aligned on the value of marginal data points.
@auren Has a significant market for DaaS and AI materialized beyond edge cases that don't involve established DaaS vendors (e.g. OpenAI and Reddit)? Can you point to any market figures on the subject? Appreciate any wisdom the DaaS Guru can share.