Here are 5 distance metrics in vector search.
But how do you choose the right one?
• L1 (Manhattan): sum of absolute differences, exact kNN only with no HNSW support
• L2 (Euclidean): straight-line distance, the safe default for most models
• Cosine similarity: angle between vectors, magnitude ignored
• Dot product: same ranking as cosine on normalized vectors, less compute
• Max inner product: dot product without the normalization constraint
Most teams default to cosine and move on. That works until your model outputs non-normalized vectors, and suddenly dot product or max inner product is the better fit.
Scoring formulas and config details in the blog.
- Reindex survives graceful node shutdowns
- PIT replaces scroll for source iteration
- Reindex-specific APIs for list, status, cancel, rethrottle
- Reindex-from-remote GA in Serverless
Available now in Serverless. Hosted and self-managed coming soon.
Full writeup in the blog: https://t.co/FFmBep4mjt
🧵Your reindex dies halfway through a rolling upgrade. Where did it leave off?
Reindex just got more reliable and more manageable: task relocation, PIT over scroll, dedicated APIs, and reindex-from-remote GA in Serverless.
New reindex-specific management APIs, relocation-aware:
GET /_reindex (list)
GET /_reindex/{id} (status)
POST /_reindex/{id}/_cancel
POST /_reindex/{id}/_rethrottle
Two new privileges too: monitor_reindex and manage_reindex. Least-privilege without handing out manage or superuser.
The same MCP App ships an Investigation Workflow that runs root cause analysis automatically when a Kubernetes alert fires. Open the alert, find the diagnosis already done.
Full walkthrough: https://t.co/1SacODRDyu
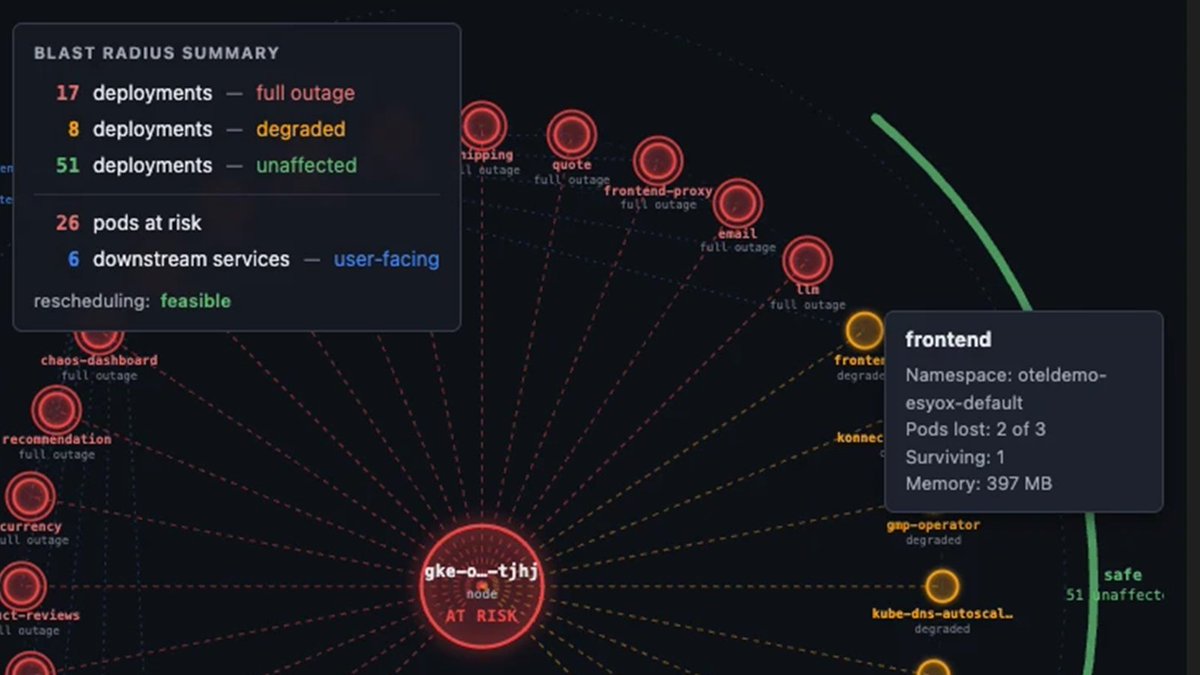
What happens to the cluster if this node goes down?
That question used to mean a half-hour with a kubectl session, a topology diagram, and someone counting replicas in their head.
Now it's one of six tools in the Observability MCP App. Ask in Claude or VS Code, get the full impact map back inline: full-outage deployments, degraded ones, pods at risk, downstream user-facing services, whether anything can reschedule.
Investigation moved into the chat interface. The diagram came with it.
Attackers are compressing timelines from hours to minutes. Most SOCs are still stitching context together across three tabs and a ticket.
On June 17, we're showing the full lifecycle, from first alert to staged response, with AI agents handling triage, enrichment, and investigation live. Prizes too.
Save your seat: https://t.co/1Iihl0rXa8
The out-of-the-box dashboards, SLOs, and ML jobs are still there for when you want to dig in by hand.
This doesn't replace your workflow. It gets you to the right starting point faster.
MCP app repo: https://t.co/v7jqcpPRo0
🧵 K8s alert fires while you're dreaming of electric sheep.
Pods, then nodes, then logs, then metrics.
By the time you've reconstructed context, the clock's already run.
Elastic 9.4 shipped two things that change this workflow:
A Kubernetes observability MCP app, and agentic investigation in Kibana.
Inside Kibana, an alert can trigger an agentic investigation automatically.
It returns a root-cause hypothesis, the blast radius (which services, pods, and namespaces are affected), the evidence it used, and suggested next steps.
Before you open a single dashboard.
🧵 Every Elasticsearch app starts with the same guesswork: BM25, semantic, or hybrid search.
You pick a mapping strategy before you understand your own data. Three weeks later, you're reworking it.
9.4 ships an onboarding assistant that inspects your data first, then recommends the approach.
It runs in Cursor, Claude Code, and Kibana.
Then it builds the retrieval query.
One query string across both fields. Elasticsearch reads the mappings, groups lexical vs semantic automatically, and blends with RRF.
No manual sub-retrievers. No score-normalization tuning.