@theo I have been using it all day and have not hit any limits. I had crazy token usage today.
@theo It seems like you are on an agenda against Claude.
@itsEmZee_ I think if EMRs open up all the FHIR APIs, read/write technically you can build that harness with memory outside of the EHR and give it a lot of tools
Quick demo of Byaan.
It’s a self-hosted AI data analyst I built for asking questions over Postgres, Mongo, MySQL, SQLite, ODBC, and files.
The main idea: it should remember your schema notes, metric definitions, and corrections instead of starting from zero every chat.
The github url is in comments
@ashpreetbedi very cool. couple of questions
- does it learns from the codebase as well. codebase could have lot of data flow learnings
- do you guys integrate with other knowledge soruces such as google docs, linear, notion or otheres
- where does it present the learnings to approve or deny?
Your AI writes perfect SQL. Also completely wrong SQL.
The problem is not the model. It is that nobody has figured out how to teach AI what the data actually means.
Wrote about the tribal knowledge gap, why semantic layers are not enough, and what a real fix looks like.
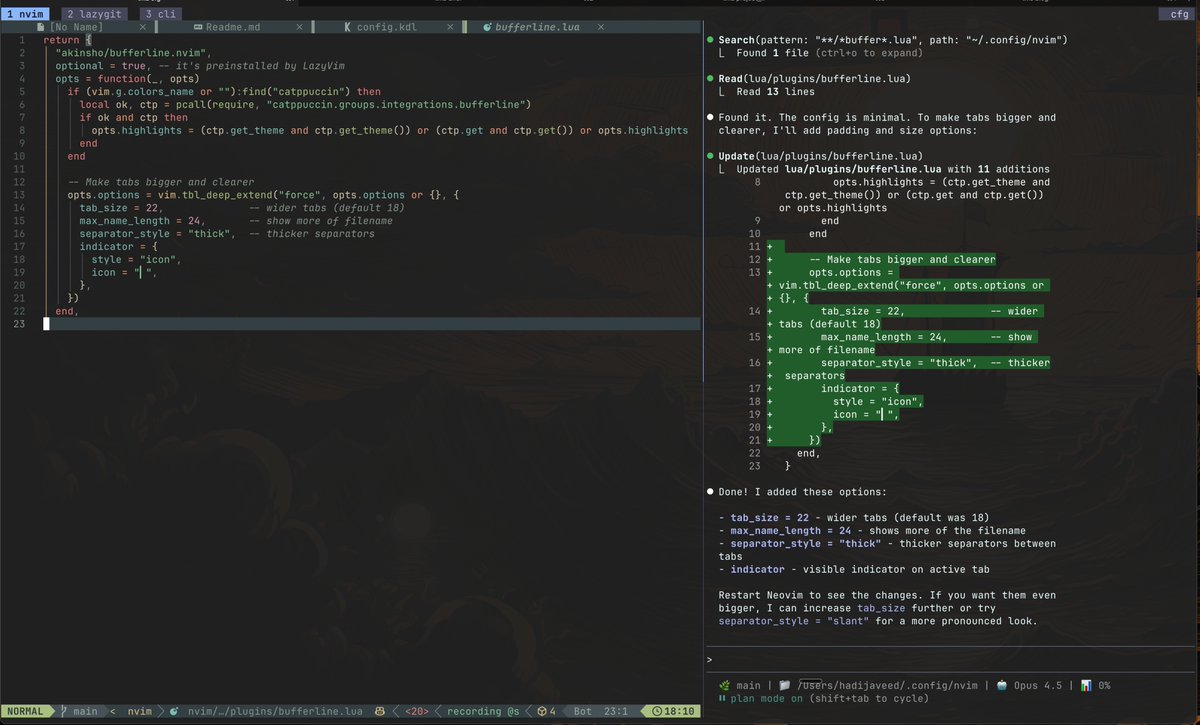
Six months into using Claude Code full-time. My tmux splits have replaced every IDE panel I used to depend on.
The context stays in the terminal, the history stays in git, and the AI sees exactly what I see. No GUI abstraction layer eating tokens.
@dabit3@DevinAI how to Devin decide to build new features? is there a way to schedule a task where Devin do research and tell you what needs to be built?
Spider benchmark says text-to-SQL is 86% accurate.
Spider 2.0, which uses real enterprise schemas, says 6%.
That is not a rounding error. That is the difference between a demo and production.
Most AI data tools are optimized for the demo.
this isn’t about AI replacing doctors.
It’s about access.
Patients are already using AI as their first touchpoint. Consumer-driven healthcare is here.
Health systems need to meet patients where they are through technology
This isn’t an edge case. From anonymized U.S. ChatGPT data, we are seeing:
• ~2M weekly messages on health insurance
• ~600K weekly messages from people living in “hospital deserts” (30 min drive to nearest hospital)
• 7 out of 10 msgs happen outside clinic hours