i've been waiting a while to announce this one:
@JoeSciarrino is joining Supabase
He previous co-founded Hydra and helped to develop pg_duckdb, which is powered by DuckDB
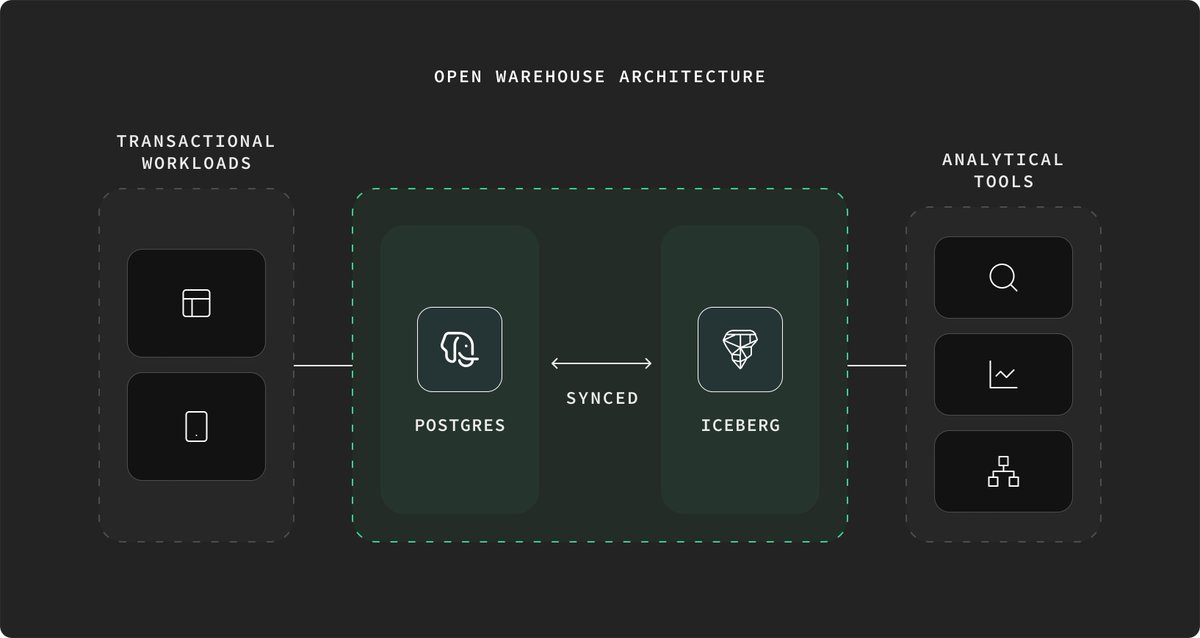
Joe will oversee our Open Warehouse Architecture initiative and help push our Postgres + Analytics roadmap forward.
All of the Hydra code will stay open source. We'll take over maintenance of pg_duckdb and work in the open as we develop the Open Warehouse Architecture and the broader Postgres + Analytics vision.
Congrats to the @neondatabase team on their acquisition by @databricks. It’s clear that serverless and open source data was not just what developers wanted, but also the ideal foundation for coding agents to build on.
Agents like @v0 favor infrastructure that’s well represented in the training (Postgres: check). Not re-inventing the wheel and bringing new query languages to market was rewarded.
On the other hand, agents and modern dev platforms like @vercel need agility. Databases need to be created instantly when you prompt or create from a template. During the vibe coding or preview process, the database is needed, but then not accessed for a while.
At rest, a Neon database is inexpensive S3 objects. Modernizing the storage layer, while retaining the “frontend” APIs that agents and devs are familiar with is a winning combination.
It’s great to see new players in the Postgres space like https://t.co/QR9Mw4BKzv, https://t.co/BDjniVkUQH, https://t.co/zjjtxnz4aU innovating in the storage infrastructure as well. @Supabase recently announced the acquisition of https://t.co/xNJospTeCl to pursue decoupled storage and compute, while @Prisma is bringing a Unikernel-based approach for instant db boots with https://t.co/6KPUinWmtQ.
It’s clear now that Postgres has become the Linux of the database world, and the de-facto choice of developers, enterprises, and importantly, agents.
https://t.co/IX3JBhHwo6
Excellent video tutorial by @ByteGradCom on the ultimate next.js dahboard for web analytics. Wesley uses serverless analytics with Hydra, @prisma, @shadcn, with server-side events (SSE).
Step 4: Restart Postgres and
> create extension pg_duckdb
✅Done ✅
Next, to use serverless analytics on Postgres check out the QuickStart at https://t.co/pIJWFK5wpc
⚙️ Introducing Hydra Bare Metal ⚙️
Deploy serverless analytics anywhere in minutes.
- Realtime analytics on existing Postgres instances
- Unparalleled infrastructure control
- Best price:performance of any analytics database on AWS, GCP, and Azure.
Step 3: Add configuration for Hydra to your Postgres config file at: /etc/postgresql/{version}/main/postgresql.conf
In settings add:
shared_preload_libraries = 'pg_duckdb'
duckdb.hydra_token = 'paste token from https://t.co/TlGmjMHAAv'
Grab an access token for free from the URL above and paste it in
Last up: ClickHouse
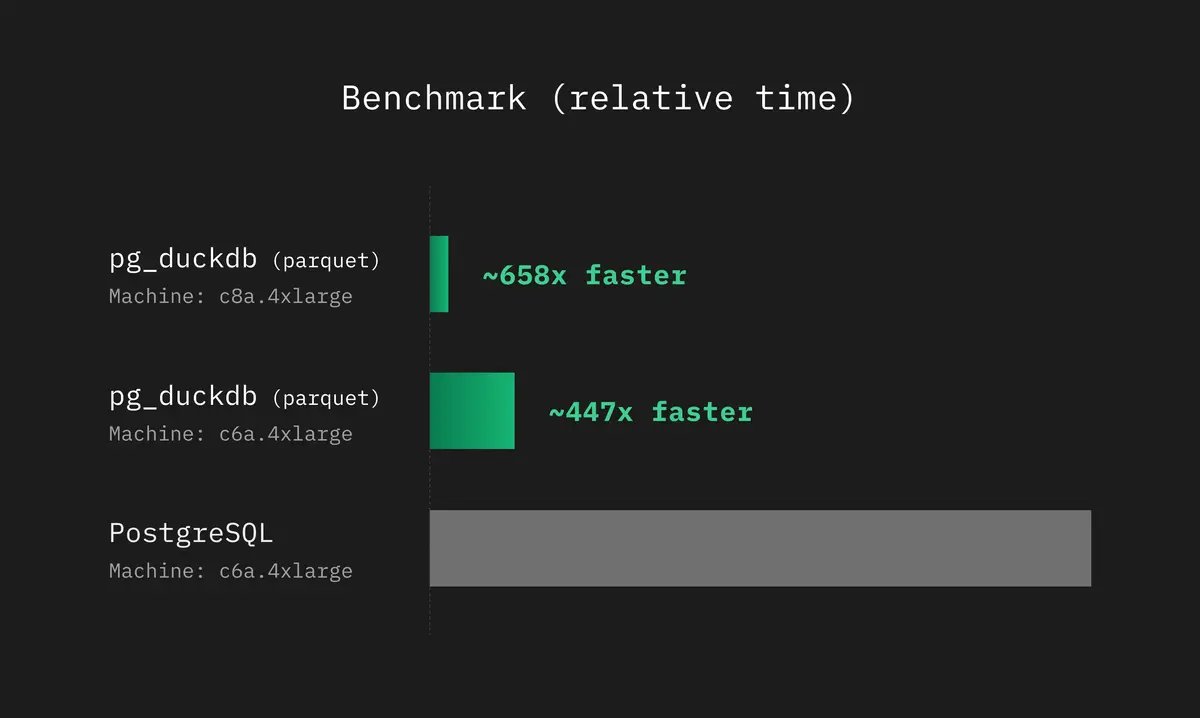
2 Entries - Hydra is 28% faster than ClickHouse c6a.4XL and 75% slower than ClickHouse c6a.metal. Interestingly, Hydra is 22% faster than c6a.metal on cold run.
hot run: https://t.co/83ZmjlT17Q
cold run: https://t.co/LDmfRL5BW5
Good show! Hydra officially turns Postgres into a true analytics DB. btw how's ClickHouse at OLTP?🤝
Next up: Snowflake
8 Entries (XS -> 128x4XL) Hydra is 7X faster than Snowflake at best, 62% faster at worst case.
https://t.co/amjv7CwK31
Raise your hand if you've ever been victimized by a monthly Snowflake bill 🙋. "Just ...use... Postgres"