1/6 Diffusion models are scaling up, but deploying a massive, monolithic network uniformly across the entire generative timeline is inherently inefficient.
Introducing Complexity-Balanced Splitting (CBS): a principled framework that allocates capacity exactly where needed!👇🧵
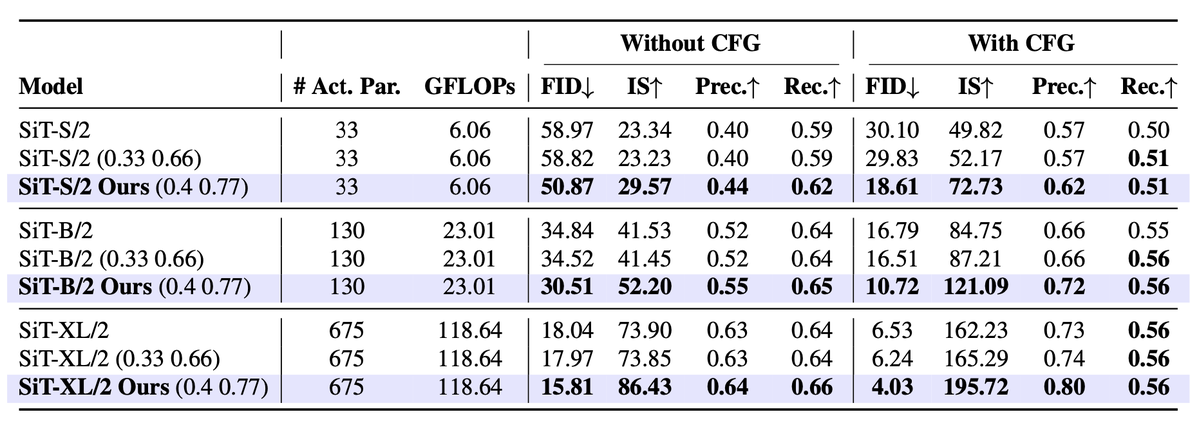
5/6 - Results 🏆
CBS improves FID across SiT, JiT, and UNet without adding per-step inference cost (FLOPs). On SiT-XL with Classifier-Free Guidance (CFG), CBS improves FID by ~35% relative to naive uniform partitioning!
Excited to share Colored Noise Sampling (CNS)!🎉
Instead of injecting white noise, our SDE sampler exploits the inherent spectral bias of diffusion models. We dynamically color the injected noise to focus on frequencies where details are missing, substantially improving FID.🧵1/9
We introduce 🌍GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens.🌍
Most feed-forward 3DGS methods still start from pixel, voxel, or dense view-aligned primitives.
We take a different route: align first, decode later. 🧵👇
We present DyPE, a framework for ultra high resolution image generation.
DyPE adjusts positional embeddings to evolve dynamically with the spectral progression of diffusion.
This lets pre-trained DiTs create images with 16M+ pixels without retraining or extra inference cost.
🧵👇
Regarding ICML ‘25: What’s the point of an “acknowledgment” button that just generates a generic message: “I confirm that I have read the author response and will update my review as necessary”? It gives reviewers a false sense of completion—checking a box instead of engaging.
@liyzhen2 Yes, and then during inference, given a condition c we sample a prior sample from the corresponding GMM mode, and transform it to a target data point using the flow network.
[1/8] Recent work has shown impressive Image-to-Video (I2V) generation results. However, accurately articulating multiple interacting objects and complex motions remains challenging. In our new work, we take a step toward addressing this challenge.
🎊 Excited to share our latest work: “DGD: Dynamic 3D Gaussians Distillation”! 🚀
To appear at #ECCV2024. DGD distills 2D semantic features into dynamic 3D Gaussians, enabling the reconstruction and semantic segmentation of dynamic objects in 3D using only a user click.
🔗 Project page: https://t.co/sTOEjhHIu6
📹 Segmentation and tracking of a deforming cookie and moving hands by our method, where we click on the cookie (“green”) and on the hands (“red”):