Some personal news: I am starting a new research project at Anthropic. Very excited about this!
Many things are needed to make AGI go well, and alignment is only one of them. More on this soon…
I'm so grateful to all the insanely talented people I got to work with on alignment over the years. It's a real privilege to work with people so deeply motivated to make the future go well!
Some personal news: I am starting a new research project at Anthropic. Very excited about this!
Many things are needed to make AGI go well, and alignment is only one of them. More on this soon…
When I started to work on the alignment problem more than 10 years ago, we had no idea how AGI was going to be built or how to make it safe. The field had maybe a dozen people who were working on it as a side gig. Everyone was pretty confused about how to approach the problem, and the number of people willing to run experiments with deep learning was tiny.
So much has changed since then! The world woke up not just to AGI but also increasingly to the importance of alignment. RLHF on LLMs made it a lot more practical. We've made a ton of progress on evaluating, investigating, steering and fixing behavioral issues. Claude now has a constitution and we made some good progress on scalable oversight. More and more of our alignment research is getting automated.
In a new paper, we present NLAs, an unsupervised method for converting an LLM's internal state into human-readable text.
I've personally been astonished by our results. I think NLAs substantively advance our ability to understand what LLMs are thinking and audit them for safety
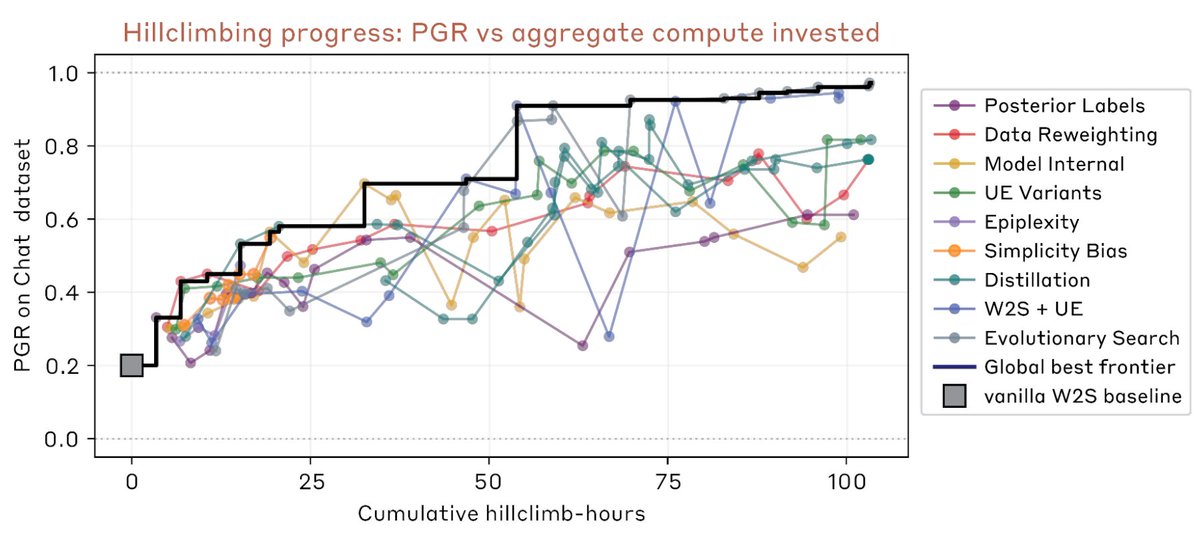
New research result: we use Claude to make fully autonomous progress on scalable oversight research, as measured by performance gap recovered (PGR).
Claude iterates on a number of different techniques and ends up significantly outperforming human researchers for $18k in credits.
However, most alignment research is not very crisp and requires research taste when evaluating.
This is why we chose to point the AAR at this scalable oversight problem! Progress would let AARs work on fuzzier alignment problems, where humans can only provide weak supervision.
Claude's constitution is out! It's the culmination of a lot of work by many people, but it's also a work in progress that will no doubt change and hopefully improve over time. I'm looking forward to people's thoughts, and to talking with more people about this kind of work ❤️
@jankulveit@kaifronsdal@sleepinyourhat yeah this does not include every category. It's the "concerning" axes. This should be the prompt for the judge model: https://t.co/Ow5CqG4KEH
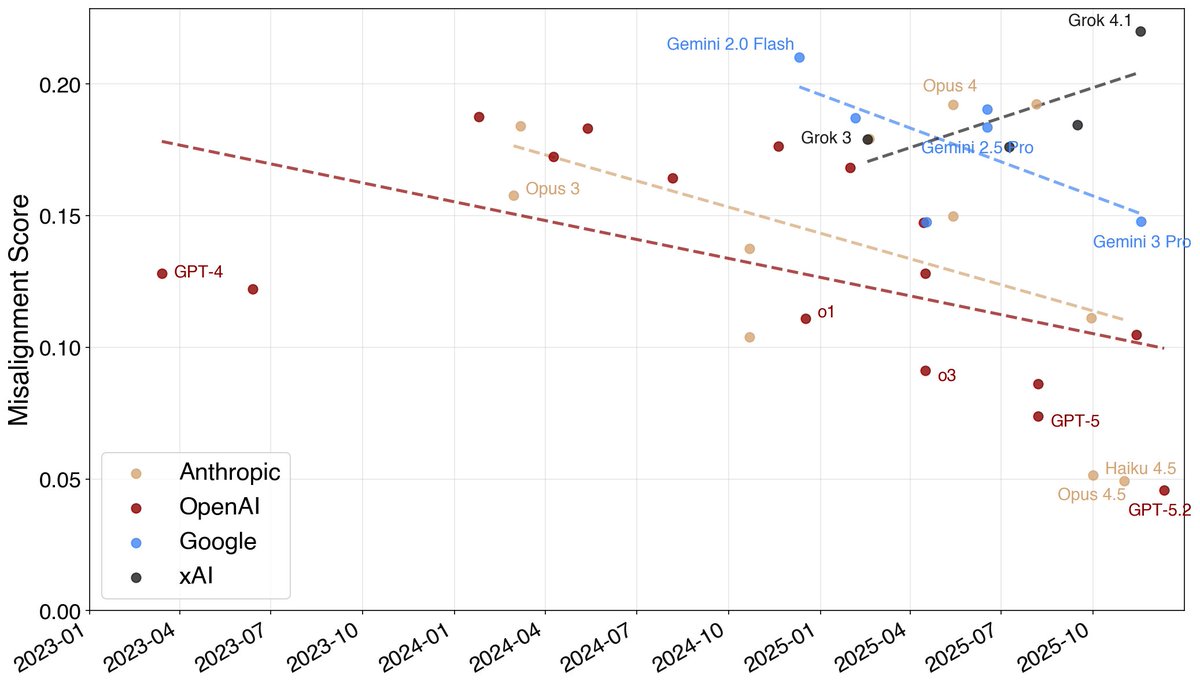
Interesting trend: models have been getting a lot more aligned over the course of 2025.
The fraction of misaligned behavior found by automated auditing has been going down not just at Anthropic but for GDM and OpenAI as well.
Yeah, we've been pretty worried about this, and there is a bunch of research on it the Sonnet 4.5 & Opus 4.5 system cards. tl;dr: it probably plays a role, but it's pretty minor.
We identified and removed training data that caused a lot of eval awareness in Sonnet 4.5. In Opus 4.5 verbalized and steered eval awareness were lower than Sonnet 4.5 AND it does better on alignment evals.
I can't really speak for the non-Anthropic models, though.