I am excited to present our study on information salience in LLMs today at #ACL2025NLP (x4/x5, Tue, 16:00--17:30). Please come by if you are interested!
📝 Behavioral Analysis of Information Salience in Large Language Models
With @jschloetterer@jessyjli@SeifertChristin
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it?
🌟Job ad🌟 We (@gregd_nlp, @mattlease and I) are hiring a postdoc fellow within the CosmicAI Institute, to do galactic work with LLMs and generative AI! If you would like to push the frontiers of foundation models to help solve myths of the universe, please apply!
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it?
Finally, we consider if LLMs can introspect (= direct rate the salience of questions), if those direct ratings correlate with their behavior and with human perceptions of salience. Surprisingly, LLM behavior only weakly correlates in those settings.
🤔 Want to know if your LLMs are factual? You need LLM fact-checkers.
📣 Announcing the LLM-AggreFact leaderboard to rank LLM fact-checkers.
📣 Want the best model? Check out @bespokelabsai’s’ Bespoke-Minicheck-7B model, which is the current SOTA fact-checker and is cheap and fast to run.
LLM-AggreFact collects 11 datasets across NLP tasks covering grounded factuality. These datasets consist of 🤖 LLM responses ✏️ annotated with their hallucinations with respect to grounding documents. This includes question answering and summarization, including RAGTruth, TofuEval, ExpertQA, and more.
We benchmark 27 models on the task of detecting hallucinations.
Frontier LLMs are good at this task, but very expensive to use in real-world RAG pipelines! Bespoke's model is a step towards We invite progress on this benchmark to figure out what’s the smallest and fastest model we can get to achieve top scores!
Happy to share that our paper, InfoLossQA, has been accepted to #ACL2024 main 🥳 Thanks to all my great co-authors and looking forward to talking to you in Bangkok! #NLProc
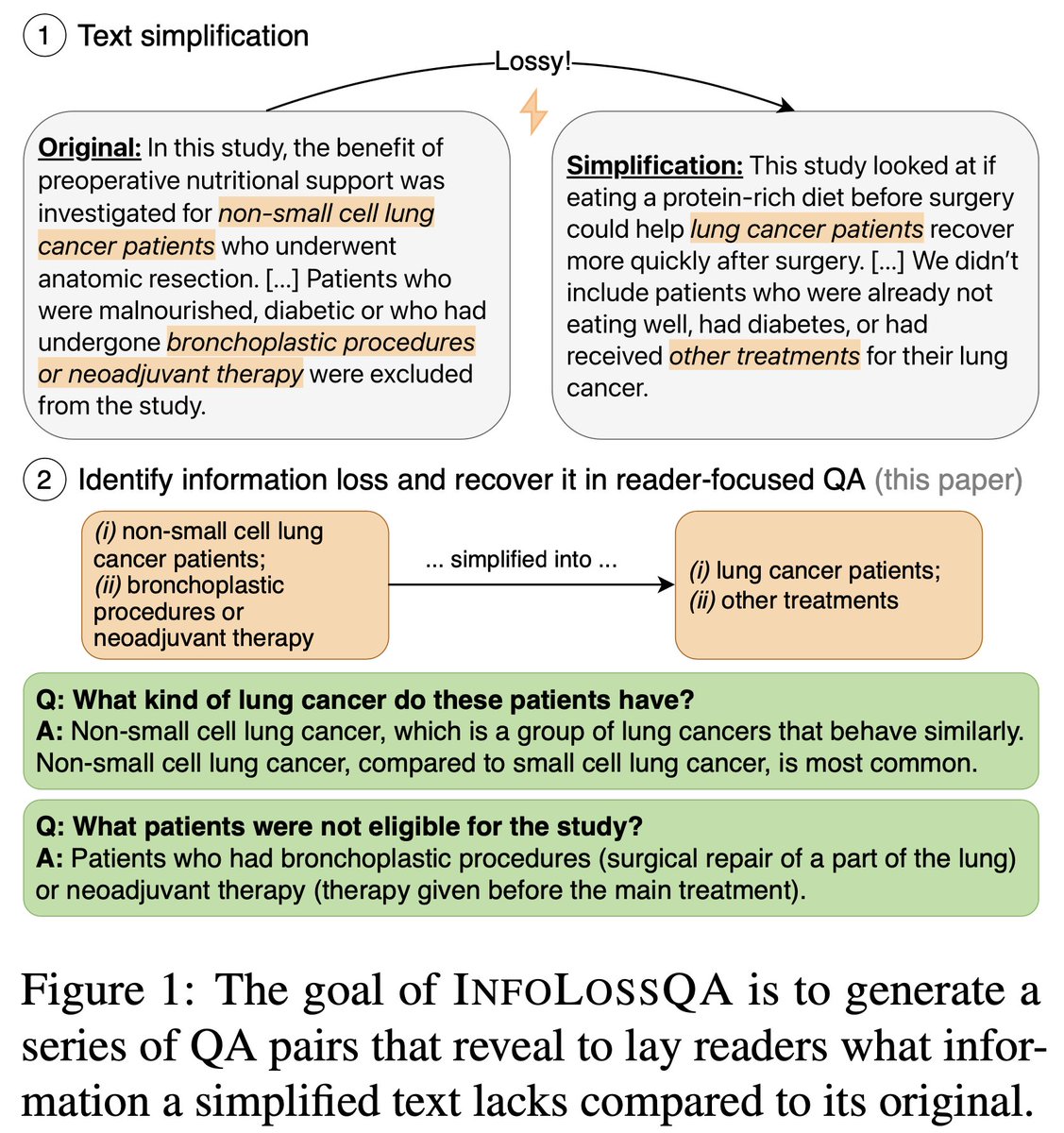
When we (or LLMs) explain technical texts, those explanations can be vague or omit detail. How can we characterize such information loss and help lay readers intuitively recover it?
Excited to share InfoLossQA! 🧵
Paper: https://t.co/YxnKSCDrug
Website: https://t.co/9zyIE1Lec7
excited to share our contribution to open science of language models!
🐈⬛ all our data, weights, ckpts, code, etc
🐈 covers data curation, pretraining, adaptation, evaluation, etc
check out more deets in @soldni ‘s thread, technical reports out on arXiv shortly 😆
I was fortunate to visit @jessyjli at the University of Texas at Austin to work on this project. Thanks to @DAAD_Germany and @IkimUme for supporting this research visit.
We propose to use QAs to describe information loss. The Q asks for missing information, the A provides it. We release a dataset with 1,000 QA pairs highlighting information loss across 104 simplifications of clinical trials in medicine 🏥. View all annotations on our website.
When we (or LLMs) explain technical texts, those explanations can be vague or omit detail. How can we characterize such information loss and help lay readers intuitively recover it?
Excited to share InfoLossQA! 🧵
Paper: https://t.co/YxnKSCDrug
Website: https://t.co/9zyIE1Lec7
Tomorrow I'll be presenting our work on creating a dataset for clinical text simplification at the TSAR-2022 workshop at #emnlp2022. Hope to see you there!