Pleased to say our #WebAI summit videos are starting to go up for 2025! Catch up right now to get the latest scoop on client side AI in the browser. 7 talks up, 13 to come - so subscribe to playlist to get notified when they do: https://t.co/3qNVFFMo0E
#Agents#AI#WebMCP#JS #WebDev #Chrome #Google #BayAreaEvents
@xenovacom Whoops my bad 😅 I know we announced it but i forgot when you all will get it. Yes do let me know how to fairs. PS are you doing continuous itteration here, or one session at a time, when you ask to optimise more each time? Do you give suggestions or completely open?
Gemini Spark is your 24/7 personal AI agent, handling the heavy lifting from start to finish under your direction.
Here are some ways our team has been using Gemini Spark to make their lives easier and more productive. 🧵
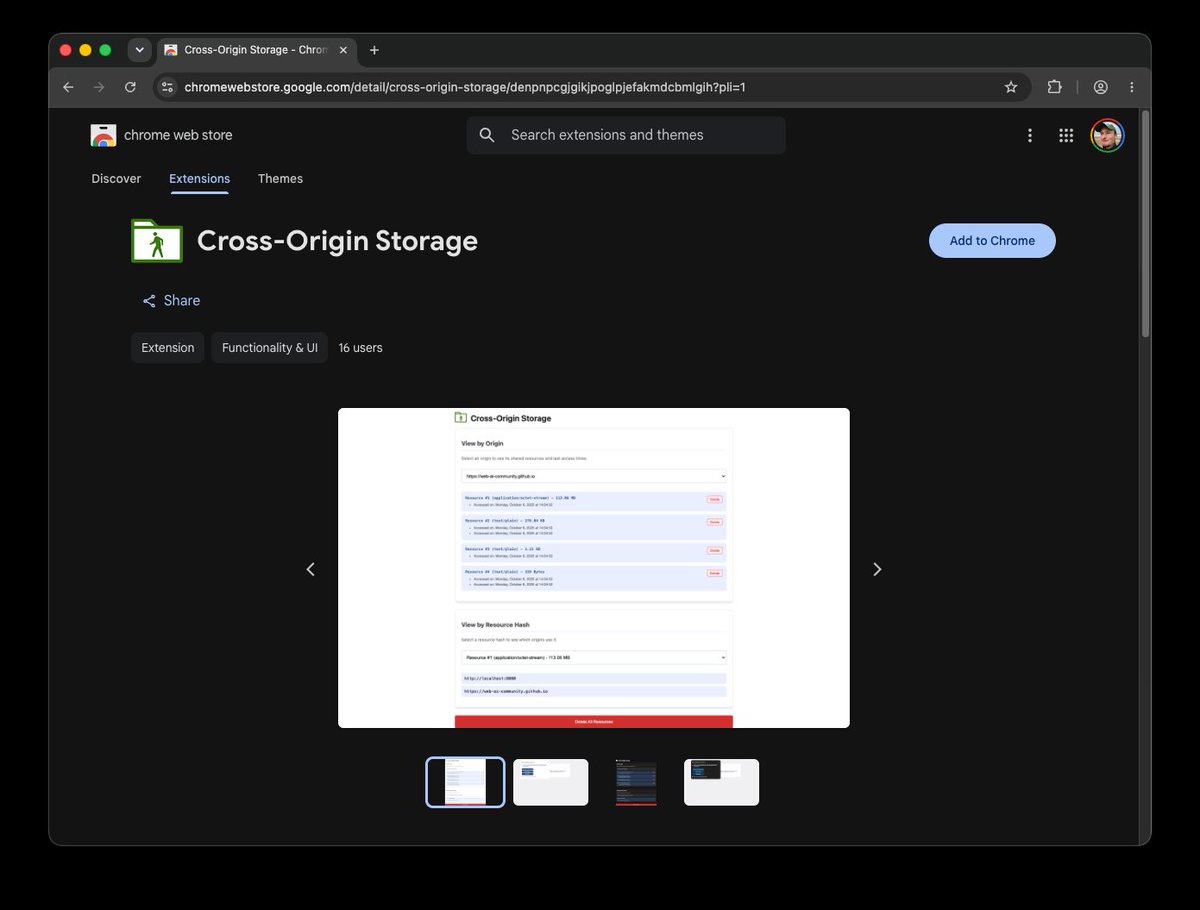
👨💻 Want to learn more about the raw API? This proposed new browser API, navigator.crossOriginStorage.requestFileHandle(hash), has the potential of revolutionizing the Web. Learn more on Github: https://t.co/1KXDH3n0sN
📢 Breaking news: @googlechrome folk just published a guest post on @huggingface 🤗 blog around the newly proposed Cross-Origin Storage API and how it's being used in #TransformersJS!
This allows huge #WebAI models to be shared across domains! Read 👉 https://t.co/F9sBSAuOIN
@JulianPaci@Google This image took me 3 prompts. First was basically how it looks but they character was not me.. So i asked it to change the main character to look more like me based on a photo, and then third prompt was to just refine and text that i wanted to read different
📢 This week I celebrate 15 years at @Google - Ask me (almost) anything & I will try to reply! ✨ Naturally I used Nano Banana 2 to generate this infographic for some fun stats and facts for my time at Google so far: https://t.co/tAYybeDnzC
Meet DiffusionGemma ⚡ Our latest experimental open model (Apache 2.0) that generates text up to 4x faster.
Instead of predicting and typing just one word at a time like most language models, it drafts and refines entire blocks of text simultaneously.
Here’s how it works 🧵 ↓
Gemma goes diffusion! DiffusionGemma with up to 1000+ tokens per second! 🌬️
- Built on Gemma 4 as a 26B MoE model.
- 3.8B parameters during inference.
- Generates text in 256-token blocks in parallel.
- Fits within 18 GB VRAM limits when quantized.
- Apache 2.0
@nicodotdev@Google It's moments like this that make it all so very rewarding to be a DRE ♥️ I am confident you will go on to inspire many more too, and thus the spread of Web AI continues! ✨
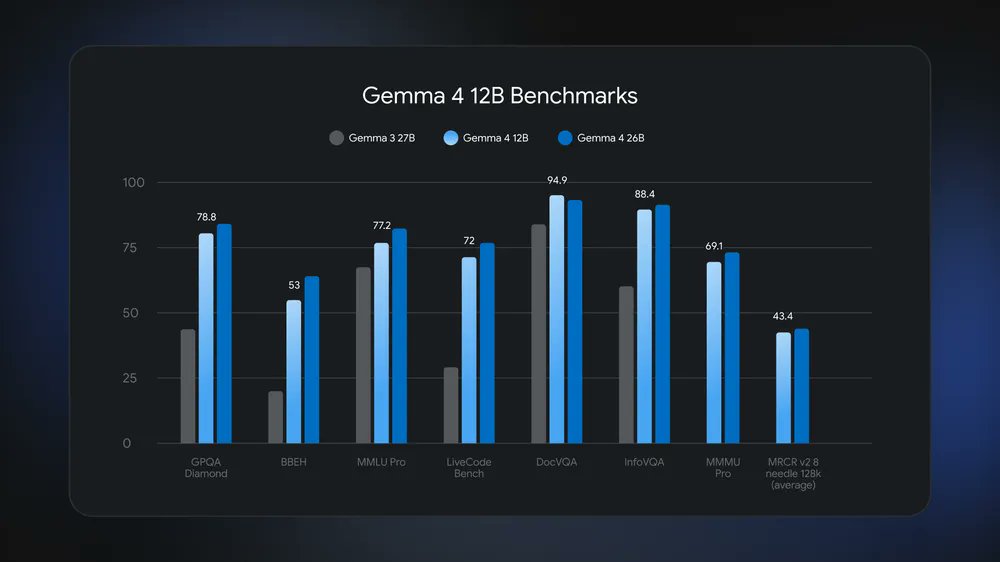
We just launched a Gemma 4 12B! Our first mid-sized model with native audio inputs. Gemma 4 12 B is a unified, encoder-free multimodal model.
🧠 vision and audio directly into the LLM.
💻 Just need 16GB of memory.
📊 Benchmark nearing 26B.
📄 Apache 2.0.
@kextcache@Google We've successfully run gemma 4 31b in browser using LiteRT-LM.js on Google side. We also have built in AI with Chrome to avoid the re-download per tab. Of course this is early stages of evolution but the rise of Web AI usage from 1M to 2.5B in 5 years shows healthy interest!
Breaking news: Llama.cpp now supports #WebGPU which means you can now run any #gguf model in the web browser via #WebAI. One more Web AI runtime to add to your watchlist in addition to @Google's LiteRT-LM.js, WebLLM, and Onnx Runtime Web. Try it here: https://t.co/jsQAB9oxsa
Gemini 3.5 Flash is now GA. Our most capable Flash model, built for agentic execution, coding, and long-horizon tasks.
- Outperforms Gemini 3.1 Pro on coding and agentic tasks
- 1M token context window with 65k max output tokens
- 4x faster output tokens/sec
- 4 thinking levels: minimal, low, medium (new default), high
- Thought preservation across multi-turn conversations automatically
Available today in @GoogleAIStudio, @Android Studio, @antigravity, Gemini Enterprise, the @GeminiApp, and AI Mode in Search.