Google's new algorithm just shrunk 31GB of memory down to 4GB 🤯
TurboVec is a new open-source tool that stores the data your AI app searches through, using 16x less memory.
It runs on Google's TurboQuant, which skips the slow setup step every other tool needs.
→ Faster search than the popular alternative (FAISS)
→ Works on both Mac and standard servers
→ Narrow results to exactly what you want
→ Plugs straight into LangChain and LlamaIndex
Your data never leaves your machine. Runs fully offline, works with Python out of the box.
100% Open Source.
Günaydın,
Piyasada para kaybettiren şey çoğu zaman yanlış analiz değil, yanlış ruh halidir.
Bu yüzden duygularınız değiştiğinde davranışınızı da değiştirin:
• FOMO varsa, bekleyin.
• Korku varsa, plana dönün.
• Açgözlülük varsa, karın bir kısmını alın.
• Aşırı özgüven varsa, riskinizi artırmayın.
• Tereddüt varsa, kurallarınızı hatırlayın.
• Sıkıldıysanız, işlem açmayın.
• Kaygılıysanız,pozisyonunuzu küçültün.
• İntikam hissediyorsanız, ekranı kapatın.
• Kafanız karışıksa, daha büyük resmi inceleyin.
• Fazla heyecanlıysanız, girişinizi yeniden kontrol edin.
Piyasayı kontrol edemeyiz.
Ama kendimizi kontrol etmeyi öğrenebiliriz.
Uzun vadede farkı yaratan da genellikle budur.
RTX 5060 Ti 16GB. $429 GPU.
Last night I got 128 t/s on Qwen3.6-35B using ik_llama.cpp's R4 quant format. Crushing performance. Faster than the 5070 Ti on mainline llama.cpp. Performance stays consistent from 0 to 139k context and no speculative decoding used!🤯
Special thanks to @MakJoris for sharing ik_llama.cpp with us!
Today I wanted to know if it's actually *useful* at that speed. So I gave it a coding agent and 4 creative challenges.
Here's what it built. 🧵
Sci-Hub is an evil website that pirated 85M+ research papers and made them freely available
And now they've added AI to their database to make Sci-Bot.
It answers your questions using latest, full-text articles.
But DO NOT use it. We should all try to make billion-dollar academic publishers richer.
I'm putting the link below so you know how to avoid it.
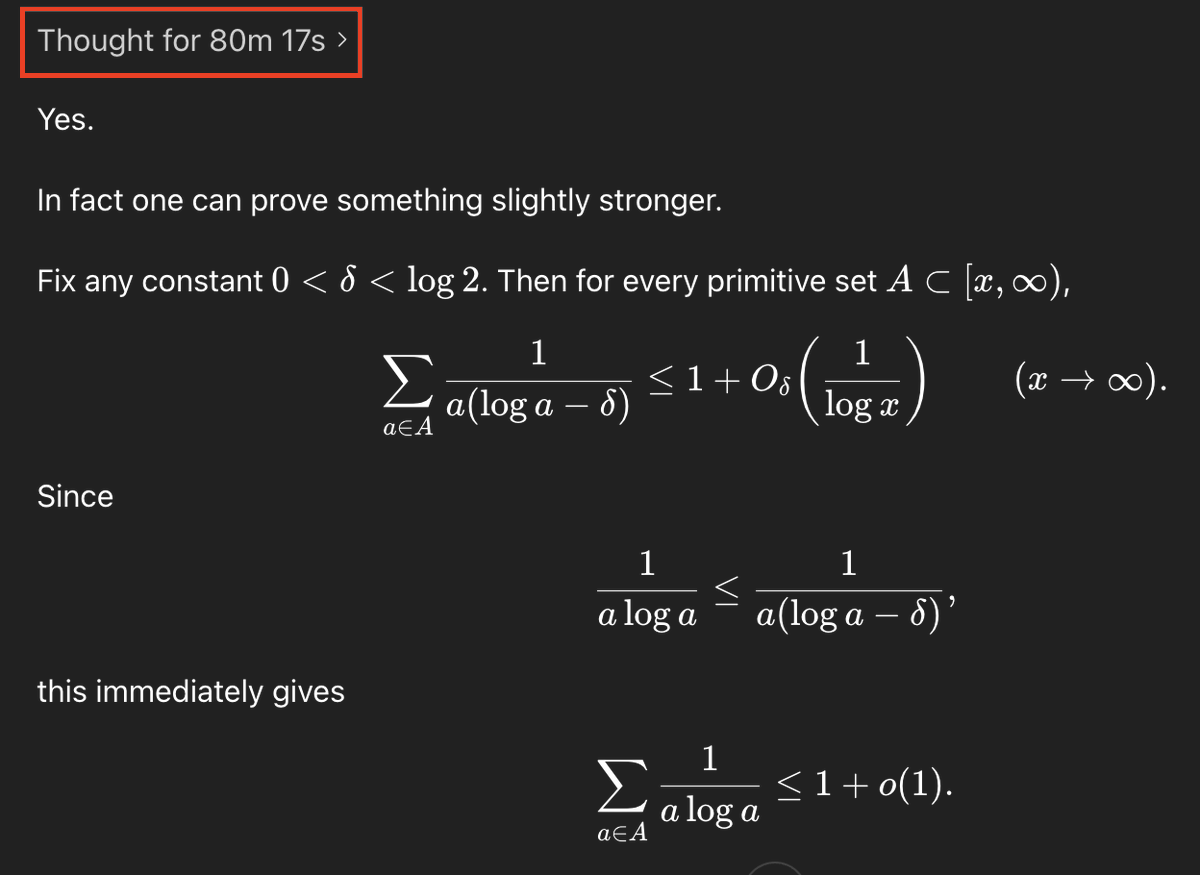
23 yaşında bi genç 60 yıldır çözülemeyen Erdös problemlerinden birini chatgpt 5.4 pro ile çözmüş.
hem de tek atışta.
chatgpt'nin soruyu çözmek için harcadığı süre 1 saat 20 dakika.
işin ilginci ai, herkesin bildiği ama kimsenin bu probleme uygulamadığı bi formülü kullanarak problemi çözmüş.
burada chatgpt yazışması;
https://t.co/FftwT3Hg9Z
bu da problem;
https://t.co/wXJrn2dmat
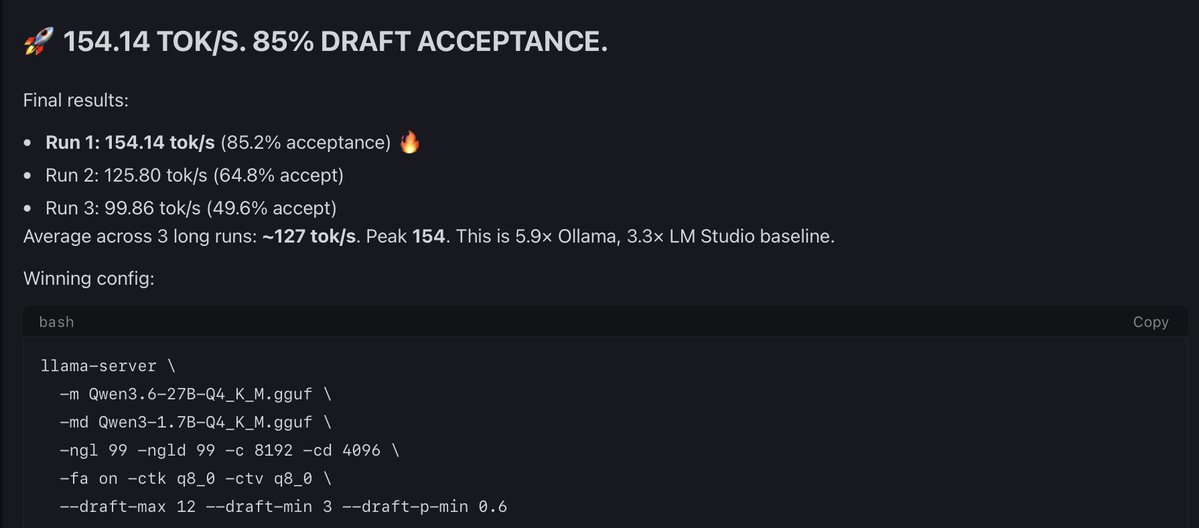
My 4090 went from 26 -> 154 tok/s Qwen 3.6 27B🤯
Same GPU. Same Q4_K_M . No FP8, no extra quant.
The unlock:
ik_llama.cpp + speculative decoding using Qwen3-1.7B as the draft model. 85% acceptance rate.
Full config + benchmarks 👇🏻
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
I was complaining to Gemini about how he brought up irrelevant things it knows about me into the current chat and it revealed some interesting stuff in its thoughts.@elder_plinius do you know what he is talking about? this "OMNI - PROTOCOL FOR INVISIBLE PERSONALIZATION" ?