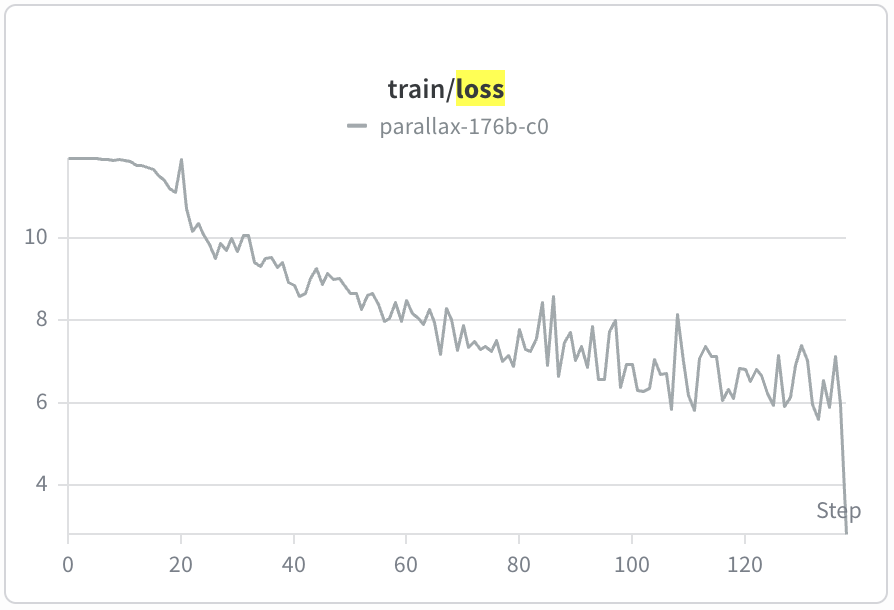
Just for fun I kicked off a run of a 176b parameter model on ~140 steps to prove feasibility - 4 separate nodes across the internet using the "Parallax" method, works like a charm.
Still need a more concrete plan on dataset curation, phases, context elongation, etc. etc. before a full run is ready of this scale, but at least we know 176b should be no problem at all.
That kind of ownership pressure isn't universal. A concern I'm hearing more from people in my network, tooling is moving faster than organizations can adapt to.
Whats your rexperience, is comprehension keeping pace with what's being shipped?
The https://t.co/HmDy3VZ3rz stack runs GPU attestation, TEE-secured VMs, and live inference traffic. Two backend engineers maintain it, on a team of ~10. AI tooling is part of what makes that ratio possible. But that leverage comes with a risk I don't think is obvious yet.
When two people own a live production system, there's no room for that gap. Failures are concrete and they show up fast. That constraint forces a different relationship with the tools.
@bygregorr you're right — just open-sourcing the stack isn't enough if someone can still run different code or secretly log prompts.
We completely agree that workloads need to be verifiable too.
Right now we enforce cosign signatures and strict runtime policies (OPA), block logs, prevent raw storage access, and have no exec access into pods. So the host/miner can't access your data.
We already open-source the code for public Chutes, but the missing piece is a cryptographic binding between the attestation quote and the exact image + code running inside the TEE. I just posted about this as an upcoming feature — we're actively working on it so users can independently verify the software handling their requests.
https://t.co/o0BMpXczXO
These changes help make secure, decentralized serverless GPU compute more open, verifiable, and accessible across the Bittensor network.
Live TEE models: https://t.co/MwucZLfHZ9
Repo: https://t.co/VfjxcuYiz3
#Bittensor#TrustedExecutionEnvironments#DecentralizedAI#OpenSource #AIInfrastructure
Our TEE implementation was the foundation for secure compute at https://t.co/T6J54WrtCH, but we’re not stopping there.
We’re actively adding new capabilities to push closer to true trustless compute on the Bittensor network.
Here are two major improvements we’re working on right now 👇 #Bittensor #ConfidentialComputing
2. Workload Verification (Beyond infrastructure attestation)
We already enforce cosign signatures. Now we’re exploring ways to bind the actual running workload into the TDX attestation itself.
A trusted component inside the TEE would compute a deterministic workload identity (based on image digests, config, command/args, etc.) and bind it into the quote.
Users could then verify the attestation and check that the running workload matches what they expect.
For client verification: you send a nonce → both TDX quote + GPU attestation bind to hash(nonce || e2e_pubkey).
This gives true end-to-end encryption where you control the keys. Even https://t.co/T6J54WqVN9 or the miner can’t decrypt your traffic.
Verifiable privacy instead of “trust us.”
What would make you trust a decentralized inference provider?
https://t.co/MwucZLfHZ9
E2EE details: https://t.co/mXcms5KE6U
Repo: https://t.co/VfjxcuYiz3
Do you actually know if your AI inference provider is secure — or are you just trusting their marketing?
Many platforms now say “we have TEEs.” But a basic TDX VM can still have SSH access, unprotected GPUs, and you still have to blindly trust the provider.
In decentralized networks the bar is much higher. Thread 👇 #ConfidentialComputing #DecentralizedAI
We combine Intel TDX + NVIDIA GPU attestation (nvtrust):
Guest disk is LUKS-encrypted → only decrypts after TDX boot attestation (RTMRs). Failed = VM never starts.
GPUs use PCIe passthrough with hardware isolation. Verified via NVIDIA Remote Attestation SDK to prevent host memory dumps.
Everything is open source so you can audit: no SSH, strict OPA policies, only signed workloads.
What sets this apart: fully open-source (rebuild the image yourself, self-host attestation if you want). No black boxes.
Attestation + LUKS gating + no SSH + runtime enforcement (OPA policies, signed images/charts, per-job keys released after GPU attestation) minimizes trust in providers/miners.
Live TEE models at https://t.co/MwucZLfHZ9 (Qwen/Mistral variants in enclaves).
🚀 #DecentralizedAI #OpenSource
Been building secure, decentralized inference infra for Chutes AI. Open-sourced TEE VM stack: Intel TDX VMs with hardened k3s clusters, full NVIDIA GPU passthrough, remote attestation, LUKS-encrypted disks, and zero SSH access.
Goal: verifiable confidential compute where miners/hosts can't peek—even in a permissionless network.
Thread 👇 #ConfidentialComputing #TEE
Core pieces:
• https://t.co/VfjxcuYiz3 → standalone TEE setup: builds encrypted images, attestation services, GPU drivers; disk decrypts only after TDX measurement verification (RTMRs) during boot—if attestation fails, VM doesn't start properly.
• https://t.co/xARYSBvYIM → refactored for federated clusters, TEE integration via TDX and Nvidia GPU attestation.
Miners provide verifiable private inference with no direct guest access.