Lei Xu is speaking at #SnowflakeSummit this Thursday alongside Vishwa Lakkundi (Sr. Manager, Snowflake) for 𝗔𝗽𝗮𝗰𝗵𝗲 𝗣𝗼𝗹𝗮𝗿𝗶𝘀 𝗶𝗻 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗲: 𝗢𝗽𝗲𝗻 𝗖𝗮𝘁𝗮𝗹𝗼𝗴𝘀, 𝗢𝗽𝗲𝗻 𝗙𝗼𝗿𝗺𝗮𝘁𝘀, 𝗢𝗽𝗲𝗻 𝗖𝗼𝗺𝗺𝘂𝗻𝗶𝘁𝘆.
The session covers where the open catalog layer is heading. Lance is one of the formats Polaris now supports alongside Delta and Iceberg. The direction is one catalog spec that works across every engine and every format, multimodal included.
If you're at @Snowflake Summit and building on Lance or thinking about how your catalog layer handles multimodal data as the format mix expands beyond Iceberg, this is the session.
Cosmos 3 by @nvidia released today — a frontier omnimodal world model for Physical AI.
For the data infrastructure behind it, they built on Lance.
SILA, NVIDIA's internal curation platform, processes tens of billions of multimodal training candidates as a single Lance dataset. Curation signals, embeddings, and vector indexes all in one table. No separate vector DB.
One table from raw data to training-ready.
3/ Every write versions automatically. Tag the baseline, tighten the threshold, both versions stay on disk. Open v1 and you get exactly the 604K rows the original run trained on. Full code: https://t.co/ILxMgCKbNN
2/ On LAION-1M, queried directly from the Hugging Face Hub:
→ 1.16M rows to 604K in a single SQL predicate chain
→ pHash catches ~25% near-duplicate clusters; CLIP-feature NN matching catches the rest
→ 95/5 stratified split, identical mean similarity (0.3318) across train and test
Most work still relies on MP4 videos ... creating a major bottleneck that kills GPU utilization and training throughput.
Not anymore.
We teamed up with the incredible @lancedb team to build blazing-fast data loading with native @huggingface bucket streaming support! ⚡
Would you like to join the research effort on JEPA and World Models easily?
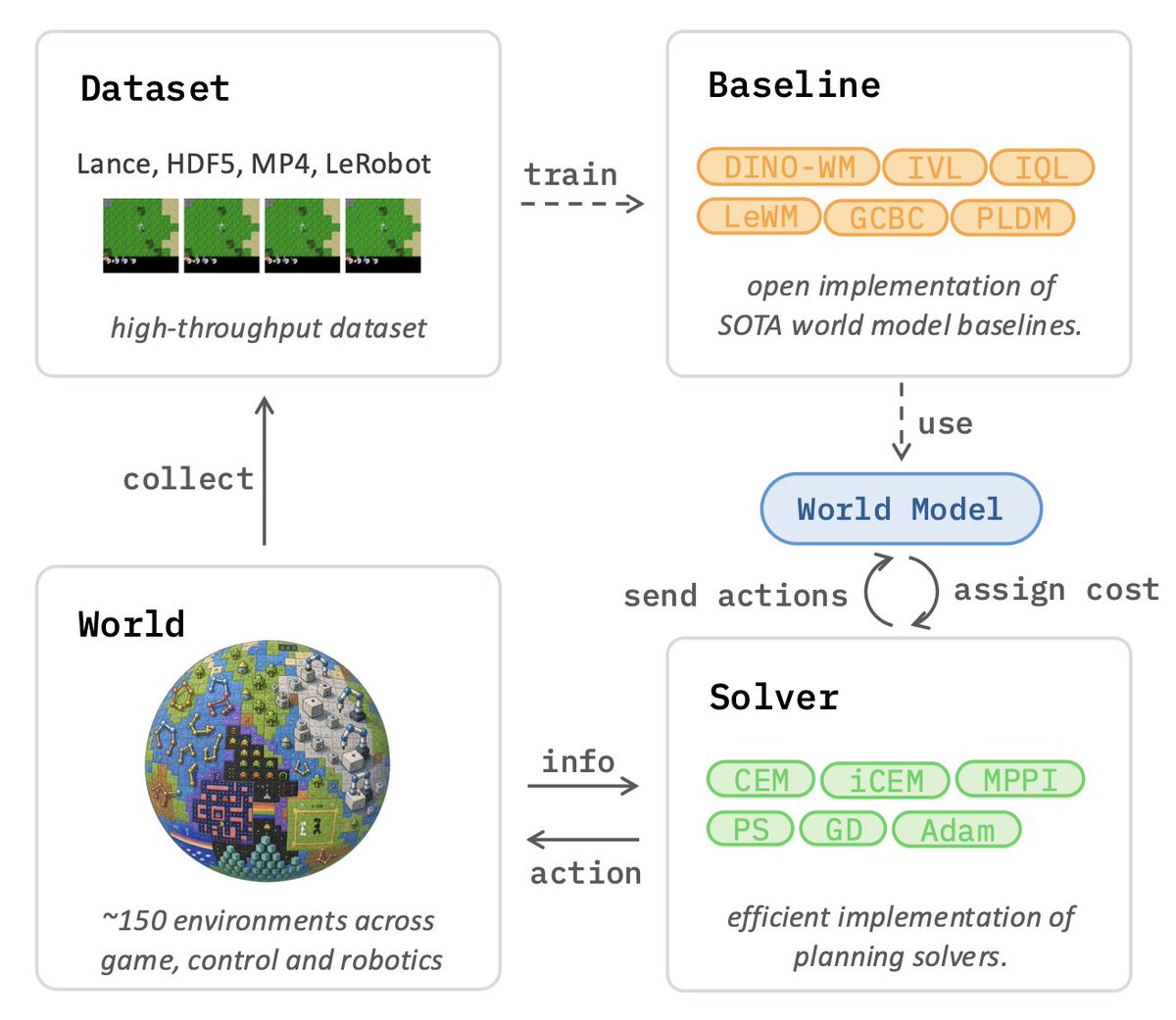
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
4/ The eval suite is the standout. Every environment exposes controllable visual, geometric, and physical factors. Train on the default, then test under color / lighting / size / friction shifts: one comparable zero-shot number out.
Code: https://t.co/R3ZDjwR2D5
1/ World model research is fragmented: every paper reimplements its own data pipeline, baselines, and eval harness. Comparing two methods fairly is weeks of infra work.
𝘀𝘁𝗮𝗯𝗹𝗲-𝘄𝗼𝗿𝗹𝗱𝗺𝗼𝗱𝗲𝗹 is a new open-source platform that standardizes the whole thing: https://t.co/Gg3V3LhKJr
3/ The data layer runs on Lance, with native conversion for MP4, HDF5, and LeRobot datasets. Small-batch random reads over a sequence buffer: 3–4x faster than HDF5 on local disk, gap widens sharply from object storage. S3-direct training on spot instances works.
1/ Three systems to query your own images: object store for bytes, vector DB for embeddings, SQL warehouse for metadata.
The Lance core extension in @duckdb makes it one SELECT — vector results, joined metadata, and raw image bytes in the same row.
@duckdb 3/ lance_vector_search() is a SQL table function.
Attach the Lance catalog as a DuckDB namespace and the retrieval results join directly to any DuckDB table. Standard SQL from there: WHERE, JOIN, GROUP BY, ORDER BY.
1/ LanceDB is in the @msft4startups spotlight at Microsoft Build 2026. Come find us in San Francisco.
We build the multimodal lakehouse — one table for raw bytes, embeddings, metadata, and features that serves exploration, feature engineering, curation, and training.