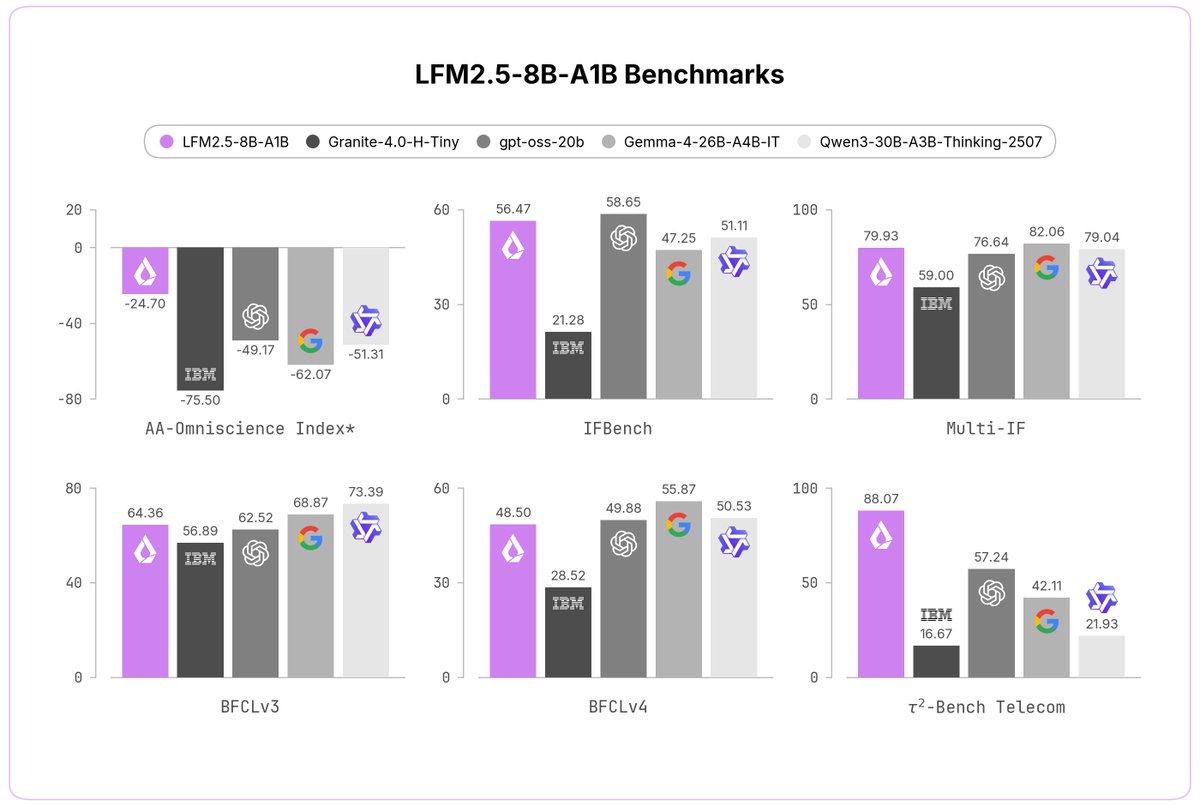
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
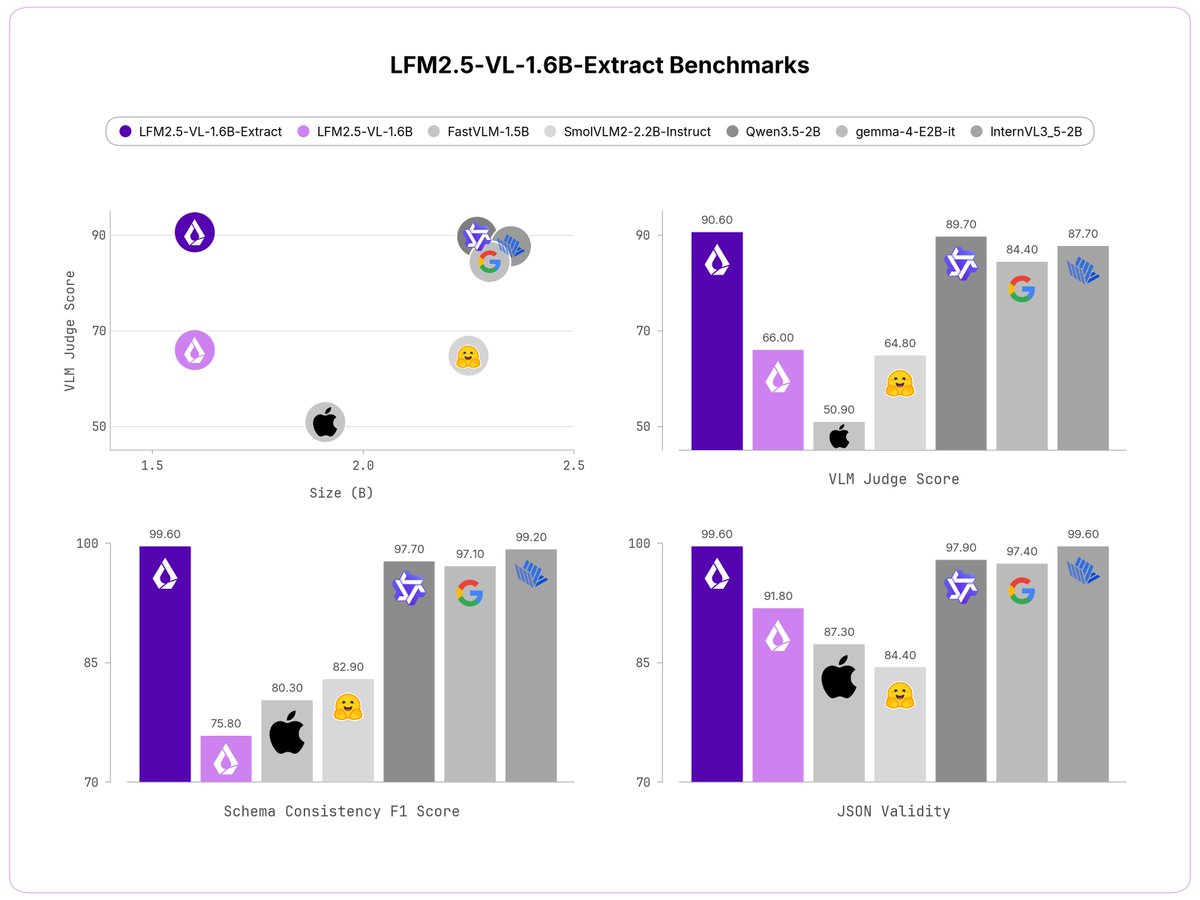
We released two new specialized VLMs 🎉
They extract structured outputs from images quickly and reliably.
You can customize your fields directly in the system prompt.
LFM2.5-VL-450M-Extract and LFM2.5-VL-1.6B-Extract are available now.
> Weights: https://t.co/Zu1AI4I4Fr and https://t.co/NTFNdTqd7s
> Docs: https://t.co/yxYpFwCom8
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
Built for structured data use cases:
> in-car cabin understanding
> document scanning
> industrial inspection
> any pipeline where downstream systems expect reliable structured inputs
(3/n)
Meet Liquid ShieldFlow.
An on-device privacy layer powered by a device-native Liquid Foundation Model, Liquid ShieldFlow redacts sensitive data before it ever leaves your machine. No GPU needed and light on memory. It runs on almost any PC, locally, in real time.
ShieldFlow was featured yesterday at @Microsoft Build for Foundry Local. It also ran live on @AMD laptops at @computex_taipei.
Request your early access here to ShieldFlow here: https://t.co/wU2ZPECvQx
Meet Liquid ShieldFlow.
An on-device privacy layer powered by a device-native Liquid Foundation Model, Liquid ShieldFlow redacts sensitive data before it ever leaves your machine. No GPU needed and light on memory. It runs on almost any PC, locally, in real time.
ShieldFlow was featured yesterday at @Microsoft Build for Foundry Local. It also ran live on @AMD laptops at @computex_taipei.
Request your early access here to ShieldFlow here: https://t.co/wU2ZPECvQx
Check out the guest lecture our CTO Mathias Lechner @mlech26l gave at @xanamini's @MITDeepLearning course on the secrets of massively parallel training: https://t.co/9OBKFv2pKo
Mathias covers the tradeoffs that matter in production: Why memory is more precious than compute, how pipeline bubbles kill throughput, and what 5D parallelism looks like on 2000 GPUs.
Last week we released LFM2.5-8B-A1B at @liquidai , a lightweight MoE built for local tool calling.
I wanted to put it to the test by building a Blender assistant powered by it.
@iamMrDuncan see here:
https://t.co/H5zpjkqOFV🔧-fine-tuning
it can go as cheap as $50 to prototype with lora. if you have a local GPU, you can even fine-tune it for free on a local PC, laptop.
Liquid's LFM2.5-8B-A1B smashed OpenAI's gpt-oss-20b on tool calling
We ran both locally on a MacBook Pro M5 Max, 64GB, and gave each the same trip-planning request that only completes if the model fires all 7 tool calls - weather for 3 cities, two currency conversions, an email and a reminder
Outputs:
LFM2.5-8B-A1B: 4.8 GB RAM usage, 7/7 tool-calls, 266 tok/s, 6.9s
OpenAI gpt-oss-20b: 11 GB RAM usage, 3/7 tool-calls, 146 tok/s, 15.0s
The 8B used less than half the RAM and still fired all 7 calls, while the 20B silently dropped more than half of its own. It also ran ~2x faster, wrapping the full agentic request in 6.9s against 15s. That's what 38T training tokens buy: a 1B-active MoE that nails the agentic tool calls a model 2.5x its active size keeps dropping