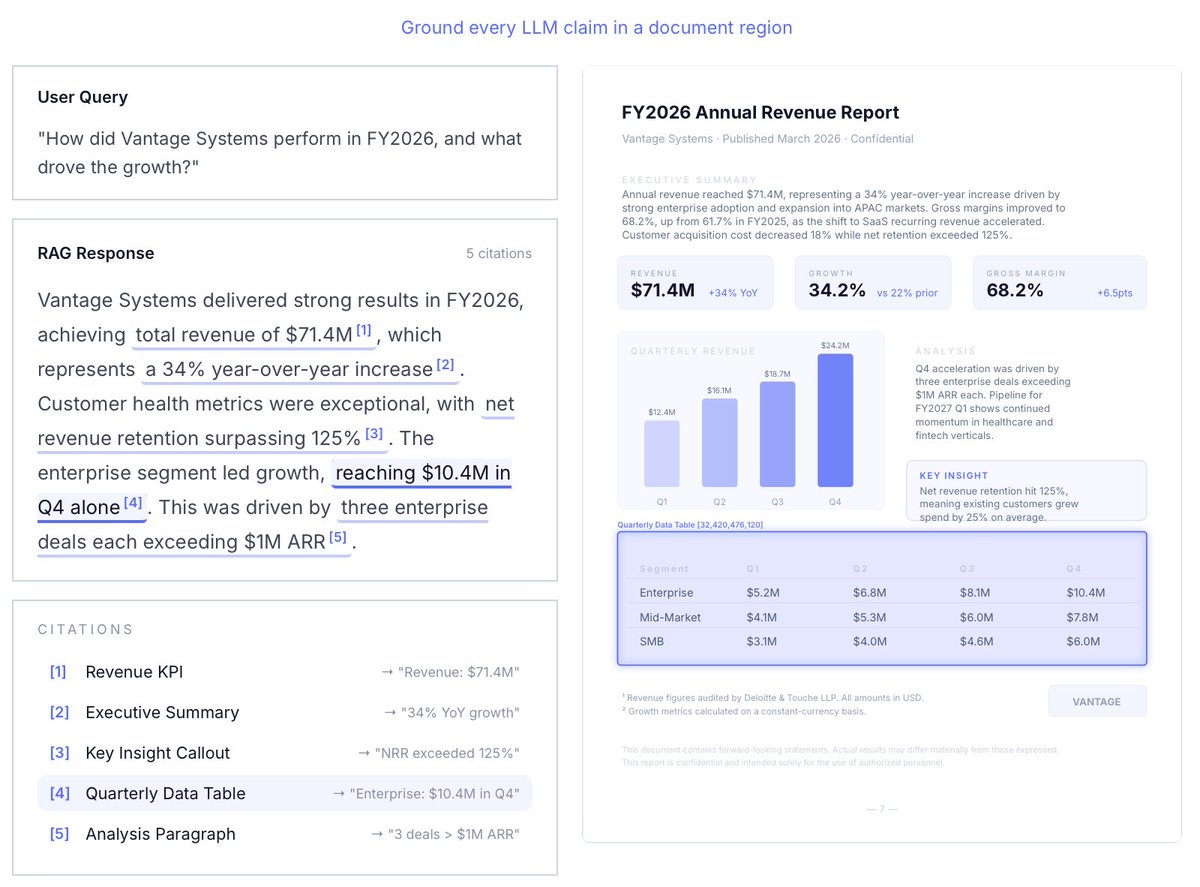
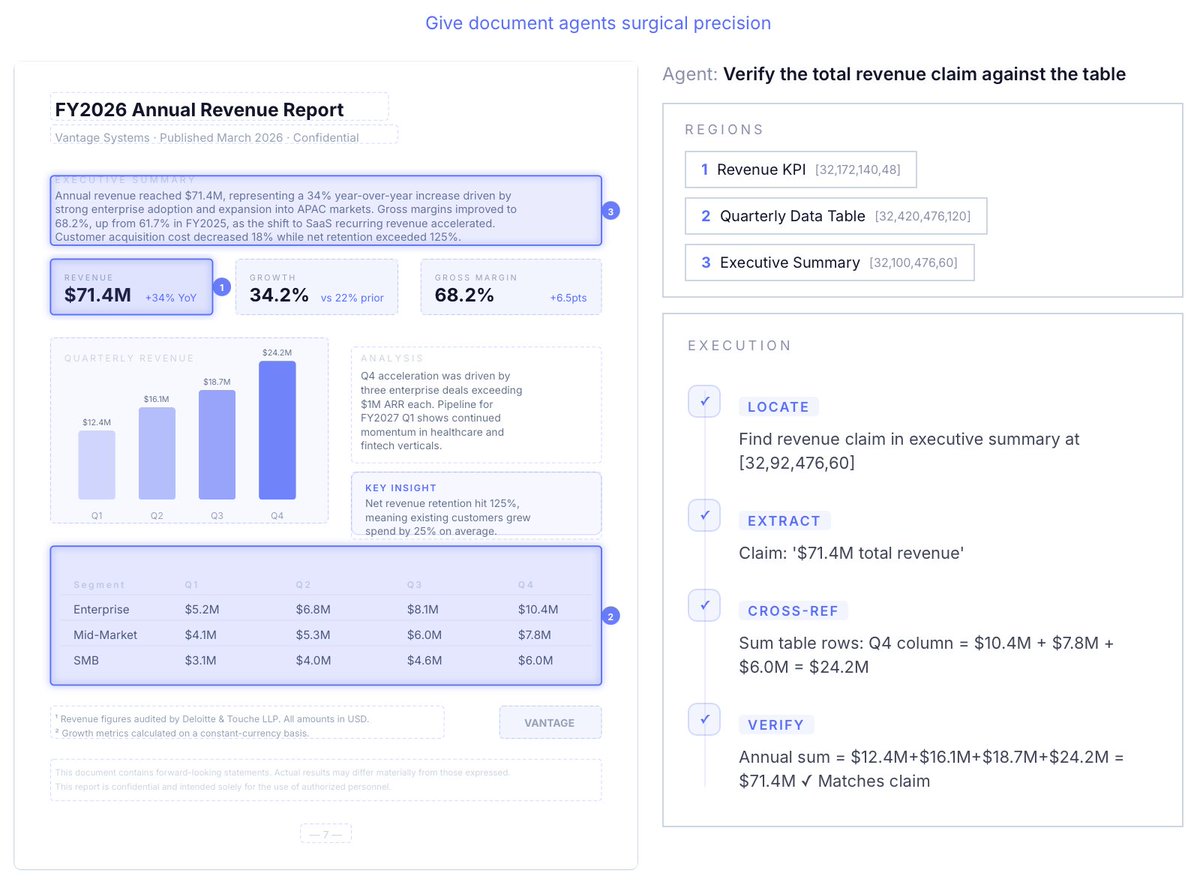
Your LLMs are hungry for data, but documents are messy 😩.
DocStrange is the answer!
Our open-source solution turns any document into clean, LLM-ready data with one command. Give your models what they need.
🔗 https://t.co/pND5QKdUIK
🔗 https://t.co/kwoEZL1GBB
Our new product, Atlas is live on Product Hunt today. 🔥
If you're a builder, you and your whole team are likely struggling to maintain one single company context across Claude, GPT, your sales tool, your CRM.
We built Atlas because that's just a stupid problem to still have in the big 2026.
Atlas basically maps out everything that makes your company yours, your tone, how you work, what you sell, how you position it, and stores it as a context graph that any AI tool can pull from.
One source of truth for the whole org. So you and your team can switch tools, systems, workspaces whenever you want and nothing resets.
P.S. First 200 teams get white-glove onboarding at just $99/month.
Real-world instructions don't come one rule at a time. They tangle - budgets, exceptions, "never do X," and conditions that fire other conditions.
SurgeAI created a benchmark for this - it's called Complex Constraints. We tested Nanonets on this ComplexConstraints benchmark.
Result: #1, ahead of every frontier model.
🥇 45.0% of tasks fully solved (Gemini 3.1 Pro: 40.4%)
✅ 90.0% of individual constraints satisfied
The trick isn't a longer prompt - it's a context graph.
What software has actually gotten better?
OpenAI and Anthropic are racing toward $100B+ in ARR. The #1 use case, by far, is software.
So here's the question nobody's asking: which software you actually use every day has gotten better?
Your AP system, claims processing, compliance checks, back-office ops - the software that runs companies still breaks on the same thing: following lots of rules that depend on each other.
Surge AI built a benchmark for this - ComplexConstraints. Real tasks where rules interact, override, and cascade, and one early mistake breaks everything downstream. The best frontier models solve under 41% of them.
Nanonets ranks #1: 45.0% of tasks fully solved vs 40.4% for the strongest public model, and 90% of individual constraints satisfied.
The difference isn't a bigger model - it's how we represent the rules. We parse every instruction into a context graph: each rule a node, every dependency an edge, so nothing gets dropped as the rules pile up.
Frontier models made writing software easier. Context graphs are what make the software actually get better - the missing piece for enterprise automation: not more raw intelligence, but reliable rule-following at scale.
Full results + how it works 👇
https://t.co/XklH4MDmjL
Nanonets OCR-3 is live.
This is the most accurate OCR model in the world currently.
87.4 on OLM-OCR (Global #1)
85.9 on IDP Leaderboard (Global #1)
90.5 on OmniDocBench
OCR-3 also ships with two critical features that foundational models and VLMs miss today - confidence scores and bounding boxes.
Nanonets OCR-3 is the only OCR model you'll need in your agentic stack. The model API exposes five endpoints -
/parse - structured markdown
/extract - structured outputs in your schema
/split - classify or split outputs based on content
/chunk - context-aware chunks optimized for RAG
/vqa - grounded answers with bboxes over sources
We've specifically fine-tuned the model on edge cases where OCR repeatedly fails - complex tables, forms, non-trivial layouts.
With bounding boxes, you get exact coordinates for every extracted element. Use them for -
1. RAG citations
2. Feeding specific document regions to agents
3. Agent observability
With confidence scores, you can measure reliability of every extraction.
Pass high-confidence outputs directly, route low-confidence outputs to human review or a larger model. Use them to push your net accuracy to near 100%.
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Live demo: https://t.co/l5fV5lA2za
HF: https://t.co/2qAVqfhpON
Blog: https://t.co/xXcJsphbEQ