Hunting for parallel data for Asian Languages? ParaCrawl just added 9 new bonus corpora. More info & paper by Philipp Koehn from @jhuclsp to be presented at WMT24 (#EMNLP2024): https://t.co/m2uEZ2k0kL
The 9 datasets, as Bonus Release: https://t.co/Ncx2jlhmNF
Hi there, three new Bonus ParaCrawl languages have been just released:
- English- Azerbaijani
- English-Tajik
- English-Armenian
Go to the ParaCrawl website, scroll down to Bonus Languages (Low-Resource), download your preferred version: https://t.co/Ncx2jlhmNF
HPLT News and Tools!!! If you are interested in filtering your datasets for quality and using them to train MT and LLMs, you are interested in this thread 👇
Interested in Open and Community-Driven MT initiatives? CrowdMT is for you!
🎙️Invited speakers from Wikimedia Foundation and Apertium announced.
📜Accepted papers and abstracts announced.
Time to register at https://t.co/Sxpp59rDHp
Details: https://t.co/oGlIb88HjG
Parallel (en-*) and monolingual new corpora from #MaCoCu just released. Included languages:
Albanian
Bosnian
Bulgarian
Croatian
Macedonian
Maltese
Montenegrin
Serbian
Slovene
Turkish
We've published new #MaCoCu web corpora for 11 under-resourced languages!
56 million documents, 17 BILLION words (monolingual corpora) and 580 million words (English-X parallel corpora) were just uploaded to the https://t.co/uQlUZ0UlqA repository (https://t.co/fwlCrf5glK) 🥳
#MT people: submission date extended for the CrowdMT workshop to present works on Open Source and Community-Driven MT: 21st April 2023!
Abstracts and papers wanted!
You wanted also in Tampere, for the whole #EAMT23 conference or at least for this workshop on the 15th of June!
@aihkas @BramVanroy @Nils_Reimers@huggingface@Reverso_ Hi @aihkas, sorry for the late reply. ParaCrawl website has a "Notice and take down policy" section with contact e-mail. Anonymized versions of ParaCrawl corpora (ROAM) were released to avoid these issues. We will make sure that your personal data gets removed, if still present.
@Nils_Reimers @BramVanroy @huggingface Sure Nils, check https://t.co/bpCHCRDhS0 for a full list of languages. The different efforts covered more than 40 languages. We just published a new one today, Polish-Czech. Unfortunately, only sentence-aligned.
@BramVanroy @Nils_Reimers@huggingface Sorry, guys, @ParaCrawl corpora are sentence aligned only. URLs are provided but documents are difficult to reconstruct.
A new ParaCrawl parallel corpus is available!
🌍 languages: Polish-Czech
🎒 size: 24 million sentences
🗒️ license: CC0
🎯 location: https://t.co/RomGYSHhdz bonus section
🧐 more info: https://t.co/m2uEZ22oWb
Indeed, this is the first data release of the #Macocu effort. You will find both monolingual and bilingual (with English) corpora on ELRC-Share and CLARIN repositories and the website. Insights coming soon! Most of the code also ready for you to try it out!
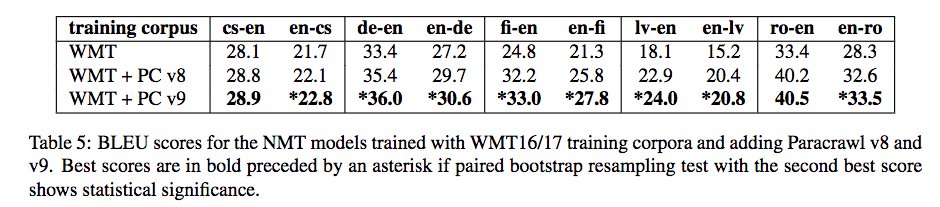
@vince62s Hi, publications coming soon, but see here MT results (spoiler, all BLEUs go up in V9):
Also, yes, v9 and all the rest of versions are shuffled.
Summer was for work! Now #ParaCrawl v9 corpora are done and again bigger than the previous ones!🤩 Extrinsic evaluation through MT almost finished and, according to old BLEU and new COMET, the quality of the MT output improves! 🥳 We will share corpora and more results soon!🕑
Check out MultiParacawl 9, including 36 parallel corpora for Ukrainian and a total of 705 bitexts. Thanks OPUS and @TiedemannJoerg to share this great resource! https://t.co/ZaDFtEHHrX
We're back with more language resources: English-Ukrainian parallel corpus with aprox. 13M sentence pairs has been released. More info and downloads:
https://t.co/6DLST6wo86
Please, spread the word and use it!
@jjon1910 Please try again, it was not you, but a typo in a script.😑 Thanks for reporting the issue and for your interest in being the first one downloader! 🤩
Done! All #ParaCrawl v9 corpora are now available at https://t.co/RomGYSYSC9, some also on Corset https://t.co/ocUOmmwrmM to further inspect or filter them and a new Bitextor is also out https://t.co/5c3Q3rmSUQ! Thanks to #CEF and the EU for co-funding this great project!
Very clear TODO from #ParaCrawl's last stakeholder board meeting: we need better language identification, specially for closely-related languages and for under-resourced ones. Such a basic thing! Trying here to improve current results mixing Fastext and Hunspell, take a look👇