CTO of @InfluxDB (YC W13), founder of NYC Machine Learning, series editor for Addison Wesley's Data & Analytics, author of Service Oriented Design with Ruby.
Because a harness is just a loop with some tools. A good model will follow instructions and use the tools to solve the problem exhaustively. A bad model won’t even be able to make proper tool calls, let alone reason about how to solve the problem put in front of it. Instruction following has improved dramatically over the last 12 months due to model intelligence
I was recently diagnosed with a rare autoimmune disorder called anti-NMDA receptor encephalitis. It's a "disease of chaos" that completely upturned my life for a couple months.
I wrote a blog about it that goes into more detail and discusses prognosis.
https://t.co/mP0ftCuwpp
Interesting interview as always from @adamhjk. The thing he says early on about their dev process at https://t.co/NRI9ZtODDz that I very much agree on (but haven't solved) is that your dev process can't have developers blocking on each other.
PR review breaks this requirement completely. And I still don't trust the machines (or myself) enough to get rid of it. And I haven't yet built enough verification tooling to get to that point. It's my number one priority now, building tooling that does testing, benchmarking, verification so that the development process can be put into a full time agentic loop.
We unlock that and we unlock roadmap on demand.
In the meantime I've written hundreds of thousands of lines of code that I don't dare ship. How do we support it? Is it robust? Can it be improved without collapsing on itself? Need to answer those questions first before we can.
We've been building Swamp as a small team of AI Maximalists, and it's been incredibly fruitful. I got to talk to @adamstac at the @changelog show about my experience roughly 4 weeks in. We've only accelerated since then. Listen: https://t.co/5m0uH1EhHs
This is the early days of working exclusively through building the machine that builds the machine. But it's getting better every day, as a (still small) industry we're getting faster at it. The future is adaptive software like swamp, openclaw, etc - combined with thoughtful software engineers designing machines to generate the software they want to see in the world.
It's fucking glorious.
Looks legit for the Bun rewrite testing: https://t.co/EMQcSMKHcj
If true and the result is good as measured by real-world usage and reports of it working well, then this means that human code review is not long for this world.
It's 1M new lines. Not human reviewed, I'm sure.
LOL the Bun rewrite of Zig -> Rust is great entertainment. I can't wait to see how this plays out. People are losing their minds on HN (https://t.co/U1FvrM8vRI) and GH (https://t.co/1jzN8n10zZ).
A bellwether for agents writing all code, where humans are only there to direct.
Also, I'm dying to know if this was done with unlimited Mythos tokens. Is this the near future for the rest of us? Or the now and they did it with Opus 4.7 tokens? My guess is the former. So it's a preview of what's possible later this year.
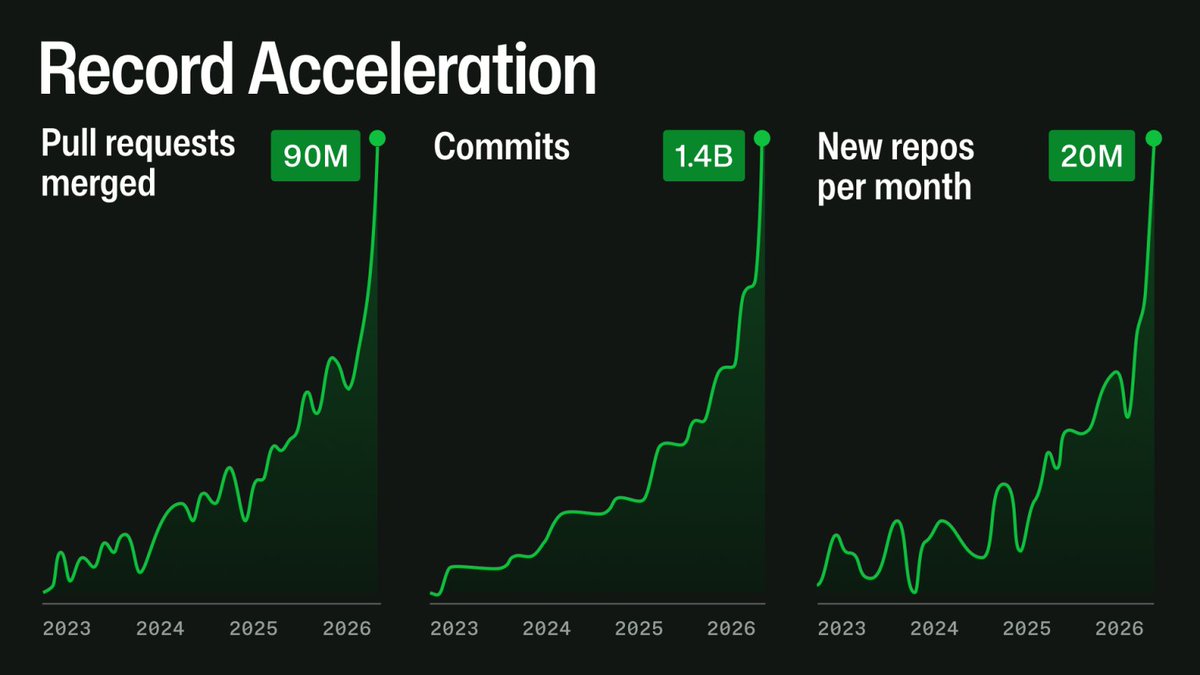
Consider that the start of this graph was already at considerable scale. A shift of this size generally requires rearchitecting. To do it in this time frame seems impossible. So yeah, I have much sympathy for the GH team.
I don't work on reliability & scaling at GitHub, but the people who do aren't bad at their jobs. They're dealing with unprecedented scale from agents.
It's easy to shit on GitHub from the outside if you're not in charge of 30X-ing capacity within a few months. Have some grace.
We released @InfluxDB 3.9 today! For our Enterprise customers, it has a beta of enhancements to our storage system enabling very wide & sparse tables and MUCH faster performance on single series queries.
This brings the flexible schema and fast series lookups you love from v1 and v2 into v3 while maintaining support for infinite cardinality, scalable object store durability and the fully featured SQL query engine provided by DataFusion.
Read all about it: https://t.co/NXJDYKd1cw
Good read from @breckcs on Adapting to AI and his work in 2025. I feel a lot of the same things. Although I'll say things shifted dramatically for me with Opus 4 and Claude Code in late May 2025 and have only accelerated from there.
I've produced hundreds of thousands of lines of code in the last 6 months, but most of it has not gone to production and likely never will. Although there is some very big stuff getting released soon that includes the more well reviewed and iterated on bits of this mass of work.
The challenge for me this year is to figure out how to actually harness all this new found power and capability without it collapsing the entire product. And how to rework product and engineering in this new world.
I feel pressure to either adapt and thrive or fall hopelessly behind to other teams that make the best use of the tools and create processes that showcase what's possible. The possibility of the 100x or 1,000x team is already here, it's just not evenly distributed.
His metaphor for being in a hot dog eating contest with unlimited hot dogs feels apt. The trick now is selecting which hot dogs to actually eat.
https://t.co/RYfPD1DB1x
@lacker Yeah, I think the age of gobs of saved dashboards is coming to a close. Agentic UI that can produce what you want on the fly is more powerful. But saved shared views are also useful for a human to stare at occasionally
This essay on bank tellers and why it was iPhones, not ATMs that brought the ultimate decline in human bank tellers highlights how AI could potentially disrupt jobs is a great read: https://t.co/8u4vaOiDbN
This it captures it perfectly:
“The ATM tried to do the teller’s job better, faster, cheaper; it tried to fit capital into a labor-shaped hole; but the iPhone made the teller’s job irrelevant. One automated tasks within an existing paradigm, and the other created a new paradigm in which those tasks simply didn’t need to exist at all. And it is paradigm replacement, not task automation, that actually displaces workers”
A few months ago I stated that the productivity gains in software development would be limited by everything outside of actually writing code: https://t.co/08NkppYbz2
We’d run afoul of Amdahl’s Law where we’ve made creating code almost instantaneous but only gains modest improvements in our speed to deliver software. All the other tasks in the lifecycle would still take up too much time.
I think that’s true, but the ATM/iPhone example highlights something more important for actually realizing the gains. Why optimize the speed of PR reviews when you can make them irrelevant?
What does the SDLC look like when you rethink how it’s delivered and stop trying to automate individual human roles and tasks that currently exist?
Something I’m thinking about in this magical time of AI where things that were previously impossible or unthinkable are daily routine.