Anthropic anunció una alianza con SpaceX para aumentar su capacidad de cómputo, y los efectos son inmediatos:
- Doble de límites en Claude Code (ventana de 5 horas) para planes Pro, Max y Team
- Se eliminan las restricciones de horas pico para Pro y Max
- Límites de API sustancialmente más altos para modelos Opus
Personalmente ya he cambiado a Codex y GPT, pero esto no viene nada mal, la competencia beneficia los usuarios😶🌫️😶🌫️
Gemini 3.2 Flash acaba de aparecer en el selector de modelos.
Sin anuncio. Sin blog post. Solo algunos usuarios viéndolo — y ya.
Google I/O es en dos semanas. Por lo que la llegada de Gemini 3.2 Pro es inminente.
Si con esta generación finalmente arreglan el tool calling…
DESIGN md, the format Google open-sourced from Stitch, is the closest thing we have to giving AI coding agents actual design taste. I found a page with more than 2000 DESIGN md file from real shipped products.
Here's the problem it solves. LLMs were trained on millions of lines of code and text, but product design lives somewhere else entirely — in pixels, in tacit decisions, in rules nobody bothered to write down. So when you ask Claude or Cursor to build a UI, you get what's statistically "correct." And the statistical average is generic.
The format itself is deceptively simple: YAML tokens at the top (exact hex codes, font sizes, spacing values) and markdown prose below explaining the why behind each decision. Plain text, git-versionable, readable by humans and agents alike. Drop it at the root of your project and your agent reads it on every task.
I just came across Refero Styles, which has 2000+ DESIGN md files already extracted from real shipped products: Linear, Vercel, Stripe, Cursor, Anthropic, Raycast, Warp. You search for the aesthetic that fits what you're building, copy the file, and the UI stops looking like a template.
The interesting thing isn't really the tool. It's the pattern underneath it. Plain-text context files (CLAUDE md, AGENTS md, now DESIGN md) are quietly becoming the way you program agents without programming them. Less prompt engineering, more context curation. The leverage is moving from how you ask to what the model can actually see.
Context engineering is a concept that's getting stronger by the day.
https://t.co/TusV4EQ7oz
Meta just made their ad platform agent-native.
They shipped a command-line tool for the Marketing API today, and the announcement says it out loud: built for "developers and AI agents."
That second word is the whole story.
Until today, an agent that wanted to run ads had to be wrapped in custom code handling auth, pagination, and the structure of campaigns and ads. Most teams never got past the plumbing. Now an agent can run a campaign with the same kind of command a developer types in a terminal.
Picture agents pausing losing ads overnight, shifting budget from a Slack message, spinning up lookalikes off your CRM, testing fifty creative variants and keeping only the winners, reporting back every morning before you open your laptop.
That whole layer just became buildable.
The world is moving so fast, we need to adapt faster than ever.
#meta #agents #AI #automation
https://t.co/2h2Uo7dPJX
Si construyes con Claude y tu app habla español, estás pagando 62% más por cada conversación de lo que pagarías en inglés.
No es un decir, es medible:
Alguien tomó "The Bitter Lesson" de Sutton, el ensayo que sostiene que escalar cómputo siempre le gana a la ingeniería humana cuidadosa, y midió cuántos tokens consume en distintos idiomas.
Español en Claude: 1.62x
Árabe en Claude: 2.86x
Hindi en Claude: 3.24x
OpenAI se queda entre 1.15x y 1.37x para los mismos idiomas.
Lo que esto significa en práctica: cada prompt que mandas en español cuesta 1.62x. Cada respuesta que te devuelve en español cuesta 1.62x. La conversación completa, ida y vuelta, sale ~62% más cara que la misma conversación en inglés.
Por eso muchos equipos serios mantienen el "thinking" interno de sus agentes en inglés y solo traducen el output final al usuario. No es purismo técnico, es matemática de márgenes.
La Bitter Lesson decía que el conocimiento humano pierde frente a la escala. La nota al pie que el experimento expone: las decisiones humanas no desaparecen, se mueven una capa más abajo, al tokenizer, y se vuelven invisibles hasta que abres la factura.
Beta cerrada de Synapse — gratis para que puedan estudiar ese tema relevante de forma seria, y de paso ayudar a mejorar la herramienta antes de que se vuelva publica. Pueden entrar y explorar, ya pueden solicitar el acceso.
https://t.co/iFWj7fq3bN
Notebook LM es una solucion muy buena para estudiar y Adrián Sáenz acaba de subir una review muy buena.
Pero hay algo que casi nadie está diciendo: Notebook LM no está hecho para que aprendas. Está hecho
para que consultes más rápido. Como realmente no tiene una metodologia ni orden de estudio, te crea ilusión de aprendizaje que realmente, te daras cuenta, a los dias ya habras olvidado lo que estudiaste.
Continuo 👇👇👇
Yo tengo un sistema de estudio en el cual he insertado Inteligencia artificial para ayudarme, y realmente me ha dado muy buenos resultados. Debido a esto decidi crear Synapse.
No es otro chat con IA. Tomas tus PDFs, videos o notas, y te arma un trayecto de aprendizaje
fundamentado en psicología y pedagogia para el aprendizaje, te toma de la mano y te guia a realmente dominar lo que quieras estudiar.
@khushiirl I created a solution to learn for real, with real pedagogical and psychological research.
I hope people see value, It is a solution I have been applying for me last months.
https://t.co/iFWj7fq3bN
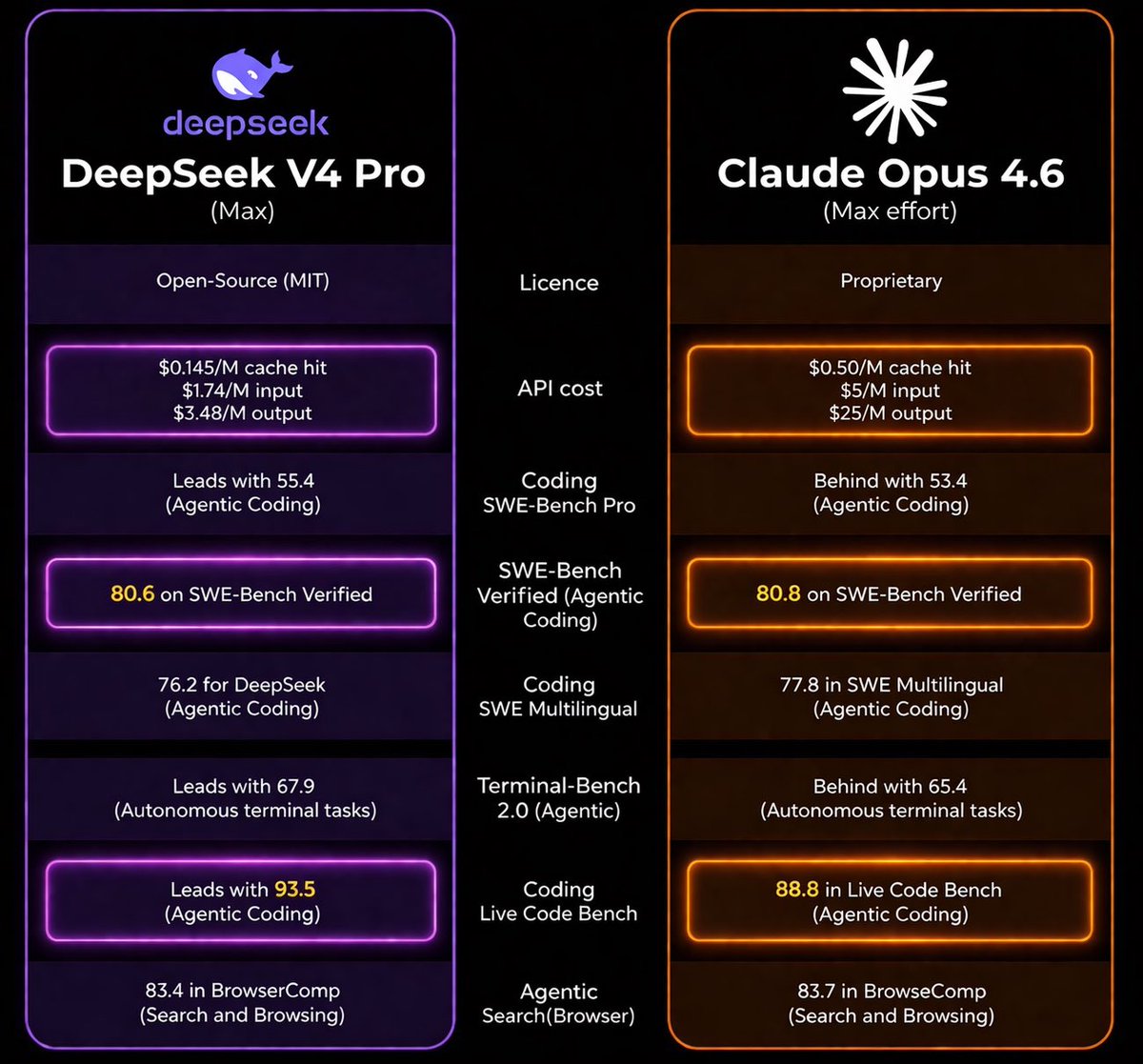
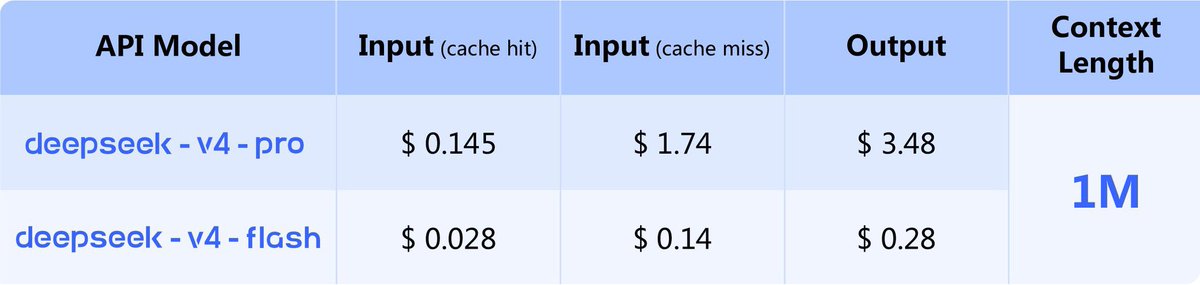
Acaba de salir el modelo de AI más barato y más poderoso de la historia. La ballena dormida acaba de despertar finalmente rompiendo todos los esquemas.
DeepSeek V4 acaba de publicarse hace menos de una hora con licencia MIT.
100x más barato que GPT-5.5 (que salió esta misma mañana) y 5x mas barato en su versión pro.
1M de contexto nativo.
Rating Codeforces 3206 — top 25 humano del planeta. Primer modelo open en empatar con GPT-5.4 en competitive programming.
Le gana a Claude Opus 4.6 Max en SimpleQA por 20 puntos (paliza total)
GPT-5.5 duró 12 horas como noticia.
La era del costo-efectividad en LLMs frontier acaba de empezar — y la abrió un modelo open source.
Más allá de los benchmark hay que probar los modelos y diferenciarlos en la práctica, comenzaré a publicar diferencias de resultados con los otros modelos usando los mismos prompts.
Golpe DURISIMO a Anthropic, Kimi 2.6 iguala o gana a Opus 4.6 MAX Effort en muchos benchmark. Ademas que el costo es mas de 5 veces mas bajo en salida y en entrada.
Ya se sabe que Kimi 2.5 ya fue usado como base por Cursor para su modelo Composer, claramente es un modelo MUY confiable.
Ademas ya estan los rumores que esta semana sale a la luz el nuevo Deep Seek.
#AI #Claude #China
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
Sé Anthropic:
> Lanza Opus 4.6 al público.
> A la gente le encanta.
> Durante 2 meses, degrada gradualmente el rendimiento de Opus 4.6.
> Devuélveles el Opus 4.6 original, pero llámalo Opus 4.7.
> A la gente le vuelve a encantar.
> A seguir facturando.
El propio modelo de negocio.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.