Infinite intelligence. Local. Any Hardware. Peer-to-Peer Hyper Swarm. No cloud. No compromise.
QVAC is the decentralized AI platform for humans and machines.
Yesterday we announced that the QVAC SDK update unlocked up to 5x more context on your device thanks to TurboQuant.
Today, we’ll go through how we got there.
TurboQuant (Google Research, ICLR 2026) is a two-stage KV-cache compression algorithm.
Stage 1 - PolarQuant: convert KV vectors from Cartesian (x, y, z...) to polar coordinates. Angles compress predictably down to 3-4 bits.
Stage 2 - QJL: 1-bit Johnson-Lindenstrauss correction. Cleans up residual error.
Total: ~4-5 bits per value. No retraining. No calibration.
QVAC ported it to Vulkan inside qvac-fabric-llm.cpp.
Currently, TurboQuant is supported only for AMD & NVIDIA GPUs, support for iOS, Android & Apple Silicon coming next.
Full algorithm walkthrough + benchmarks + code examples →
https://t.co/SDX4G2vDuB
🚨🤖Tether AI ships TurboQuant KV-Cache Quantization within QVAC SDK 0.12.0, compressing the KV cache memory requirements by up to 5x, near-lossless.
Effective high-quality local AI is one step closer!
If shipping things like TurboQuant sounds exciting to you & you want to push the frontier of local AI, QVAC is hiring an inference engineer.
Apply here if interested: https://t.co/T5NEsT6v1d
Your local AI just got up to 5x more memory.
Same model. Same device. Nearly zero accuracy loss.
QVAC SDK 0.12.0 integrates TurboQuant - Google Research's latest memory optimisation algorithm.
What is TurboQuant?
The KV cache is the memory your model uses to track a conversation. As context grows, it fills up fast. 32K tokens. 64K. Game over.
TurboQuant compresses it up to 5x with no accuracy loss.
What does it unlock for you?
Your app had a 16K token ceiling? It's now 96K. On the same device.
Just update the QVAC SDK to get up to 5x more efficiency.
No code changes. All from one SDK.
The TurboQuant integration unlocks sovereign intelligence for more people, on more devices.
Learn more → https://t.co/vCVuyNG5ky
If shipping things like TurboQuant sounds exciting to you & you want to push the frontier of local AI, QVAC is hiring an inference engineer.
Apply here if interested: https://t.co/T5NEsT6v1d
QVAC SDK 0.12.0 is now live, bringing longer context, increased memory optimisation, new modalities, and broader ecosystem support directly to your device.
Key Features and Updates:
- TurboQuant KV-Cache Quantization: Fit much longer context in the same memory. TurboQuant, an algorithm from Google Research, compresses the KV cache by up to 5x, near-lossless.
- Text-to-Video: Generate video from a text prompt, fully local, with the new wan2.1 model in the Diffusion addon
- Apple Metal Performance for Flux2-klein: Diffusion on Apple Silicon now matches MLX performance, the native benchmark for Apple GPUs
- Robot Control (new VLA addon): A GGML-based Vision-Language-Action addon brings fast, efficient robot control to edge devices
- Coding Assistant / Harness Support: QVAC now works with OpenCode and OpenClaw as a local provider. A new @qvac/ai-sdk-provider package automates model registry and provider integration
- Cross-Platform Voice: Text-to-speech and Parakeet transcription moved from ONNX to the GGML engine for better CPU and GPU support on macOS, iOS, Windows, Linux, and Android. Parakeet also adds long-term streaming diarization (tracking who spoke when on live audio)
- Faster Lightweight Visual Classification: A new GGML-based Classification addon delivers millisecond-level classification, useful where a vision-language model (VLM) would be unnecessarily slow
- Under the Hood: Fabric synced to llama.cpp v8828 (from v8189), plus GPU acceleration added to image-upscale models for faster results
Full release notes: https://t.co/4x25Nlsv73
Fine-tuning a 13B-parameter model used to be a data-center-only job.
Now it runs on the phone in your pocket. Our BitNet b1.58 framework fine-tunes up to 13B params on an iPhone 16, Samsung S25, or Pixel 9. GPU-agnostic, fully local.
Read more on TechCrunch: https://t.co/sYUmSIKnGF
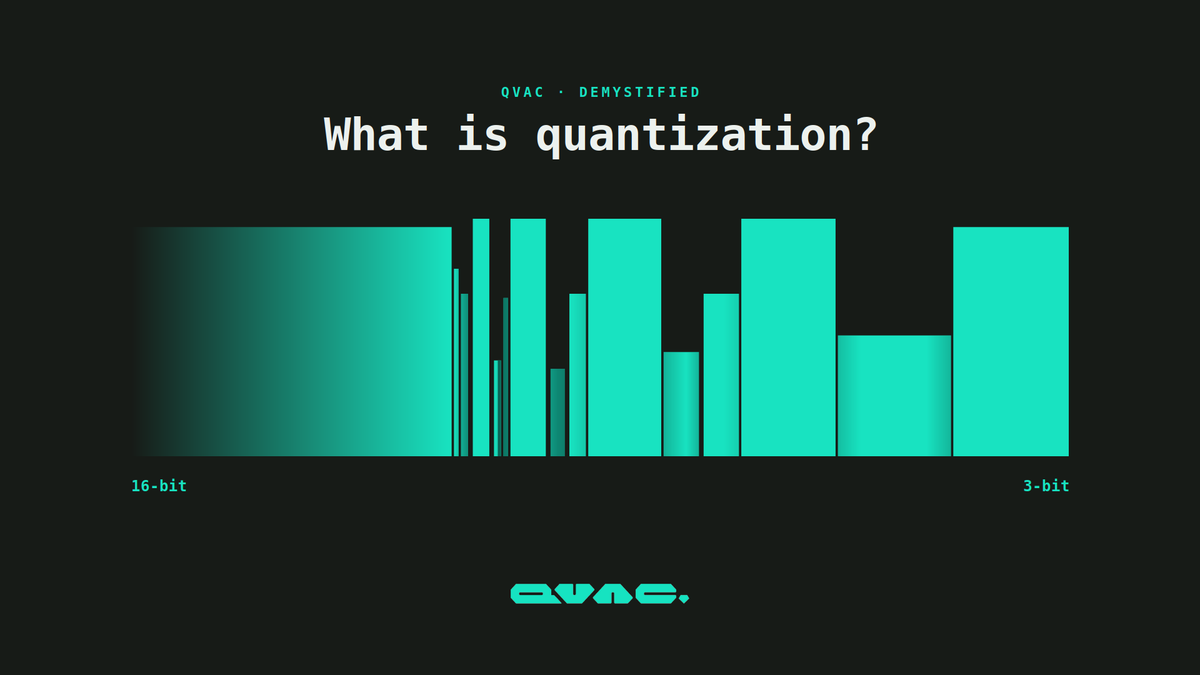
What is quantization & why does it matter?
When you hear "Llama 7B", the 7B is the model's weights: 7 billion parameters that encode everything it knows. More weights means more capable, but heavier.
Stored at the default 16 bits each, those 7 billion parameters take about 14 GB of memory.
Quantization shrinks the model by storing each weight in fewer bits. Same 7 billion weights, less space each.
Llama 7B:
16-bit: 14 GB
8-bit: 7 GB
4-bit: ~4 GB
3-bit: ~3 GB
At 4-bit it finally fits on a consumer laptop.
The catch is the precision. Rounding each weight to fewer bits introduces small errors.
Down to 4-bit the quality drop is usually hard to notice. Go lower and the model starts making more mistakes.
But weights are only the fixed cost. As the model runs, it builds a second memory called the KV cache, with an entry for every word in the conversation.
On long inputs this grows larger than the model itself, and it usually stays at full precision.
Bigger context reserves more memory, up front, on top of the weights. Too much and it drops to slow CPU or will not load.
The frontier now is compressing that running memory, not only the weights.
We have been working on exactly this. Details in a few days.
@NatX_eth That's actually a great use case of local AI and close to QVAC's vision. Technology must be designed to work when everything else fails & humans need it the most (no internet, power cuts, wartime, infra shutdown). Centralized AI is fragile by design. Local AI fixes this.
Smaller toolboxes, faster local LLMs.
QVAC now supports per-turn dynamic tools with automatic KV cache compaction: the durable conversation stays fast while completed tool-call chains get cleaned out automatically.
Read more:
https://t.co/MXeD6GK9s7
The first Official QVAC Hackathon is about to start! 💻
Build real edge-AI apps with @qvac/sdk. On-device inference, fully open-source, no cloud.
Any hardware works: phone, laptop, Raspberry Pi, whatever you have. 4 tracks, cash prizes per track + grand prize.
Total prize pool: 21,000 USD
Extra points for the teams willing to build in Public, see details on the Hackathon page.
Want to join but looking for a team? You can find teammates when you register!
📅 Dates:
Pre-registration: open
Submissions: June 1 to June 22
Winners: July 3
Sign up ➡️ https://t.co/Q6f1msBVhx
Show us what local AI can really do.