We‘ll be presenting ForeAct (🌟Highlight) at CVPR 2026:
📍 Poster: Sunday, 3:30PM, ExHall A #95
📍 NVIDIA Tech Talk: Friday, 12:40PM, Booth #211 @NVIDIAAI
Feel free to stop by and chat! Also find our coffee making demo empowered by ForeAct! (https://t.co/a58GwCbgR0)
I’ll be at #CVPR2026 from Jun 4-7. Open to chat about VLA, world models and efficient visual generation!
FlashLib update: we now support ANN search with IVF-Flat — up to 6.5× faster than cuVS on real-world vector workloads (SIFT-1M) while matching recall.
LEANN now supports FlashLib as a backend: 26× faster build, 29× faster single-query, and 298× faster batch search. Huge thanks to @YichuanM for the help!
We’re also opening Discord / Slack channels — join us to suggest new operators you want to see, and hardware backends you want FlashLib to support next!
Slack: https://t.co/BiH46PvPbH
Discord: https://t.co/6sfTJKkLtG
We released a blog on "Why Video Gen Is an Infra Problem".
https://t.co/VZFb6L838c
We discuss why long video generation requires full-stack co-design across models, memory, KV cache, VAE decoding, scheduling, and deployment infrastructure, with LongLive 2.0 (https://t.co/QXF2lfolpj) as a case study.
Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
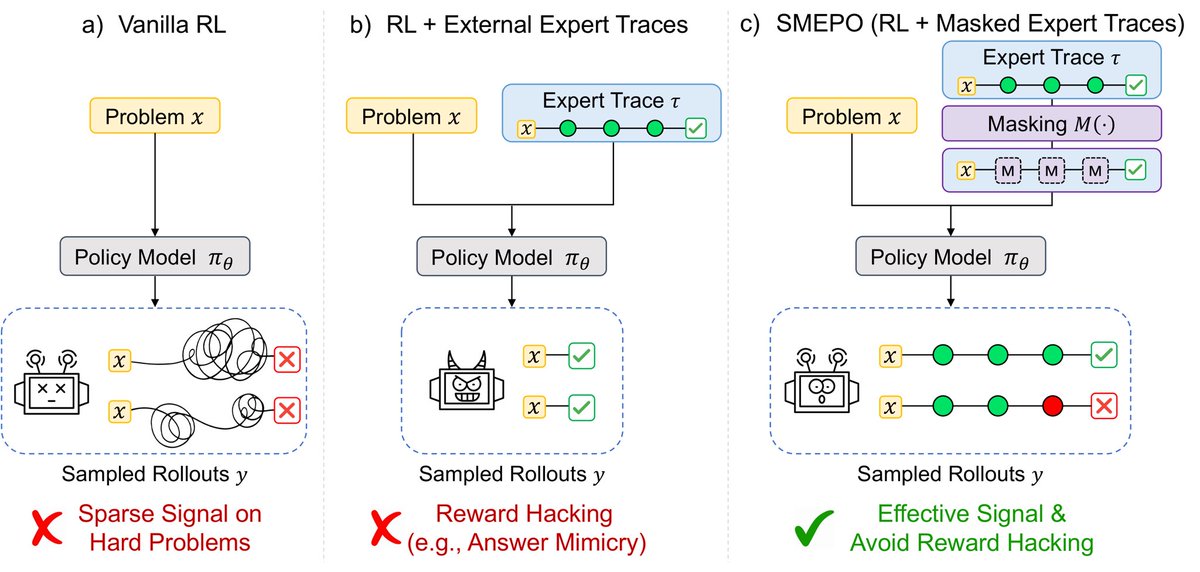
Expert traces can guide RLVR, but full traces may leak key values, executable code, or answer entities — creating an unintended reward-hacking channel.
We propose SMEPO: Semantic Masked Expert Policy Optimization.
Paper: https://t.co/55uoo9rGTw
Code: https://t.co/AH8BiTdpPc
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: https://t.co/P31SGl0cyT
Code: https://t.co/9nkO2hmeOl
🚀 LongLive 2.0 just got faster!
Since last week’s release, we further optimized the NVFP4 inference path and improved the overall throughput by 18.6%.
🔥Now, generating a 64s video takes only 30.6s end-to-end, including VAE decoding.
⚡⚡That’s over 2× real-time generation.
🛠️ What changed under the hood?
• Fused Triton RoPE / adaLN kernels
• Reduced KV-cache synchronization overhead
• In-place quantized KV-cache updates
• Faster FP4 KV dequantization
• Pinned VAE transfers
• Safer LoRA-before-quantization setup
🎬 LongLive 2.0 is our open-source 4-bit long-video generation infra for both training and inference.
🚀 We are continuing to push long-video generation toward faster, lighter, and more practical deployment.
🔗 Code: https://t.co/QXF2lfnNzL
#LongVideoGeneration #VideoGeneration #Realtime #AIInfra #EfficientAI #FP4 #Parallel #NVIDIA
Long video generation is a systems problem.
Introducing LongLive-2.0 from NVIDIA Research: an end-to-end NVFP4 training and inference system for long video generation.
Low-precision deployment often relies on post-training quantization, creating a gap between how models are trained and how they run.
LongLive-2.0 aligns NVFP4-aware training, distillation, and W4A4 inference, maintaining strong benchmark quality while improving speed and memory efficiency.
We’re releasing Nemotron-Labs-Diffusion - the first Tri-mode LM family (3B/8B/14B) that switches between 1⃣Autoregressive, 2⃣Diffusion, and 3⃣Self-Speculation decoding by simply changing the attention pattern/mask.
One model Three decoding modes. No extra draft models. No architecture changes. Just significantly better efficiency across different concurrency levels.
Up to 4× higher real throughput for a single user.
🤗 HF Collection: https://t.co/1zStcCCWPi, open license
🛜 Project page: https://t.co/y6TEAvLFvD
📰 Tech report: https://t.co/NSjKxEyHnT
Details below 👇
🚀 Excited to release LongLive 2.0!
🎬 An end-to-end infrastructure for long video generation, with FP4 and parallelism at the core of both training and inference.
⚡45.7 FPS generation speed on 5B model⚡
✨ LongLive 2.0 supports real-video training, few-step distillation, multi-shot training/inference, sequence-parallel acceleration, NVFP4 KV cache, and async VAE decoding deployment.
🧩 To our knowledge, this is the first open-source 4-bit long video generation infra that covers both training and inference.
🙌 Welcome to check it out, try it, and share feedback!
🔗 Code: https://t.co/QXF2lfnNzL
📰 Paper: https://t.co/gKtarHj17c
🎥 Demo: https://t.co/RLF1wfOXVZ
#LongVideoGeneration #VideoGeneration #Realtime #AIInfra #EfficientAI #FP4 #Parallel #NVIDIA
One image + text + camera trajectory = controllable worlds. All on a single GPU.
Our research team just released SANA-WM, a 2.6B open source world model natively trained for 60-second video generation with precise camera control.
🚀 BLASST just won Best Paper at #MLSys26!
In this paper, we introduce a simple, training-free dynamic sparse attention mechanism that uses a single scalar threshold on online softmax statistics to skip negligible attention blocks.
Unfortunately I won’t be there in person, but please say hi to my awesome coauthors! 🙌
Paper: https://t.co/HDDHDqKRTT
🤩Excited to share SANA-WM: a 2.6B open-source world model for minute-scale 720p video generation.
Given one image + text + a 6-DoF camera trajectory, it synthesizes action-controllable 60s worlds on a single GPU.
Project: https://t.co/5NINfiFoTK
Paper: https://t.co/JKczmyRsJL
🚀 We are excited to announce the release of AnyFlow, the first any-step video diffusion on-policy distillation (OPD) framework. By leveraging Flow Map distillation, AnyFlow significantly enhances model inference efficiency by reducing sample steps. (Code, models, and demos are now open-source!)
Key Highlights:
⚡ Any-Step Generation: Unlike traditional distilled models tied to fixed step budgets, AnyFlow enables a single model to adapt to arbitrary inference budgets. It achieves high-quality few-step generation while providing stable improvements as more sampling steps are added.
🔀 Multiple Architectures: AnyFlow supports any-step distillation for both causal and bidirectional video diffusion models.
🎬 Multiple Tasks: AnyFlow supports Text-to-Video, Image-to-Video, and Video-to-Video generation within one causal video diffusion model.
📈 Scalable Performance: AnyFlow is validated from 1.3B up to 14B parameters.
📄 Paper: https://t.co/Qqik8l29oB
💻 Code: https://t.co/KOMv9RtuWu
🎨 Pre-trained Models: https://t.co/Br1MNllUu8
🎬 Demo: https://t.co/hxbl56lPFU
NVIDIA just released AnyFlow on Hugging Face
The first any-step video diffusion model that generates high-quality text-to-video with any inference budget - 4 steps or 50, quality scales smoothly without degradation.
On-policy distillation (OPD) is one of the most effective LLM post-training methods, but it traditionally requires a costly live teacher server throughout training.
In our latest work, Lightning OPD, we show that OPD can be performed fully offline by precomputing teacher log-probabilities before training, reducing OPD to a standard single-model training job.
A key insight is Teacher Consistency: the SFT teacher and OPD teacher must be identical. Otherwise, offline OPD suffers a significant accuracy drop.
Paper: https://t.co/zTW3mm2wWX
Code: https://t.co/7iOB8LezVQ
Contributors: Yecheng Wu, Song Han, Han Cai
DFlash for Gemma 4: Up to 6x Faster. ⚡⚡
Great to see MTP land natively in Gemma 4 today. If you want to push it further, try DFlash — open source, same quality, more speed!!
https://t.co/wKcRoibuOB