Foundation Update for the Spheron Community
The team has been working closely to align the foundation's structure with Spheron AI, making sure the foundation's IP is being put to good use. So far, results on the enterprise GPU capacity side have been strong.
We're now focused on aligning the incentive structure between the foundation and the team to keep everything running smoothly as we scale. Our focus has always been the long-term play, not short-term gains.
In line with that, the foundation has decided to extend team vesting by one additional year. Tokens originally scheduled to unlock for the team now have an extended cliff of one more year. This keeps all stakeholders aligned for the longer term.
A lot is happening behind the scenes. As we grow, we'll keep the community posted. Right now, the foundation's full focus is on Spheron AI's success. The foundation's growth story is directly tied to Spheron AI's momentum in the enterprise GPU space.
We're all in. More updates soon.
This is exactly why flexible access with renting option for GPUs matters more than ownership.
When memory and compute are both scarce, locking capital into hardware becomes risky. The teams that keep moving will be the ones that can tap into global GPU supply on demand and scale without waiting on supply chains to catch up.
This year, there won’t be enough memory to meet worldwide demand because powerful AI chips made by the likes of Nvidia, AMD and Google need so much of it. https://t.co/B9lYo3PO2e
This is exactly what people miss when they talk about “just build more GPUs.”
AI is no longer competing only with AI. It is competing with every consumer device for the same memory supply.
When a single NVIDIA AI GPU generation can consume as much memory as 100–150 million smartphones, scarcity stops being theoretical. It becomes systemic. Phones get more expensive. PCs get more expensive. And AI infra gets locked behind whoever can secure supply first.
This is why access matters more than ownership.
Most teams cannot afford to bet millions on hardware that depends on fragile memory supply chains and long lead times. But they still need to train, fine-tune, and run models now, not in 2027 when new fabs come online.
At @spheron, we work around this reality by aggregating global GPU capacity across providers and regions. Instead of forcing teams to chase scarce hardware, we give them flexible access to what already exists, when they need it, at market-driven pricing.
Memory is becoming the real bottleneck. Compute is becoming a strategic resource. And the teams that win will be the ones that stay flexible instead of trying to own everything in a tightening supply cycle.
If smartphones are about to feel this pressure, AI builders already are.
Source: https://t.co/7nBI0nvoNR
AI demand is growing faster than hardware can keep up. Building larger data centers alone won’t solve that gap. It just concentrates cost and risk.
The real unlock is compute. Tapping into global GPU supply, closer to where teams actually build and deploy.
That’s exactly what we’re seeing on the ground.
Most teams don’t “run out of ideas,” they run out of usable compute. Once a model starts serving users, inference quietly eats the budget, and research gets squeezed. So companies shift focus from improving the model to wrapping products and ecosystems around whatever they already trained.
At Spheron, teams split these workloads cleanly. They train on high-performance GPUs when they need to push the model forward, then move inference to cost-efficient instances without locking capital or overpaying.
That separation is what keeps research alive while products scale.
Compute strategy is becoming product strategy.
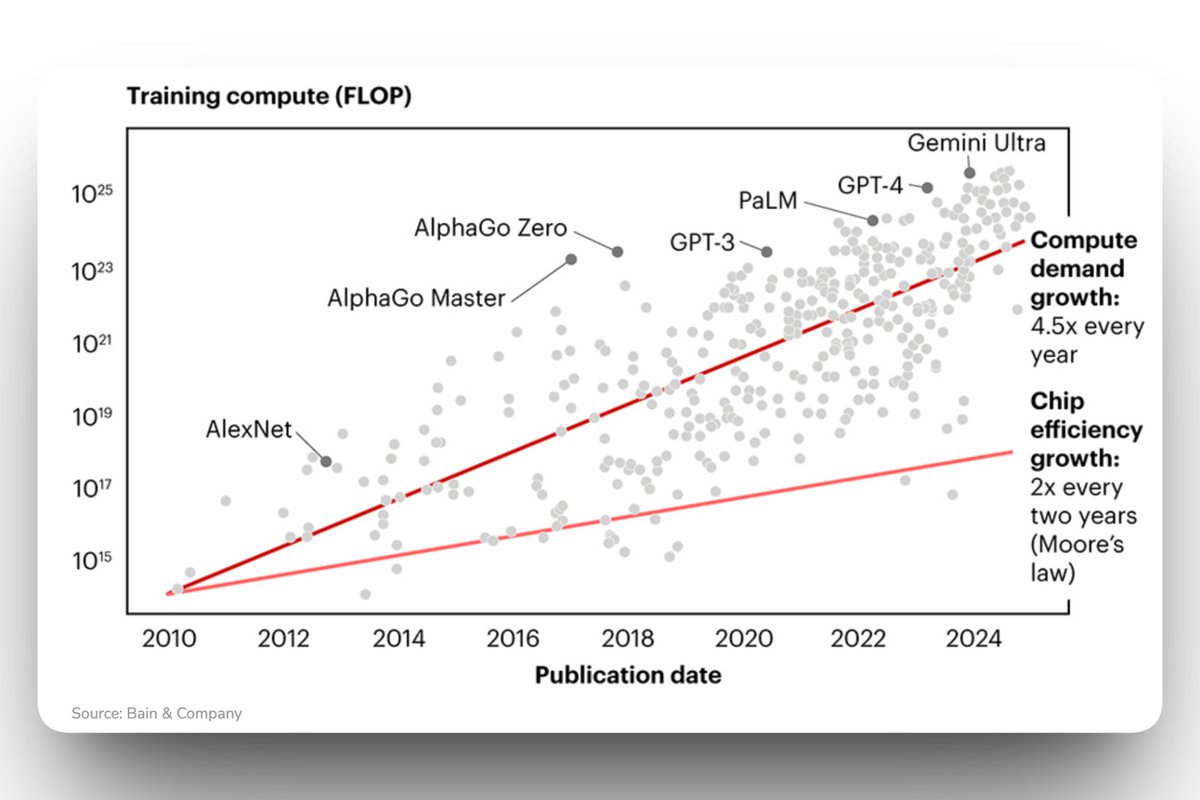
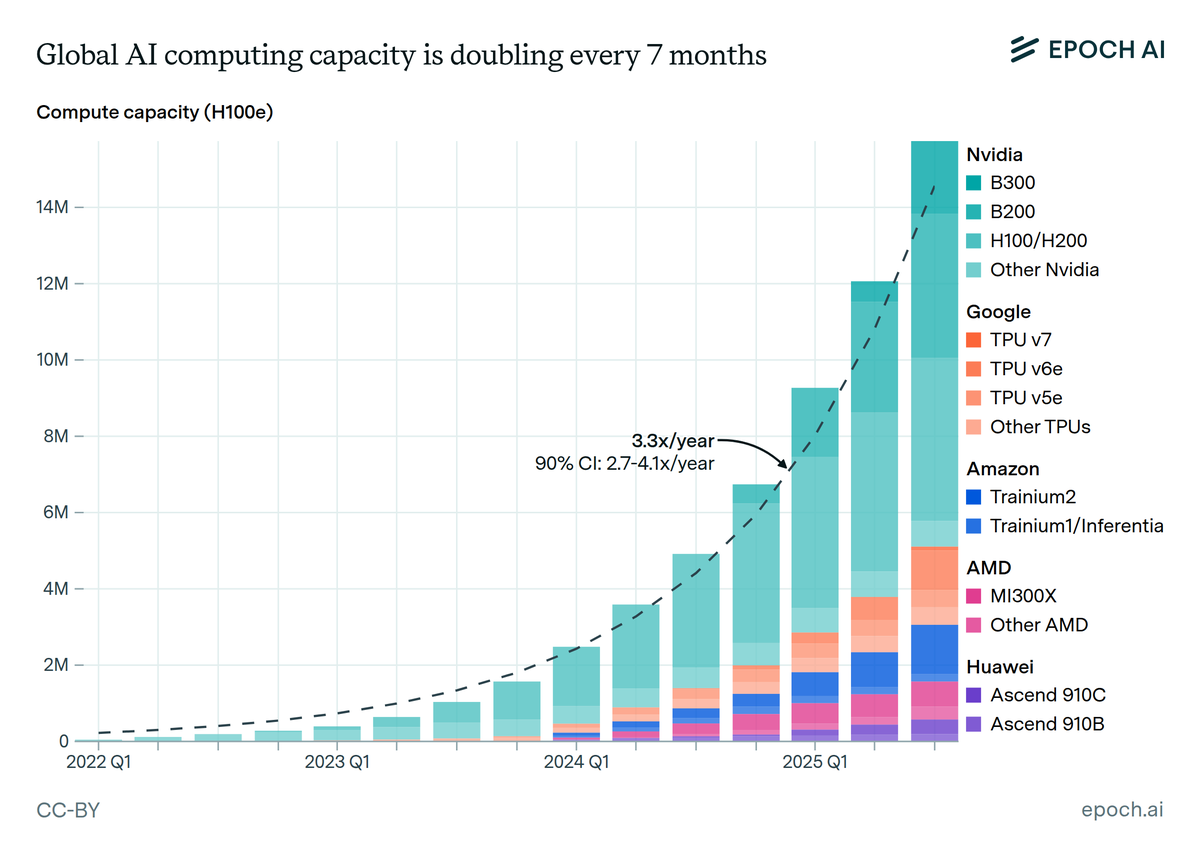
Total AI compute is doubling every 7 months.
We tracked quarterly production of AI accelerators across all major chip designers. Since 2022, total compute has grown ~3.3x per year, enabling increasingly larger-scale model development and adoption. 🧵
AI adoption is happening inside products people already trust. That changes how AI actually runs in the real world.
Instead of big, one-off experiments, we’re moving toward AI that runs quietly in the background. Always on. Always available. Embedded into existing apps and workflows.
That shift puts the focus back where it belongs: infrastructure.
When AI becomes part of everyday software, teams need compute that is reliable, predictable, and flexible. Not tied to a single platform. Not locked behind long contracts. Not priced for hype cycles.
That’s the problem Spheron is built to solve. We provide access to enterprise GPUs so teams can support steady, real-world AI usage no matter where the interface lives.
The UI will change. The models will change.
Compute remains the constant.
Everyone keeps asking if AI browsers are about to replace Chrome. I don’t see it happening anytime soon.
We already have browsers people trust. Unless someone builds something truly new and wild, most users aren’t switching. Google will just absorb AI into what already exists, and ChatGPT will likely live inside Chrome, not replace it.
The bigger issue is trust. If people don’t trust an AI to protect their data, they’re not letting it log into their bank, shop for them, or make decisions on their behalf. That skepticism isn’t going away fast, which means adoption will be slower than the hype suggests.
AI isn’t losing. It’s just going to show up everywhere quietly, not take over overnight.
#AITrends #TechTalk #FutureOfAI #DigitalTrust #ProductAdoption
The new year has already brought unexpected shifts.
AI infrastructure is changing faster than most people realize.
And in this market, paying $5,000 per GPU makes little sense when you can access the same compute at $0.55/hour.
AWS just raised H200 pricing by ~15%.
Our prices stayed cheaper and affordable as always.
While hyperscalers keep pushing compute costs up, we’re doing the opposite: giving teams access to the same enterprise GPUs without the enterprise tax.
Teams switching to Spheron are already saving up to 80% on GPU spend.
The shift happens when people realize:
you don’t need hyperscalers to run serious AI.
Amazon $AMZN AWS has raised pricing for EC2 Capacity Blocks for ML by about 15%, with H200-based p5e.48xlarge moving from $34.61 to $39.80 per hour in most regions and p5en.48xlarge from $36.18 to $41.61, while US West (N. California) p5e went from $43.26 to $49.75 - The Register
Enterprise GPUs. Without enterprise pain.
So you can Build faster and Pay less.
Spheron is built for teams actually shipping AI. Spin up instances in minutes, pay up to 70% less than hyperscalers, and run on real enterprise GPUs with predictable pricing.
Most startups think fine-tuning is only for teams with million-dollar ML budgets. That idea did not come from reality. It came from how AI infras has been sold for years.
The truth is simpler. Fine-tuning does not need bloated setups, long contracts, or enterprise-only platforms. It needs clear pricing, easy access to GPUs, and the freedom to iterate fast.
What actually breaks startup AI budgets is not ambition. It is:
- Procurement calls.
- Locked contracts.
- Unclear pricing.
- Slow access to compute.
Smart teams are moving away from platforms built for big logos and moving toward infra provider built for speed. Places where they can spin up, experiment, fine-tune, deploy, and repeat without waiting weeks or guessing costs.
That is exactly how @spheron is designed.
On Spheron, fine-tuning is treated like what it really is: a normal step in building AI. You get real GPUs, transparent pricing, spot and on-demand options, and the ability to start small and scale only when your data proves it makes sense.
If your biggest bottleneck is not the model but the cloud around it, the problem is your infrastructure.
AI workflows should have worked this way from day one.
If your AI training keeps crashing, slowing down, or costing more every week, the problem usually isn’t your model. It’s the GPU.
Most teams don’t need the newest GPU on the planet. They need one that works reliably, and doesn’t blow up the budget. That’s why NVIDIA A100 matters
If you’re tired of paying premium prices for GPUs you don’t fully use, A100 is still one of the smartest choices in AI
And if you want it without contracts, hidden fees, or vendor games, Spheron makes it simple.
https://t.co/kiIicnq8P4
@ViralManager@runpod Try Spheron, dedicated instances stay up as long as you are running them. No forced GPU moves, no surprise shutdowns, unless your balance hits 0. If you want stable, long running GPUs without daily migrations, give us a try.
https://t.co/f83sKO4jOO
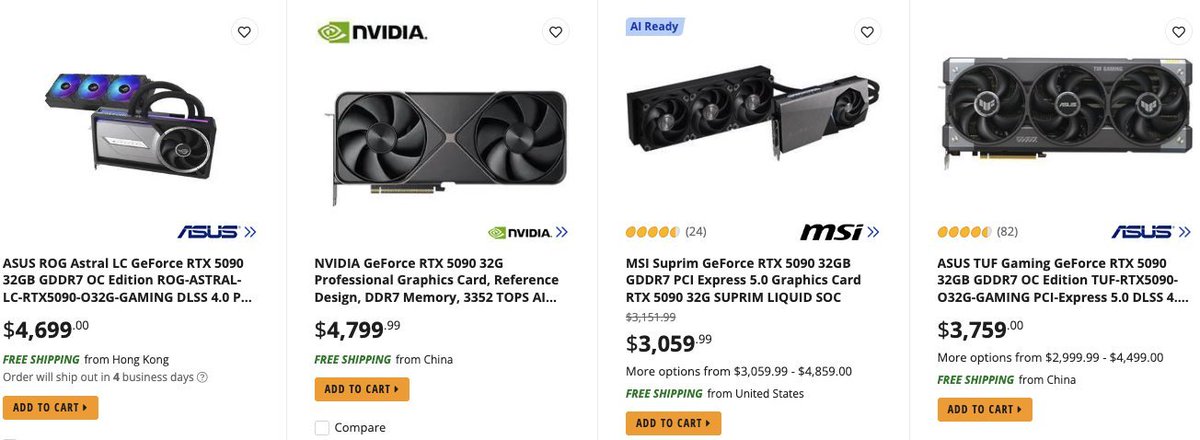
Reports suggest NVIDIA and AMD are preparing another round of GPU price hikes starting this month.
Early signs already look worrying. The RTX 5090 is expected to jump from around $2,000 to nearly $5,000. And this does not stop at one model. According to the report, both companies may continue raising prices month after month, across their entire lineup.
That includes consumer GPUs, AI accelerators, and server-grade hardware.
This matters because it confirms what many teams are already feeling. Owning GPUs is becoming riskier and more expensive, not just upfront but over time. Price volatility, supply constraints, and long replacement cycles make hardware ownership a liability.
This is exactly why access beats ownership. As GPU prices climb, flexible compute like renting is no longer a nice-to-have. It is the safer default.
Source: https://t.co/9t3cZrxL9k
Reports suggest NVIDIA and AMD are preparing another round of GPU price hikes starting this month.
Early signs already look worrying. The RTX 5090 is expected to jump from around $2,000 to nearly $5,000. And this does not stop at one model. According to the report, both companies may continue raising prices month after month, across their entire lineup.
That includes consumer GPUs, AI accelerators, and server-grade hardware.
This matters because it confirms what many teams are already feeling. Owning GPUs is becoming riskier and more expensive, not just upfront but over time. Price volatility, supply constraints, and long replacement cycles make hardware ownership a liability.
This is exactly why access beats ownership. As GPU prices climb, flexible compute like renting is no longer a nice-to-have. It is the safer default.
Source: https://t.co/9t3cZrxL9k