Ideogram 4.0: Why It Matters
Ideogram 4.0 combines layout control, typography, and local deployment in one model.
- Better text than most image models
- More precise composition
- More practical for creators who want control
This is one of the most useful open-weight image releases right now.
Follow for more
#AINews #ArtificialIntelligence #OpenSource
Ideogram 4.0 is here.
The model brings better text rendering, stronger layout control, and local workflows that make real design work easier.
Here is everything that matters.
#AINews#ArtificialIntelligence#OpenSource
Ideogram 4.0: Local Workflow
The ComfyUI workflow is designed for local use on your own hardware.
- Resolution and aspect ratio are configurable
- Layout can be edited before generation
- CPU offloading helps with smaller VRAM setups
This turns the model into a practical tool for repeated creative work.
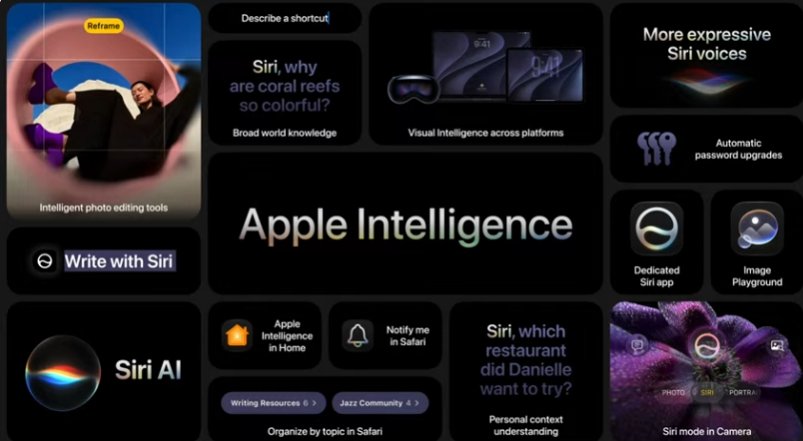
The next generation of Apple Intelligence powers an entirely new Siri: making the apps and experiences you rely on across iPhone, iPad, Mac, and Apple Vision Pro more personal and helpful than ever.
Meet Kimi Work - a local AI agent on your desktop that does the work for you.
🔹Native agent swarm: Up to 300 AI agents running in parallel on your local machine.
🔹Browser use: Paired with WebBridge extension, your agent will navigate websites in your browser: search, scroll, click, type and complete tasks.
🔹Built for Finance: Native global market data tool call from Yahoo Finance and World Bank - no complex API setup required.
🔹Memory system: Kimi Desktop keeps a running diary of your preferences, past decisions, and context to know you better.
Available for macOS (Apple Silicon) and Windows.
🔗Try it now: https://t.co/yhiai2VWIy
Kimi Code just got a big upgrade and the video as coding context feature is honestly wild. drag in a screen recording and it turns it into code. the coding agent space is getting really interesting
Gemini 3.5 Pro leaks and honestly it sounds a bit underwhelming so far. laziness on long tasks is still a problem, and pricing is going up too. better vision and multimodal stuff is nice but mid-June feels far away for this level of improvement
Apple Intelligence looks actually interesting this time but locking it to iPhone 17 Pro only is a weird move. and then the EU missing out again is just frustrating at this point
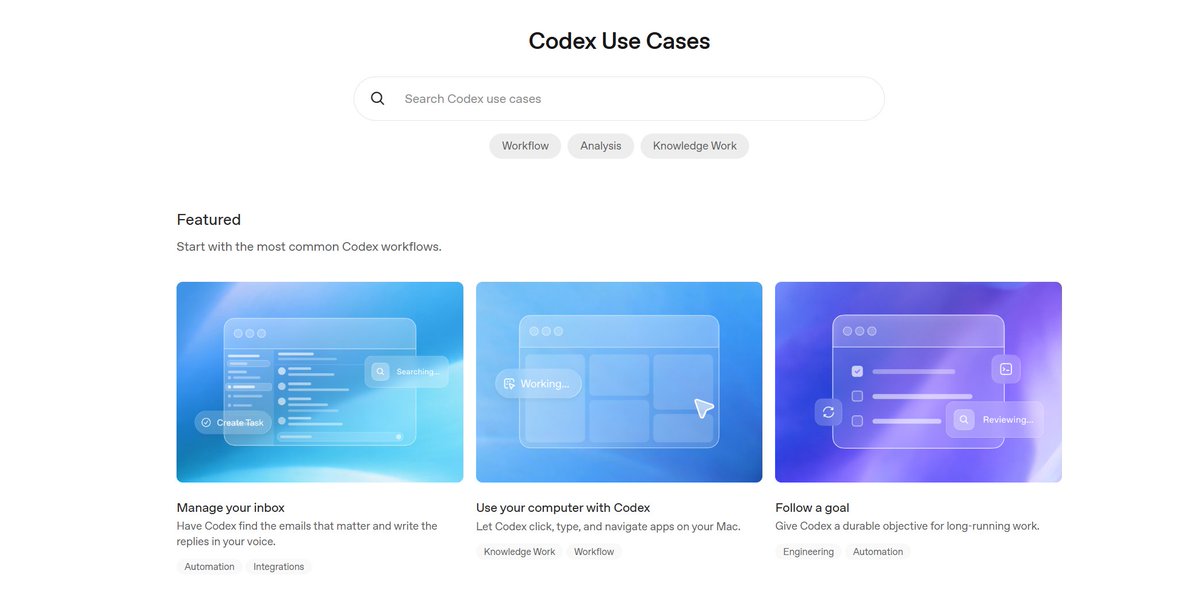
I think a lot of people still picture coding agents as something that helps you autocomplete code. but the Codex use cases page tells a very different story. engineering work, product work, QA, security, data analysis, internal tools and life sciences workflows. real teams are handing all of this over to agents and it's actually working. we're past the demo phase
Microsoft MAI-Thinking-1 and MAI-Image-2.5
Microsoft launched MAI-Thinking-1 and MAI-Image-2.5 at Build 2026, continuing its push to build a complete first-party AI model stack independent of OpenAI.
- MAI-Thinking-1: 35 billion active parameters, approximately 1 trillion total parameters in a mixture-of-experts architecture
- 256,000-token context window
- Trained from scratch on clean commercially licensed data without any third-party model distillation
- Competes with Claude Opus 4.6 on software engineering benchmarks according to Microsoft
- Available in private preview through Microsoft Foundry, OpenRouter, Fireworks AI, and Baseten
- MAI-Image-2.5 handles image generation as part of the same four-model Build 2026 release alongside MAI-Voice-2 and MAI-Transcribe-1.5
Building a reasoning model without distillation from existing frontier models is the harder and more credible path, and MAI-Thinking-1 is the first evidence Microsoft has chosen it.
Follow for more
#AINews #ArtificialIntelligence #MachineLearning #OpenSource
The open-source AI wave just hit harder than ever.
ByteDance drops a video editor that rivals Gemini. Google ships a playable music AI. NVIDIA releases three major open models. ChatGPT learns to dream. Microsoft bets on quantum.
Here is everything that matters.
#AINews #ArtificialIntelligence #OpenSource
NAVA - Baidu Native Audio-Visual Generation
Baidu ERNIE team released NAVA, a 6.3-billion-parameter model for jointly generating video and audio with native synchronization rather than adding audio as a post-processing step.
- 6.3B parameters
- Generates video and audio together in a single forward pass with native alignment
- Handles multi-speaker dialogue scenes
- Builds on Wan 2.2 video and LTX 2.3 audio architectures
- Achieves state-of-the-art audio-visual synchronization at its parameter count
- Research code available via Hugging Face
Generating audio and video in one pass rather than sequentially is the architectural change that makes synchronization reliable at the frame level.