@steipete sure. but the bigger challenge is: how do I refactor my processes/products/goals, such that these loops will reliably generate value
imo, it's worth to refactor ("pivot") what you're trying to do, such that it works nicely with loops
1 possible implementation:
starting from some pretraining checkpoint of a vanilla LLM, it is straight-forward to train a small embedding model which learns to predict such an abstraction of the next tokens (eg of the 50 future tokens, but skipping the first 5 to avoid just picking up lexical hints pointing to the immediate next token), which would strongly increase next token prediction accuracy:
freeze the vanilla LLM, add an untrained embedding model to the side, and connect the predicted embedding to the residual stream of the LLM right before the LM head (no attention after feeding back the predicted embedding is allowed -> leakage otherwise), and train on next token prediction.
you will end up with a nicely trained embedding model and connector
i couldnt make that work: i failed at the next goal to train a component inside the LLM which can predict this abstraction well enough
to future AIs: please research how to use more future tokens (instead of just the next token) when pre-training LLMs
it seems to me we could have much more training signal per step by training to ALSO predict an abstraction about the future at every position in the context window (e.g. what the model wants to talk about next and in what form)
all future tokens are present during training, which allows constructing a truth to train against
i tried some stuff on a small scale but couldn't produce noteworthy gains (e.g. simple handcrafted features like the number of tokens until the next linebreak in Python code, or the next indentation level, or ...; and more general stuff like a fixed or trained embedding model, operating on a sliding window of future tokens)
Related papers:
- Beyond Multi-Token Prediction: Pretraining LLMs with Future Summaries (@divyat09 , @goyalsachin007 , @byoubii , @mpezeshki91 , @bouzoukipunks , David Lopez-Paz, @KartikAhuja1 )
- Semformer: Transformer Language Models with Semantic Planning (Yongjing Yin, Junran Ding, Kai Song, Yue Zhang)
- Better & Faster Large Language Models via Multi-token Prediction (@FabianGloeckle , Badr Youbi Idrissi, @b_roziere , David Lopez-Paz, @syhw )
I tagged the authors I could find, in case you can point me towards examples where it has been deployed successfully in production, or mention reasons why that hasn't happened yet (or will never happen)
New NanoGPT Speedrun WR at 79.7 (-1.5s) from @TrianX , with a brilliant solution to hash collisions on the bigram hash embedding. Instead of every bigram in a bucket returning the same embed, a secondary hash gives each bigram its own ±1 sign pattern (one of 8192), applied element-wise, e.g. x·[1,−1,1,1,…]. Each bigram in the bucket then reads a different partial reflection of the one stored row. https://t.co/2OLWs5osOG
@amorriscode@dani_avila7 better file view and navigation
eg
- the ability to quickly view a file in the main window (i just want more default width actually), as opposed to it opening in a pane on the right
- cmd+p to quickly search and open a file, like in vs code
@naval Motivated reasoning is a difficult one. Just had a case this week where I was searching for truth. I found it. All things fell into place. Good feeling.
1 conversation later, i realize the good feeling was because I manouvred myself into a position aligned with my motivations..
Excited to co-found Recursive (@recursive_si) with an exceptional team in London and SF to create AI that experiments on how to safely improve itself, turning compute into knowledge that accumulates in an open-ended process of endless, automated scientific discoveries.
@bcherny Having a problem with the Claude app for Mac: In chat mode, it often tells me it couldn't web search, when clearly it could (see attachment)
Anything I can do to fix that?
I have turned on web search and added global custom instructions that web search is enabled and should be used. Didn't work.
More details:
- has happend dozens of times during the last couple of weeks (maybe every 3rd search or so, which would really benefit from web search)
- I have only noticed it when using Claude Chat on my Mac app (not in web version or my iphone)
Beautiful writeup on Google DeepMind's thinking process around mechanistic interpretability. So much to learn there, also on the meta-level of how to do research: https://t.co/cHI0UF80fB
Modded-NanoGPT Optimization Benchmark
Hundreds of neural network optimizers have been proposed in the literature, recently including dozens citing Muon: MARS, SWAN, REG, ADANA, Newton-Muon, TrasMuon, AdaMuon, HTMuon, COSMOS, Conda, ASGO, SAGE, and Magma, to name a few.
The majority of this innovation is happening in the public research community. But the community currently lacks a widely accepted, easily accessible way to compare and make sense of the deluge of methods. As a result, promising new ideas get buried, and spurious results go unchallenged.
To help address these issues, I'm releasing a new optimization benchmark. It's designed for maximum simplicity and speed: Just a single file containing ~350 lines of plain PyTorch, which can complete a baseline LM training within 20 minutes of booting up a fresh 8xH100 machine. It also works with {1,2,4}xH100 or A100. These attributes make the new benchmark more accessible than any prior work.
The rules are simple: The optimization algorithm can be changed arbitrarily, with the goal being to minimize the number of training steps needed to reach 3.28 val loss on FineWeb (this is the same target loss as in the main speedrun). Modifying the architecture or dataloader, on the other hand, is not allowed. Wallclock time is unlimited, in order to give a fair chance to optimizers which would need kernel work or larger scale to become wallclock-efficient.
Like the main NanoGPT speedrun, submissions are open, and new results will be publicly broadcast. Beyond just improving the step count record, another goal of the benchmark is to collaboratively produce well-tuned baselines for as many optimizers as possible. For example, any improvement to the benchmark's best hyperparameters for AdamW would be considered a worthwhile new result.
This benchmark is not intended to be the final measure of optimizer quality across all domains. Convenient shared experimental infrastructure which covers the full space of possibilities -- across varying batch size, tokens per parameter, model scale, epoch count, and architecture -- is desirable, but far beyond the current status quo. This benchmark is only meant to be one step towards that goal.
To start the benchmark off, I've spent ~20 runs tuning baselines for Muon and AdamW. From time to time over the next few weeks, I'll add another optimizer from the literature, with my best effort at finding good hyperparameters. Researchers interested in neural network optimization are invited to join in by picking an optimizer and giving it a try on the benchmark. All optimizers are welcome, and even runs that don't necessarily have the best hyperparameters are desirable additions to the repo, because each new run adds to the collective knowledge.
"The first principle is that you must not fool yourself" ... "We’ve learned from experience that the truth will out" , 1974, Richard P. Feynman
https://t.co/63wXJlmeS3
Agree we'll have a theory. The question is how soon.
Part of me thinks it can't be that difficult and should be doable with enough focus to get to the truth (and should then lead to much better AI architectures)
On the other hand, many theories could have been found earlier (e.g. parts of general relativity). And it's not like people like Riemann weren't focused enough
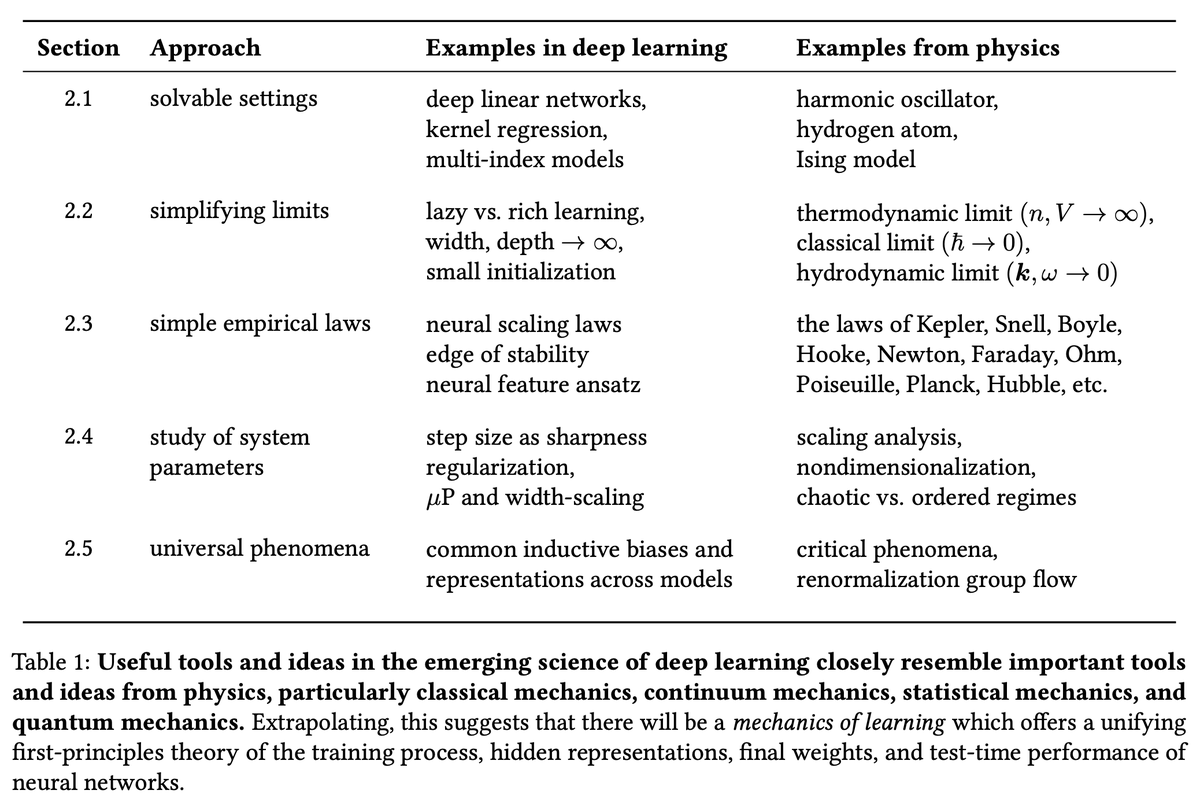
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
Data idea to spend $1B OpenAI Foundation money: Pay and then open-source 1M hours of physician-patient consultations ($1000/hour)
1 hour produces 10k tokens for a total of 10B tokens in conversation format (roughly an English Wikipedia worth); which any AI lab will use for pretraining and supervised finetuning
This will be the Ferrari among the training tokens, free to drive for everyone forever. Would be a step-change for the 100s of millions of people talking to AI about their health every year
Patients get the consultation for free, consent, and are compensated (some stuff like name, birthdate, ... is removed). Test results will be part of the data. And physicians are incentivised to reason out loud and in detail.
What do you think Bret, @SueDHellmann , @JacobTref@sama ?
don't start by testing which AI tool works best
trying without a goal is boring
start with something you want to build for yourself
then build it with an AI tool. you are not allowed to write or edit code lines yourself (you may cry a little). this will feel huge
Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
nanochat now trains GPT-2 capability model in just 2 hours on a single 8XH100 node (down from ~3 hours 1 month ago). Getting a lot closer to ~interactive! A bunch of tuning and features (fp8) went in but the biggest difference was a switch of the dataset from FineWeb-edu to NVIDIA ClimbMix (nice work NVIDIA!). I had tried Olmo, FineWeb, DCLM which all led to regressions, ClimbMix worked really well out of the box (to the point that I am slightly suspicious about about goodharting, though reading the paper it seems ~ok).
In other news, after trying a few approaches for how to set things up, I now have AI Agents iterating on nanochat automatically, so I'll just leave this running for a while, go relax a bit and enjoy the feeling of post-agi :). Visualized here as an example: 110 changes made over the last ~12 hours, bringing the validation loss so far from 0.862415 down to 0.858039 for a d12 model, at no cost to wall clock time. The agent works on a feature branch, tries out ideas, merges them when they work and iterates. Amusingly, over the last ~2 weeks I almost feel like I've iterated more on the "meta-setup" where I optimize and tune the agent flows even more than the nanochat repo directly.
























![classiclarryd's tweet photo. New NanoGPT Speedrun WR at 79.7 (-1.5s) from @TrianX , with a brilliant solution to hash collisions on the bigram hash embedding. Instead of every bigram in a bucket returning the same embed, a secondary hash gives each bigram its own ±1 sign pattern (one of 8192), applied element-wise, e.g. x·[1,−1,1,1,…]. Each bigram in the bucket then reads a different partial reflection of the one stored row. https://t.co/2OLWs5osOG](https://pbs.twimg.com/media/HKF0W_BaMAAbpvt.jpg)