Next we have @mohitban47 from @UNC. Mohit need no introduction he is an expert on multimodal data. He is also winner of multiple national/international awards.
🚨 GPU Forecasters 👉 we explore if a reasoning model can be a selective world model of a GPU, forecasting a kernel's speed while deferring to real hardware when unsure, making kernel search more efficient.
Inside an evolutionary kernel search, the surrogate lets us explore many more candidates in imagination and run only the most promising on the GPU. We often find kernels as fast or faster using the same number of real GPU evaluations.
We also show that reinforcement learning with calibration rewards can teach the surrogate to know when it doesn't know, making it more reliable during search.
We see this as early work toward approximate world models of complex hardware-software systems!
🧵 👇
Can an LLM act as a selective model of a GPU during evolutionary search, by reasoning + forecasting a kernel’s runtime but deferring to a GPU when unsure? We produced 12k kernels + runtimes from evolutionary search, costing 400M reasoning tokens + 600 GPU-hours to answer this.
In our work GPU Forecasters, we study language models as selective surrogates for GPU kernel optimization.
1️⃣ Off-the-shelf LLMs can forecast how a GPU responds to a candidate kernel with non-trivial accuracy. If we rank candidates by these predictions and measure only the top 10% on a GPU, the fastest kernel we find is within 20% of the best in the pool.
2️⃣ We want LLMs to not just be accurate but also calibrated, so that we can use their uncertainty for selective prediction: during search, we should trust only confident forecasts and verify less confident forecasts by sending them to the GPU.
3️⃣ We train an open-weights surrogate (GPT-OSS-20B) with RL to improve both accuracy and calibration. Calibration-shaped rewards improve both confidence reliability and ranking ability, while correctness rewards alone do not.
4️⃣ Inside a real kernel search, the surrogate finds faster kernels than an equal-GPU-budget baseline by considering more candidates per measurement.
5️⃣ We release 12,388 LLM-generated GPU kernels with measured runtimes spanning 118 operations, CUDA and Triton backends, 3 GPU types, taking 400M tokens + 600 GPU-hours to produce. This dataset can be used for analyzing LLM-driven evolutionary program search dynamics, post-training LLMs for kernel code generation, and things we didn’t get a chance to explore, like training reward models!
Thread 🧵👇
👀 Seeing ≠ 🤔 Knowing in VLMs for Spatial Reasoning, which is not just about finding the right answer -- but about understanding whether the available evidence supports an answer at all (and if not, why?)
SpatialUncertain evaluates if VLMs can:
(1) recognize "spatial uncertainty" caused by occlusion & misleading perspective, and
(2) also understand what additional info/viewpoint is needed to resolve the uncertainty.
Details 👇
🚨 Excited to share SpatialUncertain — a controlled framework for evaluating whether VLMs know when not to answer spatial questions (and why).
➡️ Spatial reasoning is not just about finding the right answer—it is about knowing whether the available evidence supports an answer at all.
Visual observations can be incomplete or even misleading.
📦 Objects may be hidden by occlusion.
📐 Perspective may create misleading visual cues.
Yet today's VLMs are usually evaluated as if every question has a reliable answer. We introduce SpatialUncertain, a controlled framework for evaluating:
🔍 Can VLMs recognize when visual evidence is insufficient or unreliable?
🧭 Can they identify what additional viewpoints are needed before answering?
Thread🧵👇
In the second before a play develops, a basketball player can instantly recognize the defensive scheme (perception), anticipate how the defense will rotate (causal reasoning), simulate several possible outcomes (simulation), and choose the best move (decision).
Today's video AI is far from this. These models can describe what they see, but they cannot explain why something happened, predict what comes next, or decide how to respond. We introduce SVI-Bench to measure these capabilities, and to push toward models that can reason over real-world, multi-agent video.
I'll be at #CVPR2026, feel free to ping if you want to meet up! Will be giving 4 different keynotes at these exciting @CVPR workshops and looking forward to engaging discussions on diverse topics 🙂
(also happy to discuss hiring at all levels: PhD, postdoc, faculty)
ps. also meet several of our awesome students/postdocs who will be attending
🎉 Congratulations to Profs @gberta227 and @SenguptRoni on receiving prestigious NSF Faculty Early Career Development (CAREER) Awards to support their work in computer vision!
https://t.co/DGXtFks5JJ
🚨 Outcome rewards in LLM RL are sparse --> AVSD (Adaptive-View Self-Distillation) turns privileged info into dense token-level supervision, and instead of relying on only one privileged view, it combines multiple views and balances stable cross-view consensus vs. potentially noisy view-specific signals.
Privileged views such as full solutions, partial rationales, final answers, reference code, and feedback can all help, but none is consistently the best. AVSD uses consensus across views as the reliable update direction, then adds a view-specific residual only when it aligns with that consensus and is bounded. The result is a richer but still stable learning signal, leading to consistent gains on several math and code benchmarks across model families for each configuration we test.
🧵👇
Honored to receive an NSF CAREER Award! 🎉
Huge thanks to my students, mentors, the amazing colleagues at @unccs , and my family for making this possible. 🙏
We'll be working on Inverse Physics — teaching computers to infer shape, reflectance, lighting, material properties, and motion from images and videos, spanning both inverse rendering and simulation.
These algorithms will advance endoscopic and laparoscopic procedures with robotic guidance (supported by our NIH grants), help robots handle delicate materials in manufacturing, and various other scientific and engineering applications.
Sparse binary rewards bottleneck LLM RL, motivating the use of privileged information in self-distillation as dense teachers. How can we use and balance multiple types of privileged info: leveraging stable cross-view info, while preserving view-specific info?
Current on-policy self-distillation methods often condition the teacher on only one type of privileged view: full solution, partial rationale, answer-only, reference code, feedback, etc. This can be suboptimal:
1️⃣ No single privileged view consistently performs best when used as a teacher.
2️⃣ Views can introduce teacher-specific artifacts from information unavailable to the student.
🧠 Adaptive-View Self-Distillation (AVSD) considers multiple privileged views jointly as a teacher family, balancing cross-view consensus and view-specific signals through a token-level gate to construct better dense learning signals.
🧵👇
🚨 Check out MINTEval, a new *memory interference* benchmark to stress-test agentic memory systems on:
👉 frequent & interfering context changes (avg. 86 updates)
👉 over long horizons (avg. 138.8k-token contexts, up to 1.8M)
👉 5 challenging question types (incl. long-range recovery, multi-target reasoning)
👉 4 realistic domains (state tracking, multi-turn dialogue, wikipedia revisions, code commits)
📊 Across 7 representative systems (Full Context, RAG-based, and Memory-Augmented Agents), the best performance is only 33.4%!
Other interesting findings:
🔎 Memory construction failures are a major bottleneck
🔎 Memory agents are highly sensitive to design choices
🔎 Systems strongly favor insertion over deletion/update operations
🧵👇
LLM agents & memory systems operate in continuously updated environments (Git repos, evolving docs). They must process long contexts, recover earlier information, and reason over many updates that create interference between old and new information. How well do they handle this?
We introduce MINTEval:
✅ Frequent context changes & interference (avg. 86 updates)
✅ 5 challenging question types, including long-range lookback & reasoning over multiple targets distributed across context
✅ 4 realistic domains: state tracking, multi-turn dialogue, Wikipedia revisions, GitHub commits
✅ Avg. 138.8k tokens per instance (up to 1.8M)
✅ Human verification on generated QAs = 95.6%
📊 Across 7 representative systems, MINTEval remains difficult, showing an avg. acc of 27.9%, and the best system reaches only 33.4%.
🔎 Our analysis shows:
• Memory construction failures cause a 41.7% drop
• Memory agents are highly sensitive to design choices
• Memory systems have a strong bias toward insertion operations (76.8%) over deletion/update
🚨 Check out Agent-BRACE, our new work on belief state modeling for LLM agents in long-horizon tasks!
In long-horizon partially-observable tasks, interaction history exceeds LLM context windows, but summarizing it can discard useful uncertainty about the environment.
Agent-BRACE represents belief states as a set of natural language claims with verbalized confidence, and jointly trains a belief model to produce these states and a policy that conditions on them when taking actions.
✅ Improved task performance over strong RL baselines
✅ Compact, near-constant context
✅ Better belief calibration
🔎 We can see epidemic uncertainty reducing as the agent explores!
👇
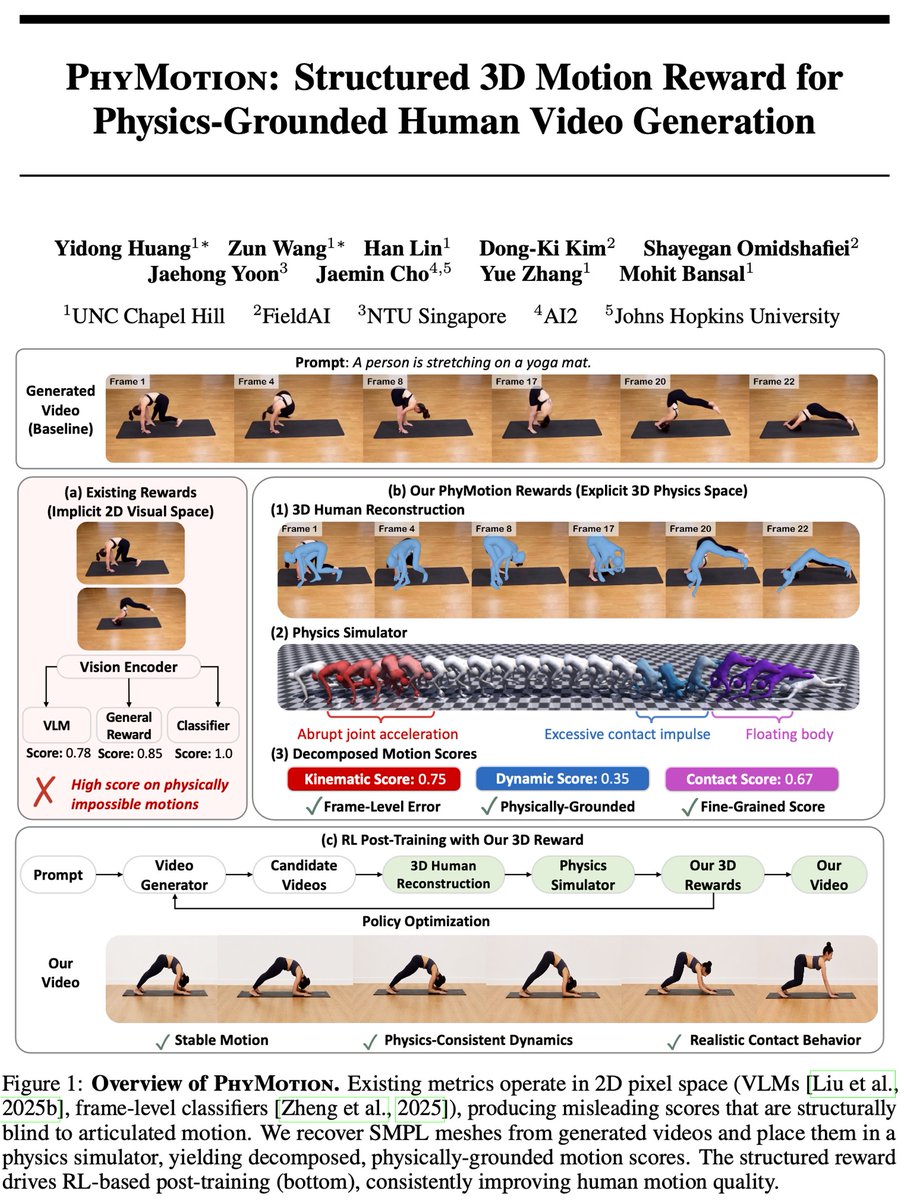
🚨 Check out PhyMotion, our new Real2Sim2Real framework for physics-grounded human motion video generation (to avoid failures e.g. floating feet, unstable balance, body self-penetration, dynamically infeasible motion, etc,) --> lifts generated videos into 3D SMPL-X human motion, grounds them in a physics simulator, and evaluates motion through structured 3D physical rewards covering:
➡️ kinematic plausibility
➡️ contact and balance consistency
➡️ dynamic feasibility
PhyMotion not only aligns better with human judgments as an evaluator, but also serves as an effective RL post-training reward!
👇👇
🚨 Excited to introduce PhyMotion🤸: Structured 3D Motion Reward for Physics-Grounded Human Video Generation!
❌ Existing 2D video rewards misleadingly assign high scores to videos with floating feet, self-penetrating limbs, and physics-violating motions.
✅ PhyMotion lifts generated videos into 3D, grounds them in a physics simulator, and scores motion along kinematic / contact / dynamic feasibility.
➡️ RL post-training with PhyMotion improves 1.3B model to match 14B models performance in human prefence.
🧵(1/n)👇
Congratulations to Dr. Anvesh Rao Vijjini for successfully defending his PhD thesis on realism and safety of personalized LLMs. Check out his work here: https://t.co/WZrfYuKOq3
PS: Anvesh is on the job market!
@nvshrao@unc_ai_group@unccs
🚨Excited to announce Agent-BRACE!
LLM agents in long-horizon POMDPs either blow up their context with raw history or summarize it, discarding uncertainty by collapsing belief into a point estimate. Agent-BRACE decouples the agent into belief state + policy models, jointly trained via RL.
Key takeaways:
1️⃣ 🎯The belief state model produces a structured approximation of the belief distribution as a set of atomic natural-language claims with ordinal verbalized certainty labels ranging from certain to unknown. The policy conditions on this compact belief rather than the full history.
2️⃣ 📈 Outperforms strong RL baselines on long-horizon partially observable embodied language environments while maintaining a near-constant context window independent of episode length.
3️⃣ 🔄 The learned belief becomes increasingly calibrated as evidence accumulates, and epistemic belief decreases over time: the proportion of claims that the agent has the strongest level of belief in grows from 21% → 52% over an episode.
👇🧵