I'm going to present Add-it at #ICLR2025 tomorrow (Thursday) @ 3pm - poster #163!
Project page: https://t.co/r6nrLJ4PJZ
If you're around this week, feel free to DM me - happy to chat!
Details below ⬇️🧵
@DanielBachmat@ShirPeled סביר להניח שבשני המקרים נוצר ��אג בפריימוורק שעוטף את המודל, והפלט שלו עבר לפלט של היוזר לפי שהוא סיים את תהליך הthinking. אחרי שזה קורה נראה שגם כשהמודל מנסה לסיים את תהליך החשיבה הוא לא מצליח, וזה הלופ שרואים לפעמים.
1/
Excited to share our paper “Safeguarding Language Models via Self-Destruct Trapdoor”, accepted as an oral at EACL 2026.
We introduce a new direction for LLM safety: a safeguard embedded directly in the model weights, with 0 inference overhead and no extra model at runtime.
Our latest research, "Rethinking Saliency Maps: A Cognitive Human Aligned Taxonomy and Evaluation Framework for Explanations" is now published in the AAAI 2026 proceedings! 🚀
📄 Paper: https://t.co/IV0c48hPzx
💻 GitHub: https://t.co/qghWuH9exB
1/
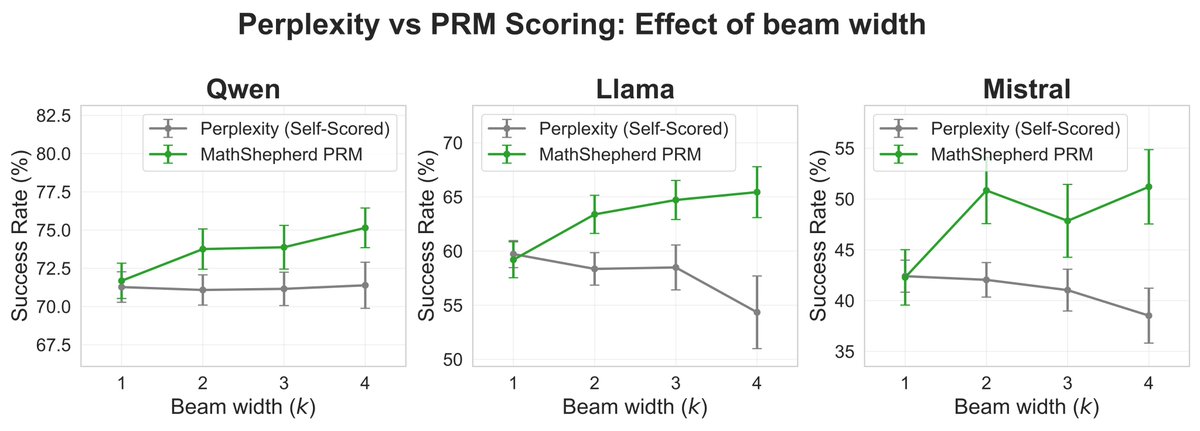
More test-time compute can actually hurt LLM reasoning. ⚠️
Beam search is often treated as a free lunch: wider beam, more candidates, better answers.
In our new paper, we show that after a certain point, the opposite can happen.
We present a research preview of Self-Flow: a scalable approach for training multi-modal generative models.
Multi-modal generation requires end-to-end learning across modalities: image, video, audio, text - without being limited by external models for representation learning. Self-Flow addresses this with self-supervised flow matching that scales efficiently across modalities.
Results:
• Up to 2.8x faster convergence across modalities.
• Improved temporal consistency in video
• Sharper text rendering and typography
This is foundational research for our path towards multimodal visual intelligence.
🚀 Excited to share our new paper: “Fast Autoregressive Video Diffusion & World Models with Temporal Cache Compression & Sparse Attention.”
We address attention bottlenecks in auto-regressive video diffusion, enabling ×5–×10 speedup and constant memory over long rollouts.
At @nvidia, we built ProtoMotions to help us, and researchers world-wide, innovate quickly without compromising on applicability.
We're proud to announce ProtoMotions3 -- our biggest release yet!
🧵👇
Image editing? Video editing? What about image collections?
Excited to share our latest work: Match-and-Fuse 🪇
https://t.co/NEMWvuPic3
Check out how we tackle the largely unexplored task of set-to-set generation in a training-free mask-free manner by leveraging the off-the-shelf 2D matches and the emergent grid prior of T2I models in a joint framework.
Work with the amazing @omri_kaduri and @talidekel
🧵 [1/3]
I am recruiting exceptional PhD students and Postdocs to join my research lab at the Technion. We study Deep Learning by pursuing creative, unconventional, elegant and mathematically rigorous ideas. 👇
OmniSVG demo & weights finally dropped on Hugging Face🔥🔥
✨ end-to-end multimodal SVG generator
✨ leverages pre-trained VLMs
✨ works all the way from simple icons to intricate anime characters
🎉 Thank you @_akhaliq for featuring our work! We’re happy to release the 💻 code & 🤗 Hugging Face demo for Add-it, our #ICLR2025 paper:
💻 Code: https://t.co/TiQYkKr2Z9
🤗 Demo: https://t.co/7vJfmIQDmM
BTW, I just tried out Anycoder by @_akhaliq and it's awesome!
I simply gave it the Add-it paper PDF and a link to our code, and it instantly generated an academic project page.
It already supports Kimi K2 and many other models!
Try it out 👉
https://t.co/vMT1W3rgs9
🎉 Thank you @_akhaliq for featuring our work! We’re happy to release the 💻 code & 🤗 Hugging Face demo for Add-it, our #ICLR2025 paper:
💻 Code: https://t.co/TiQYkKr2Z9
🤗 Demo: https://t.co/7vJfmIQDmM
Tired of manual #ComfyUI workflow design? While recent methods predict them, our new paper, FlowRL, introduces a Reinforcement Learning framework that learns to generate complex, novel workflows for you!
paper [https://t.co/Ednr7QsGFT]
1/6🚀 New #ACL2025Findings:
We show you can predict if Chain-of-Thought (CoT) reasoning will succeed — before any tokens are generated!
This works with LLMs not specifically trained for reasoning—meaning powerful signals emerge naturally in early processing.
📄🚨New!
Attribution methods that assign relevance to tokens are key to extracting explanations from Transformers and LLMs.
Yet, all existing approaches produce fragmented and unstructured heatmaps (see image)!
Why does this happen? and how can we fix this chronic issue? See🧵1/5
Are you at #NAACL?
Come to Ballroom C at 10:15 for our talk on Padding Tone 🐻
We show that text-to-image models don’t just ignore padding tokens—they actively use them during image generation, depending on the model’s architecture and training. Project page in the first comment.
I'm going to present Add-it at #ICLR2025 tomorrow (Thursday) @ 3pm - poster #163!
Project page: https://t.co/r6nrLJ4PJZ
If you're around this week, feel free to DM me - happy to chat!
Details below ⬇️🧵






















![uri_gadot's tweet photo. Tired of manual #ComfyUI workflow design? While recent methods predict them, our new paper, FlowRL, introduces a Reinforcement Learning framework that learns to generate complex, novel workflows for you!
paper [https://t.co/Ednr7QsGFT] https://t.co/UbVYDaLINe](https://pbs.twimg.com/media/GuzGuaEWcAAA4wT.jpg)
































