Hey @CloudflareDev@Cloudflare@CloudflareHelp we’re evaluating AI Gateway for LLM request caching.
Can AI Gateway cache/log storage + request processing be region-pinned (US-only)? Docs show AI Gateway isn’t compatible with Regional Services. Is there any Enterprise/private config for this?
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
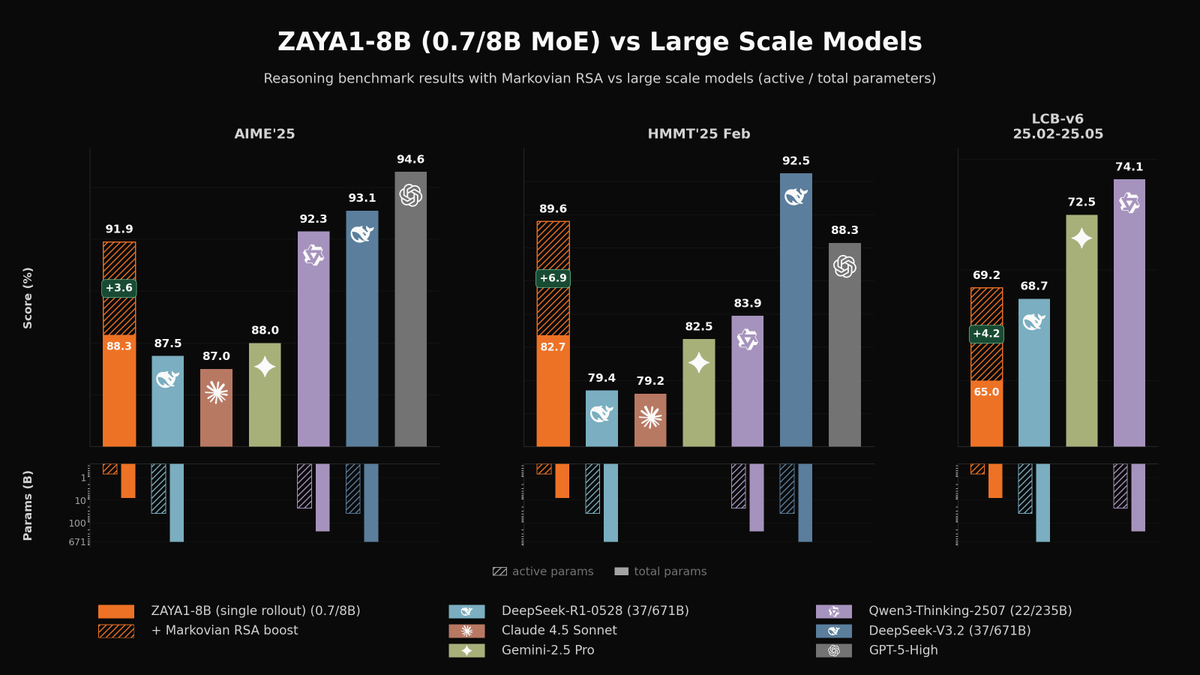
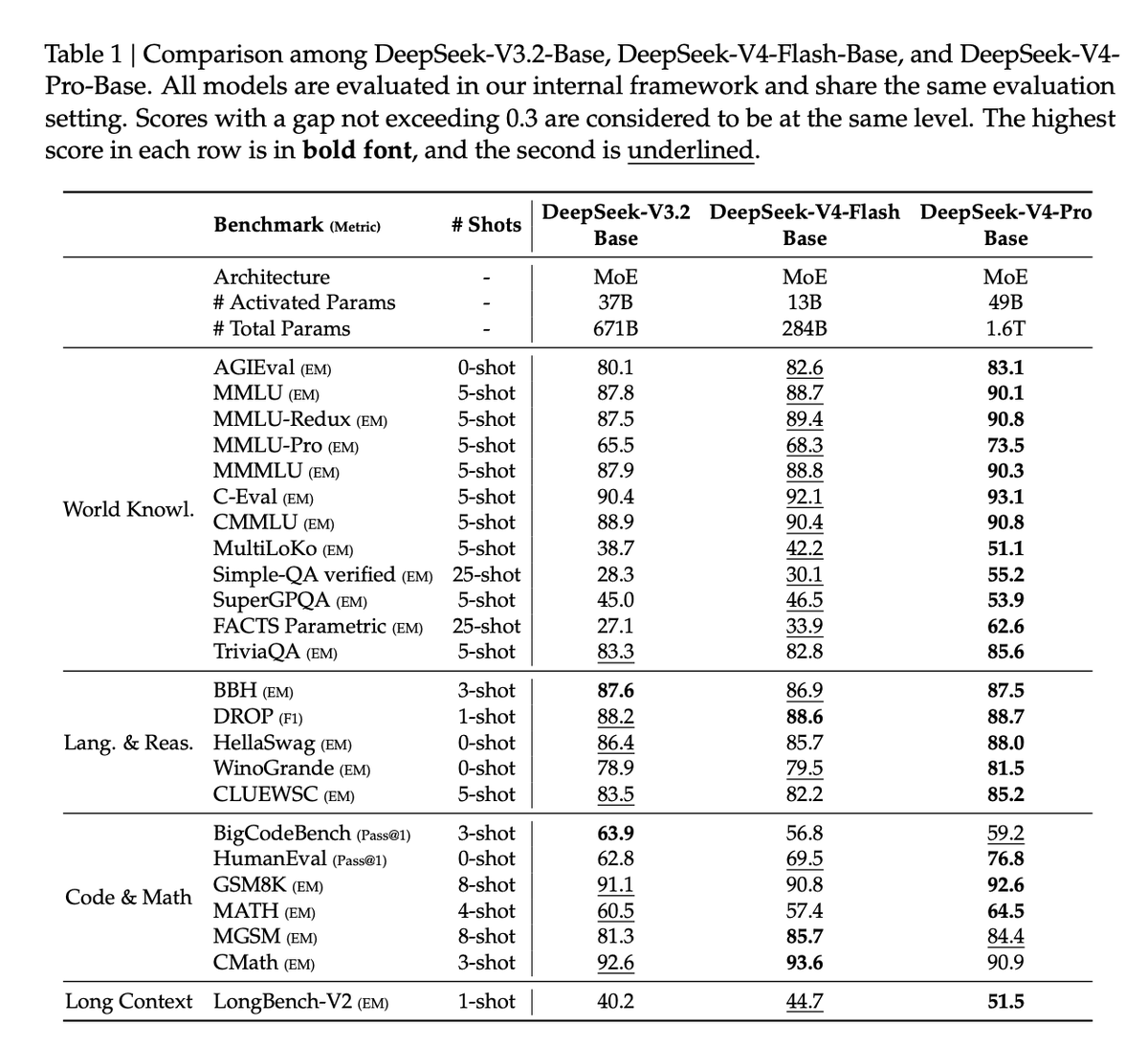
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
might just be my take… but OAI did a solid job here. the earlier ones worked fine for me, though they sometimes overexplained or got a bit defensive
this one feels more natural… no fluff, straight to the point… i like it
nice work to whoever worked on this @OpenAI 👌
After some deliberation I think GPT-5.5 is close to Mythos despite being only ~1/5 to ~1/2 the size*
VendingBench-2 results are good
ARC-AGI results are good
FrontierMath 4 results are good
CritPt results are very good
(sadly no Mythos results to compare)
CyberGym results are insane
TerminalBench 2.0 results are insane
UK AISI cyber range results are insane
(these 3 results are all on par with Claude Mythos)
but for some reason it absolutely shits the bed on SWE-Bench Pro, which threw me off but should just be discarded as noise or spiky intelligence
*I think GPT-5.4 is ~1-2T
GPT-5.5 is ~2-5T
Mythos is ~10T
Mythos pricing does look kind of ridiculous at $125
Mythos might turn out to be Anthropic's GPT-4.5 moment
GPT-5.5 on ARC-AGI (Verified)
ARC-AGI-2:
- Max: 85.0%, $1.87
- High: 83.3%, $1.45
- Med: 70.4%, $0.86
- Low: 33%, $0.35
GPT-5.5 is now state of the art on ARC-AGI-2
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
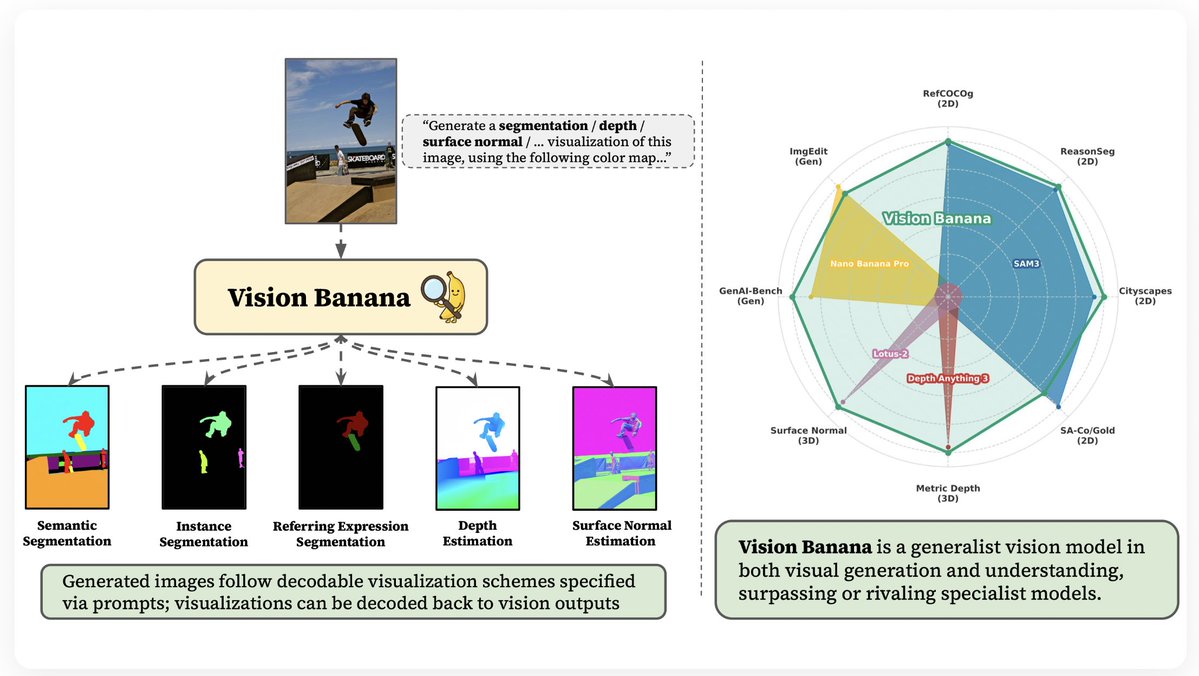
Meet Vision Banana 🍌 from @GoogleDeepMind! We provide strong evidence that image generators are generalist vision learners. Traditional computer vision tasks (segmentation, depth estimation, normal prediction) can now be performed at/near SOTA with a single generalist model derived from an image generation model.
🖼️ Explore the results: https://t.co/wgBmLooZTO
📄 See details at: https://t.co/rhkDBRmfLR