LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model + 183 dataset dependencies; Nemotron 3 → 273 + 560
We made ModSleuth to trace this. 🧵
Now available in AstaLabs in limited research preview: MyScholarQA, a personalized version of ScholarQA for scientific deep research.
ScholarQA helps synthesize evidence from 12M+ open-access papers. MyScholarQA adds user profiles to tailor that synthesis to you. 🧵
Today we’re bringing new NSF OMAI compute online with NVIDIA Blackwell Ultra-powered systems, turning a $152M national investment from @NSF & @NVIDIA into a foundation for truly open AI research. 🧵
Interim CEO Peter Clark shares his thoughts on this moment for Ai2, our commitment to open science, and where the institute is headed next. 👇
You've been part of Ai2 for many years, including as Interim CEO before. What feels different about this moment?
What feels different now is the incredible pace of progress in AI—and the risk that, in that acceleration, we lose sight of some of the longer-term work that really matters.
Ai2 was created to take that longer-horizon view. From the beginning, Paul Allen's vision was to advance AI in ways that push science forward while also delivering meaningful benefit to the world, and, critically, doing it in the open. That's a commitment that's become even more important in the current landscape.
So for me, stepping back into this role is about renewing our commitment to that mission, and maintaining a sharpened focus on long-term, high-impact research and engineering. There's a real sense of momentum here internally. Teams are coming together, new ideas are emerging, and there's a lot of energy around what comes next.
Where has that mission shown up in the projects at Ai2?
It’s always been a combination of deep research and real-world impact. Early on, we helped set the stage for the LLM revolution with our project ELMo, and more recently, that work turned into Olmo and Molmo, along with new training approaches like FlexOlmo. All these projects show that you can be open and still operate at the frontier.
At the same time, we’ve been applying AI in meaningful ways. Systems like AutoDiscovery are already changing how oncologists think about treatments for certain types of cancer, and efforts like OlmoEarth are helping us better understand complex Earth systems. That connection between advancing the science of AI and actually deploying these tools is really central to how we operate.
Where do you think Ai2 is doing something meaningfully different?
A lot of the work we focus on doesn’t fit neatly into existing incentives. Some of it is just longer-term. It’s more exploratory, where the path to impact is real but not immediate. And some of it is about openness and building in a way that others can actually understand and expand on.
As a nonprofit, we have the flexibility to do that. We can spend time on problems that need sustained attention, even if they’re not tied to short-term outcomes.
It also shapes the kind of environment we’re trying to create. People have the space to think long-term, to explore ideas that aren’t fully formed yet, and to work in the open—while still aiming toward something that has real impact.
How do you think about the role of open models in Ai2’s work?
Open models remain fundamental to what we do. They matter not just because they improve access, but because they enable a deeper scientific understanding of how these systems work. When models are open, the broader community can study them, build on them, and push the field forward more quickly.
That’s also a big part of what’s driving our NSF OMAI work. The U.S. National Science Foundation and NVIDIA invested in us to create the next generation of open model development by bringing together the compute, infrastructure, and research needed to build systems that are fully open and transparent.
We’re excited to share an update on the OMAI project very soon as our teams get to work developing the next generation of models and foundational research that will come from it.
Where is the Institute planning to focus its time and energy going forward?
There are a few areas we’re leaning into.
One is continuing to advance the science of AI systems, especially around understanding how models behave and how to make them more reliable. There’s still a lot we don’t fully understand there, and industry-wide, too much of that work is happening behind closed doors. The NSF OMAI project I mentioned earlier is a big part of this.
Another is AI for scientific research and discovery. We’re building Asta, an agentic ecosystem that can help researchers generate hypotheses, connect ideas, and move faster. Tools within Asta such as ScholarQA, AutoDiscovery, and Theorizer exemplify this direction, helping scientists by analyzing the scientific literature, discovering surprising findings in data, and positing explanatory theories.
Something we’re also really excited to keep advancing is embodied AI. There’s a lot of interesting work happening at the intersection of language models and physical systems, and some of our early efforts like MolmoAct and MolmoBot are starting to explore what it means to build more general, adaptable systems that can operate in the real world, and we have a lot more to come this year.
And then there’s our AI for the planet work—including the environment, conservation, and global systems. These are areas where our work is already having real, long-term impact, and we see huge potential for AI to help those on the ground make an even greater impact as platforms like OlmoEarth grow and expand.
How does all of this translate to real-world impact?
We’ve always tried to connect the research to something that can actually be used. In practice, that means moving across a spectrum from fundamental research to early prototypes to systems with real-world applications. And often, the interesting part is how those pieces connect.
AutoDiscovery is a good example. It began as a research system for automated, open-ended scientific discovery and is now available as a managed solution where researchers can upload structured datasets, generate and test hypotheses, and inspect the code and statistical analysis behind each result.
It’s not a linear path, but the progression from exploration to application is where a lot of the impact actually happens.
Looking ahead—what kind of future is Ai2 working to build, and how can people be part of it?
We’re working toward a future where AI is both more deeply understood and more broadly useful.
That means continuing to make systems more transparent and reliable, while also applying those advances in ways that have real impact – whether that’s accelerating scientific discovery or addressing challenges in areas like the environment and global systems.
The opportunity is to do both at once, and to do it in the open. And that really resonates with a certain kind of person: those who want to work on ambitious problems, who are motivated by impact, and who value being part of a broader scientific effort.
That’s the kind of community we’re continuing to build.
New AstaBench results show frontier models making progress on scientific research, but the benchmark remains far from solved.
Claude Opus 4.7 leads overall at 58.0%, while GPT-5.5 comes within 5.1 points at less than half the measured cost per problem. 🧵
Imagine an AI reading 10 million biology papers overnight and identifying an obscure pattern. Researchers wake up with an antibiotic candidate they can test the following day.
One of the reasons this is not happening now is that scientific knowledge is scattered across PDFs, half of them locked behind a paywall. If it was structured more like a database and actually usable by AI at scale, we could dramatically speed up new discoveries.
This is already in motion. @SemanticScholar and @orkg_org are building machine-readable representations of millions of papers, and the EU aims to provide access to machine-accessible research data by 2030.
What will we discover when AI can finally read everything?
Excited to share MyScholarQA - a personalized deep research tool that learns from your papers and lets you customize reports! 🧑🔬🖌️
Our #ACL2026 paper built and evaluated it, showing simulated users (LLMs) couldn't mimic what real users wanted 🙅
Spicy results + a live demo 👇🧵
🚨 The best AI gets built in the open. Next week, we’re bringing that message to #NVIDIAGTC — with panels, demos, and a window into what fully open models can do.
Here's where to find us 🧵👇
Are you a researcher in CS or a CS-adjacent field curious about how an AI agent can help you with your research project? Want to try a new tool for your research support in a paid user study ($100, 2 hr)? Limited spot numbers. See details and sign up here: https://t.co/lAhe3zNUK1
TL;DR: Evaluating Deep Research systems is hard. We discuss why and call out the importance of fine-grained metrics, annotator expertise, and subjectivity.
Enjoyed this collaboration led by @JenaHwang2, with mentorship from @SergeyFeldman and contributions from a great team.
🔎 Deep research agents like Asta ScholarQA and OpenAI Deep Research are transforming how we perform literature review.
But how do we know if the way we evaluate them is actually meaningful?
Announcing our new paper: “Deep Research, Shallow Evaluation: A Case Study in Meta-Evaluation for Long-Form QA Benchmarks” 🧵
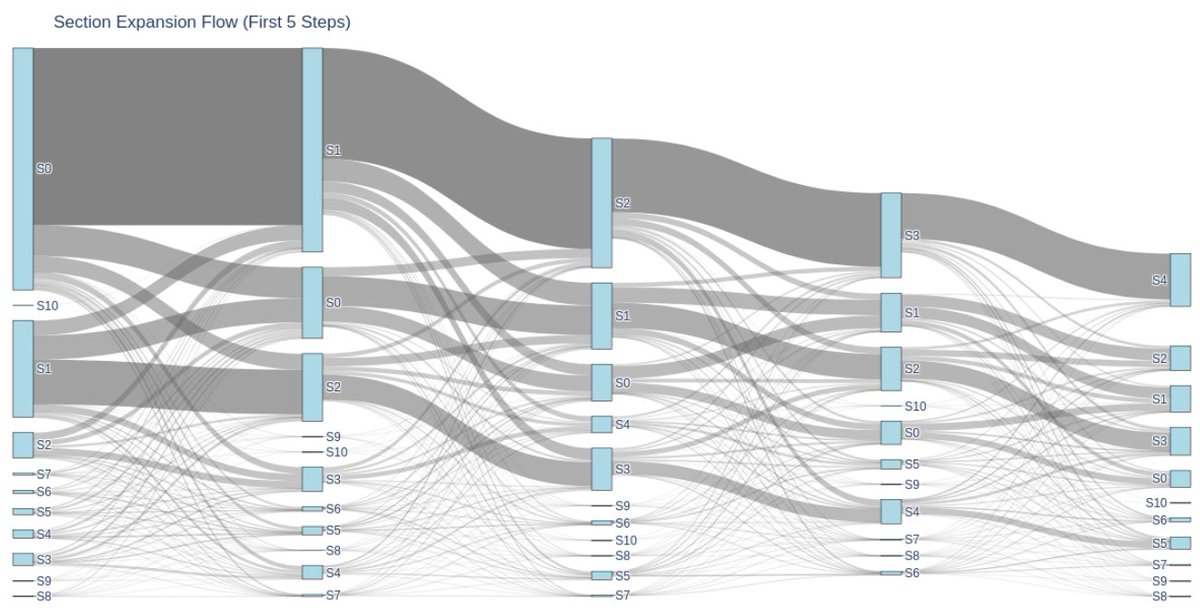
Releasing the Asta Interaction Dataset: large-scale logs of real interactions with LLM-powered scientific research tools.
Analysis led by Dany Haddad reveals how scientists use these systems in practice: longer, more complex queries and treating results as persistent artifacts.
Special shout-out to one of his favorite figures: this Sankey diagram tracing section expansion (Si = section i expanded).
We analyzed 250K+ queries & 430K+ clickstream interactions from Asta, our AI-powered research assistant—and today we're releasing the full dataset. How do researchers actually use AI science tools? Here's what we found. 🧵
Can today’s agents anticipate future scientific collaborations, ideas, and impact?
Introducing PreScience, a large-scale AI benchmark for scientific forecasting.
Careful dataset construction led by @anirudhajith42, with @aps6992, @jaydepun, @Hoper_Tom and collaborators.
Can AI predict what scientists will do next—not just one piece, but the whole research process? PreScience is our new model eval for forecasting how science unfolds end-to-end, from how research teams form to a paper's eventual impact. Built with @UChicago, supported by @NSF.
Knowing which questions to ask is often the hardest part of science. Today we're releasing AutoDiscovery in AstaLabs, an AI system that starts with your data and generates its own hypotheses. 🧪
Introducing Theorizer: Turning thousands of papers into scientific laws 📚➡️📜
Most automated discovery systems focus on experimentation. Theorizer tackles the other half of science: theory building—compressing scattered findings into structured, testable claims. 🧵
Introducing Ai2 Open Coding Agents—starting with SERA, our first-ever coding models. Fast, accessible agents (8B–32B) that adapt to any repo, including private codebases. Train a powerful specialized agent for as little as ~$400, & it works with Claude Code out of the box. 🧵
🆕 New in Asta: multi-turn report generation.
You can now have back-and-forth conversations with Asta, our agentic platform for scientific research, to refine long-form, fully cited reports instead of relying on single-shot prompts.
olmo 3 paper finally on arxiv 🫡
thx to our teammates esp folks who chased additional baselines
thx to arxiv-latex-cleaner and overleaf feature for chasing latex bugs
thx for all the helpful discussions after our Nov release, best part of open science is progressing together!
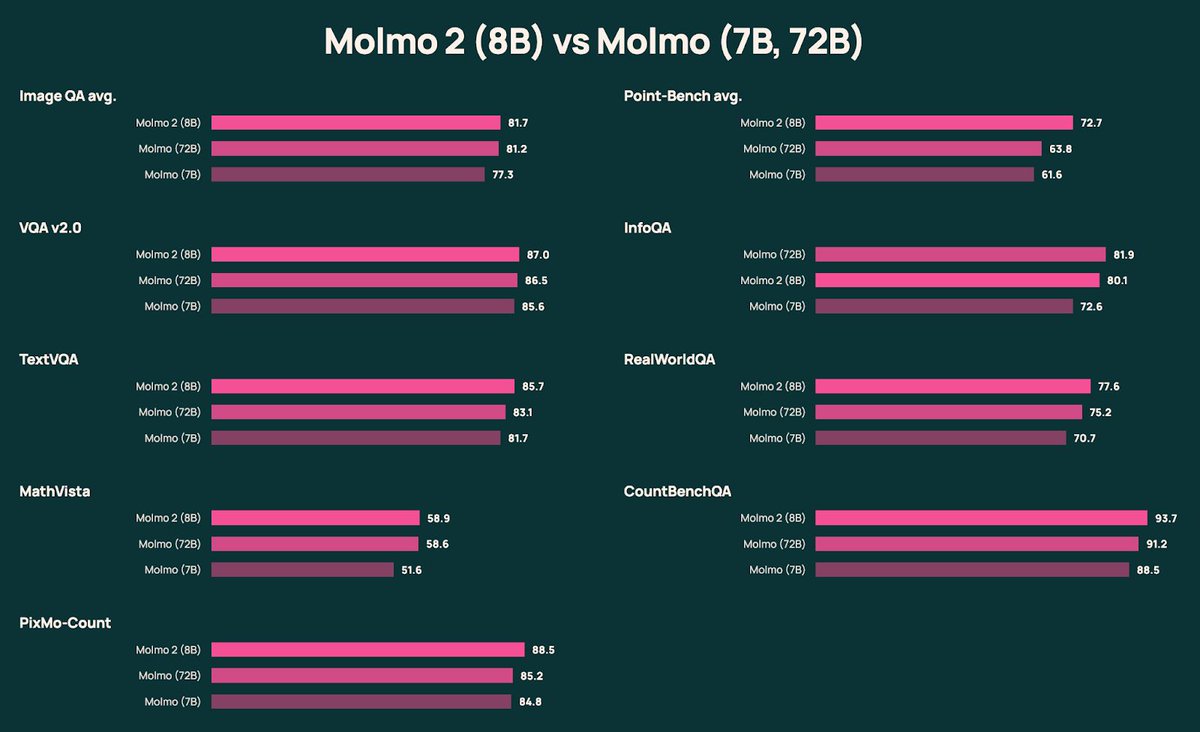
Last year Molmo set SOTA on image benchmarks + pioneered image pointing. Millions of downloads later, Molmo 2 brings Molmo’s grounded multimodal capabilities to video 🎥—and leads many open models on challenging industry video benchmarks. 🧵
Update: DataVoyager, which we launched in Preview early this fall, is now available in Asta. 🎉
You can upload real datasets, ask complex research questions in natural language, & get back reproducible answers + visualizations. 🔍📊
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵