I have an open Postdoc position in Molecular Systems Biology at ETH Zürich!
The project is about the conservation of transcription factors functions between strains of Pseudomonas aeruginosa 🧬🦠
More details and application at:
https://t.co/FJVQ4VdnxU
Please share!
Wikidata is a free and open knowledge base that can be read and edited by humans and machines. It acts as central storage for the structured data of Wikimedia projects like @Wikipedia.
Keep learning about this powerhouses behind Wikimedia projects ➡️ https://t.co/vGOHylrbp5
This could be a good time to remind those that may have not seen it before, that the @reactome database at @emblebi also has a library of open access icons https://t.co/4imnl9zy5V
I'm hiring another postdoc for my starting lab at @VIB_microbes to study microbial carbon fixation! We'll be deriving how enzymes in marine microbes inadvertently form stable molecules that are sequestered long term in the ocean.
https://t.co/f4KNfleeEI
I have an open position for a PhD student in molecular microbiology!
The project is about the role of transcription factors during P. aeruginosa infections 🦠🧬.
More details:
https://t.co/GU4GGWuQfA
Please share!
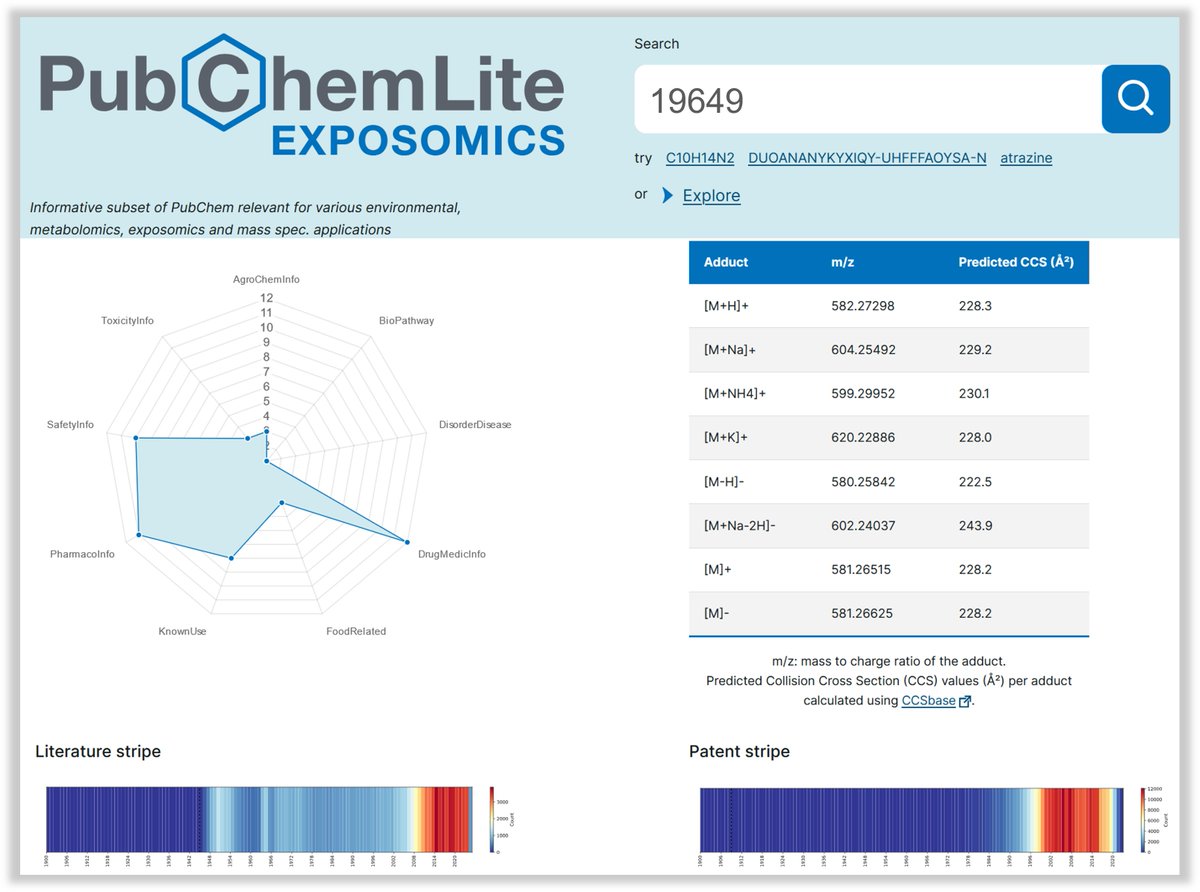
Delighted to present our web interface for PubChemLite:
https://t.co/A0pIhoJyjv
Beautifully designed by Valentin Groues from our BioCore @lcsb_uni_lu & featuring the #chemicalstripes of @DagnyAurich and predicted CCS from CCSbase @UwXulab + #PubChem we hope you will all enjoy!
Untargeted metabolomics analyses to identify a new sweet compound released during post-fermentation maceration of wine. #FoodChem#MassSpec https://t.co/AVvYe9VaWV
Our article where we enhanced boilerplate GNNs with a set representation layer to
push the SOTA (incl. large language models and specialised GNNs) has been released in @NatMachIntell.
Huge thanks to @marita_b1 and @trekkinglemon
https://t.co/kJuPgeb4gz
Excited to announce that our new paper on using sets of atomic invariants to enhance ML models for molecular property, binding affinity and reaction yield prediction is out now! Many thanks to @skepteis and @trekkinglemon for the supervision and support!
https://t.co/lJvogEPBDf
Sebastian Böcker and Kai Dührkop travelled to Japan to present SIRIUS 6 in a workshop and a keynote talk at #Metabolomics2024.
Make sure to get in touch with them to learn more about #SIRIUS6.
⬇ Download SIRIUS 6: https://t.co/kC59MZ7ryw
#SIRIUS_MS#MetSoc2024#SIRIUSEvents
Happy to see plantMASST out (https://t.co/t199ireqQH). It is a community-curated database of nearly 20,000 LC-MS/MS data files from ~2,800 plant species, making them searchable. This allows one to directly connect plant's metabolites to their taxonomic distribution [1/4]
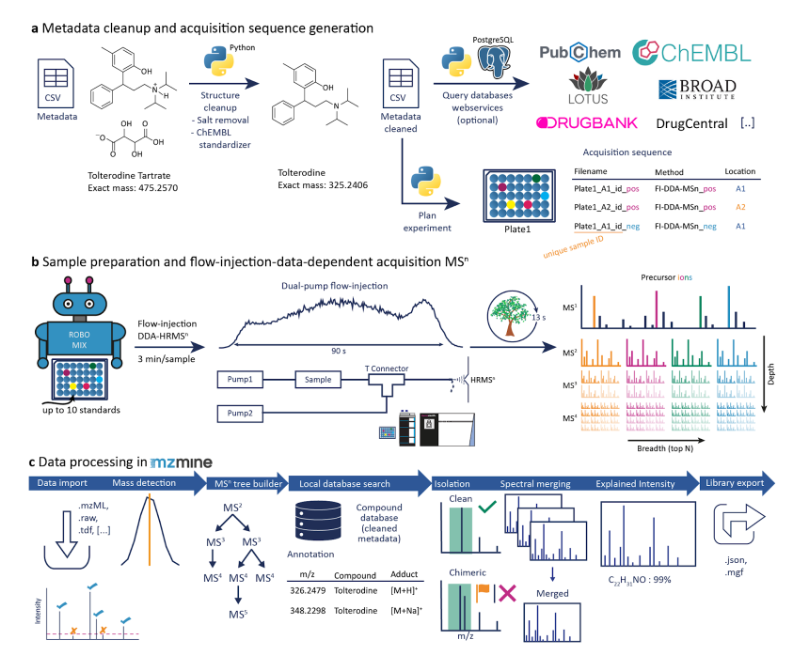
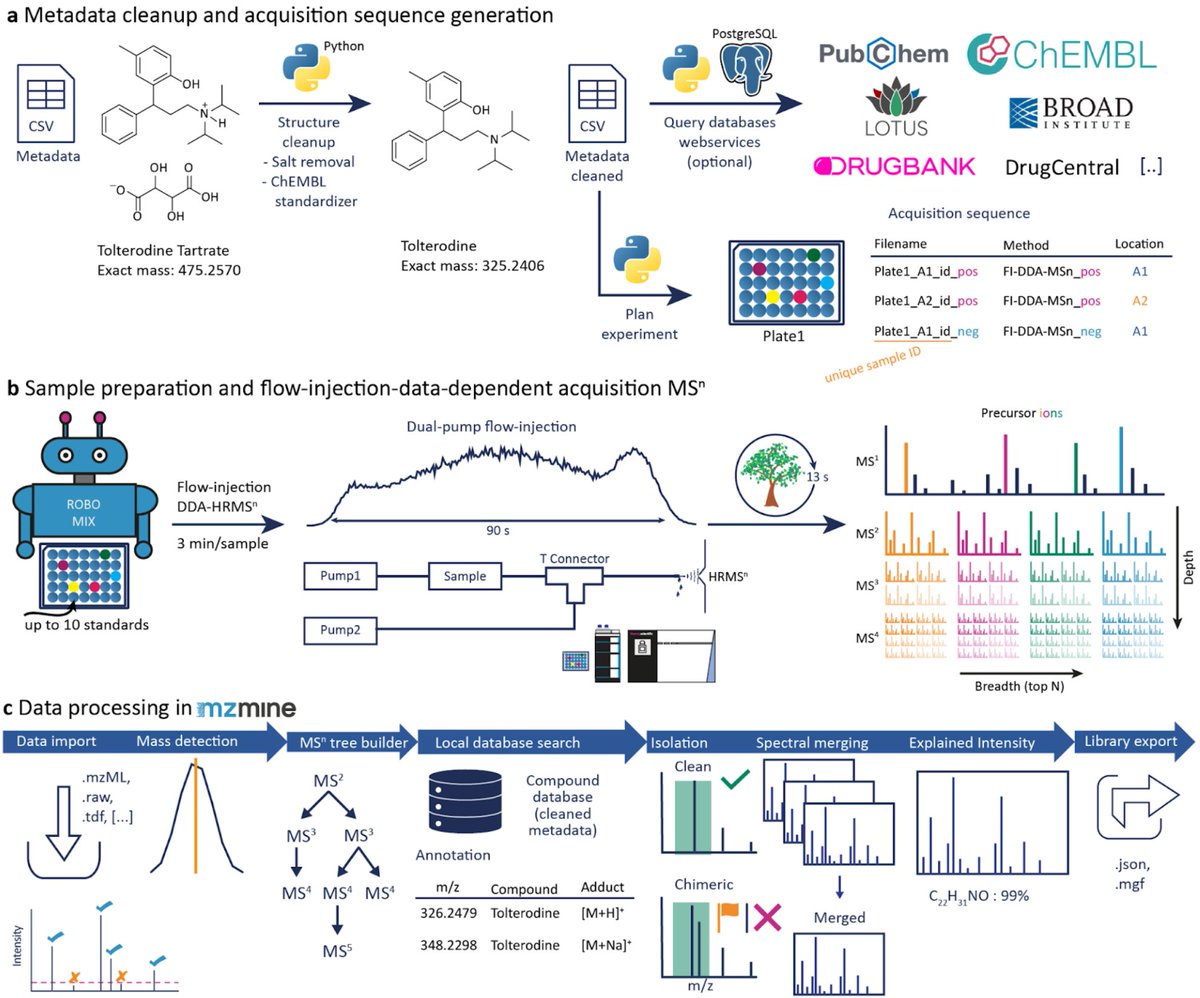
I’m happy to share a preprint about our efficient MSn library building workflow. We developed a high-throughput method and @mzmine_project pipeline to extract 1M spectra of >16,000 compounds; all accomplished in 12 days. Contact us to customize the MSnLib.
https://t.co/gy4rx3snfI
Our preprint describes an MSn library, a high-throughput acquisition method, and a #CompMS pipeline powered by @mzmine_project. Led by @corinnabrungs et al. we built the first #FAIR multi-stage fragmentation spectral tree library for >16,000 compounds. 1/n
https://t.co/vf7WOAKjIa