World models are moving beyond offline generation towards interactive, real-time experiences.
Introducing ⚡FlashDreams⚡: an open-source high-performance inference and serving library built for autoregressive world models:
🔥 Up to 3.10× faster LingBot-World inference
🔥 Up to 2.12× faster Self-Forcing inference
🔥 Up to 1.40× faster Wan2.1 inference
🔥 8 integrated models
🔥 Multi-GPU, streaming, low-latency serving
🔥 Agentic skills that teach you how to use it
FlashDreams is designed for a new generation of AI systems that continuously evolve over time while responding to user interactions. It powers applications across robotics, autonomous vehicle simulation, gaming, and virtual worlds.
Github: https://t.co/xM8LuPaRTS
Docs: https://t.co/IInORNIzy3
Research page: https://t.co/mZ6TLQSpIO
Join the #flashdreams Discord channel at https://t.co/GGOQ0k7liY
FlashDreams is also the runtime backbone behind NVIDIA OmniDreams (https://t.co/PLUt55gxxh)
1/n
#AI #WorldModels #FastInference #PhysicalAI #OpenSource #NVIDIA
Following recent World-Action Model results in robotics, the same ~2B OmniDreams single-view backbone can be fine-tuned into a driving policy.
In preliminary closed-loop results, it reduces collision from 6.9% to 4.2% when compared with Alpamayo 1.5, while having roughly 5x fewer parameters.
Real time world model NVIDIA OmniDreams now open sourced!
If you are at CVPR, we invite you to also check out a live demo you can try out at the NVIDIA booth.
🚀 What if physical AI policies could interact with generated worlds in real time?
Introducing OmniDreams, a generative world model for closed-loop autonomous vehicle simulation.
Tech report, code, models, and data samples are available now.
Project: https://t.co/BOTWdSJKMx
Code: https://t.co/hPH3KbE6Uy
Model: https://t.co/G4g9TWFD2W
Join the #omnidreams discord channel: https://t.co/AIwYQvc0bv
It’s been a while since I posted here, but I’m very excited to share what our team at @nvidia has been building over the past year!
After a year of active development, we’re getting ready to release SIL-Wheel to the world: a one-stop shop platform for data-centric workflows in large-scale video model training.
Built by researchers, for researchers, SIL-Wheel brings together search, curation, annotation, evaluation, and analysis for large video datasets in one centralized framework.
Want a sneak peek before the official release? Come by the NeXD26 Workshop @CVPR tomorrow at 10:30!🚀
The latent-vs-pixel debate misses the point.
GPT Image 2 shows what users notice: pixel-level fidelity.
Latent models show what scales: compact semantic structure.
We connect them by replacing VAE/RAE decoders with a Pixel Diffusion Decoder.
Code and Model available: https://t.co/JjtecJzF0W
🧵(1/N)
A hill that I will die on: with today's AI models, intelligence is a function of inference compute. Comparing models by a single number hasn't made sense since 2024. What matters is intelligence per token or per $.
This is especially true when using it in a product like Codex.
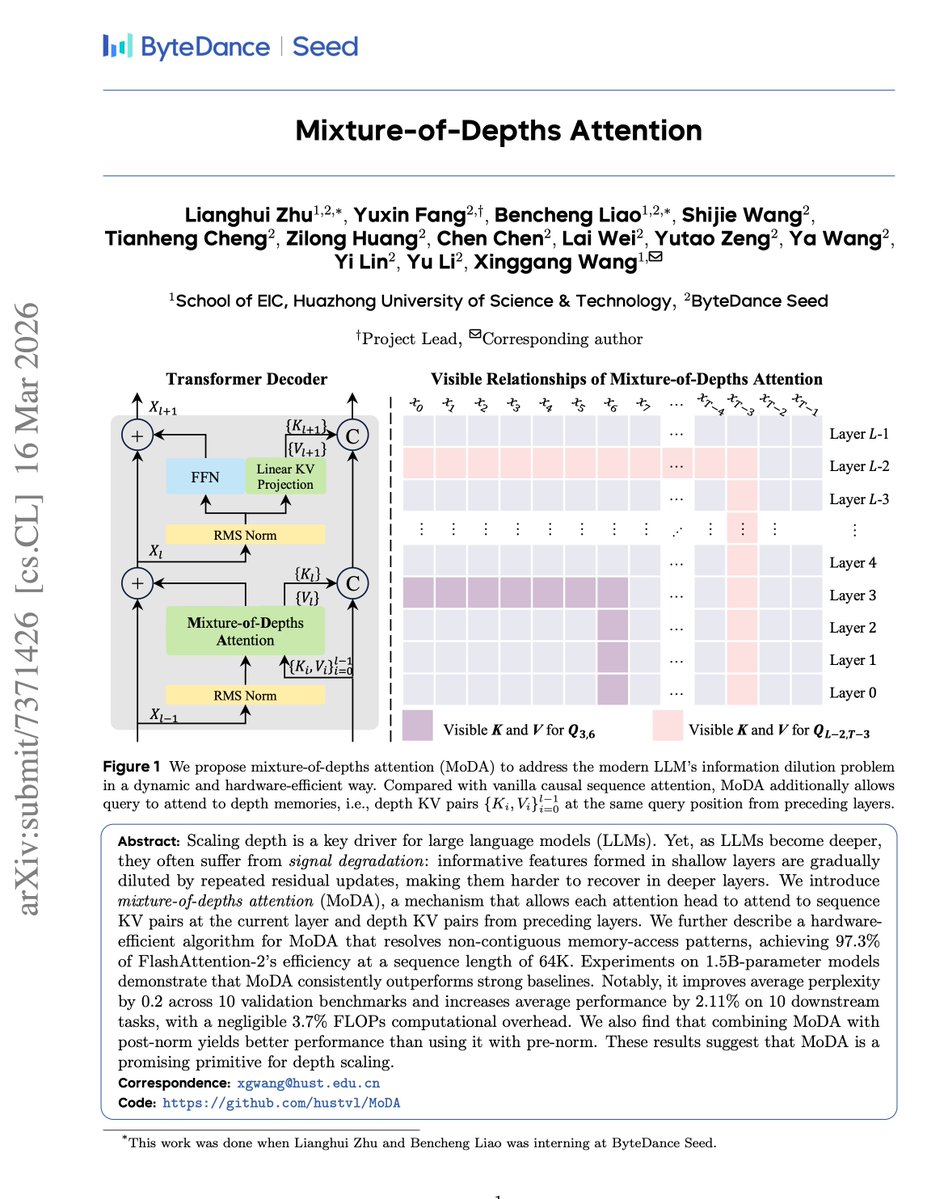
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other.
Since ResNet's `x + F(x)` in 2015, the depth residual has been the only highway for inter-layer communication.
It's time to upgrade the staircase. 🧵
Feed-forward 3D reconstruction should not be limited to predicting one Gaussian per pixel.
We introduce TokenGS, which uses learnable tokens to decouple the 3D Gaussian prediction from the image resolution and the number of input views.
#CVPR2026Highlight
[1/6]
🚀 Excited to share ViPRA: Video Prediction for Robot Actions
📍 Accepted to #ICLR2026@iclr_conf
🏆 Best Paper — #NeurIPS2025 Embodied World Models Workshop
Robot learning today still needs millions of action labeled videos.
Yet videos are abundant — from humans and the web — but lack action labels. Meanwhile, pretrained video models already learn rich dynamics.
ViPRA is a recipe for turning pretrained video models into robot policies while enabling robot learning to scale with actionless videos.
🧵 Thread ↓
Special moment to see something I’ve worked on so closely come to life!
Today we announce Alpadreams — a world model that lets you explore ♾endlessly♾️in ⚡real time⚡.
Video: me (left) and Alpamayo policy (right) driving in Alpadreams at #GTC26.
https://t.co/pwJtEjKbcb
A new generation in AV simulation is here!
We are announcing AlpaDreams, a real time interactive generative world model for AV simualtion! Just a year ago it took minutes to generate a few seconds of video, today it is real time and interactive!
https://t.co/FbhKu3PMqe
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
@gkopanas I love that review. I do genuinely think a great way to evaluate research contributions would be to add the new paper to an agent's context window and see what delta the agent can get on some OSS codebase's performance.
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 https://t.co/TbKXjQMN3H
1/10
🚗📡Radar is the unsung hero of AV perception: widespread in cars, yet overlooked in simulation.
Introducing RadarGen: Realistic radar synthesis from cameras using diffusion.
Massive kudos to my fantastic team at @TechnionLive and @NVIDIAAI
https://t.co/YVBoVi9atT
Can we apply gradient descent to discrete changes? In our new #SIGGRAPHAsia paper, we show that gradient descent can work on shape grammars, as in CAD and procedural modeling, but only if the grammars are designed correctly!
Video motion and view control just became easy! Check out our new plug-and-play approach led by my brilliant students and collaborators @assaf_singer@NoamRot@mann_amir_@RonnyKimmel@TechnionLive
🌐project page: https://t.co/ncctQx4p8f
How is memorized data stored in a model? We disentangle MLP weights in LMs and ViTs into rank-1 components based on their curvature in the loss, and find representational signatures of both generalizing structure and memorized training data