Want 4x faster local inference on dedicated GPUs for your interactive apps? DiffusionGemma is an experimental, open 26B MoE model that generates entire blocks of text simultaneously instead of token-by-token.
By shifting the local decoding bottleneck from memory-bandwidth to compute, it hits speeds over 700 tokens/sec on a single NVIDIA RTX 5090 GPU. This diffusion unlocks unique local workflows like real-time inline editing, code infilling, and instant self-correction.
📥 Download the Apache 2.0 weights on @HuggingFace: https://t.co/L5eqih19T5
📖 Read the full technical announcement on the blog: https://t.co/mESsFJNEDc
Gemini 3.5 Flash is built to help you execute complex, agentic workflows.
3.5 Flash rivals flagship models to deliver frontier performance for agents and coding, at the lightning speeds you expect from the Flash series.
Gemini 3.5 Flash is built to help you execute complex, agentic workflows.
3.5 Flash rivals flagship models to deliver frontier performance for agents and coding, at the lightning speeds you expect from the Flash series.
Just reserved my @opengotchi — a pocket-sized AI pet that builds apps from a single prompt.
The AI-native gadget era is here.
Reserve your spot at https://t.co/p9p9Y5M7Bg
https://t.co/IOpQ0x7z4r
something cute with milady eyes is about to live on your desk
it has a screen. it runs gotchiOS. it builds apps from single prompts
v1 reservations are open
$6.9
https://t.co/6E7T0gYWId
@iamsupersocks@0xSero Je suis totalement aligné avec ce qu'il dit et je le suis avec attention depuis un petit moment. Vous avez eu l'occasion de jeter un œil à bittensor ? Ça me paraît être une solution sinon veut rester libre.
L’économie des agents est inévitable.
Sans commerce trustless, la “decentralized AI” redevient juste une plateforme: escrow privé, verdict privé, settlement contrôlé.
ERC‑8183 met l’essentiel au niveau protocole: escrow + attestation + settlement on-chain.
Les données disponibles sur https://t.co/Yz6AmwMTfb sont désormais interrogeables via un serveur MCP dédié en experimentation, vos retours sont bienvenus !
💻 Le code est ouvert et accessible sur GitHub :
https://t.co/AmY04V22TH
Pour en savoir plus : https://t.co/V7UJrc6uUq
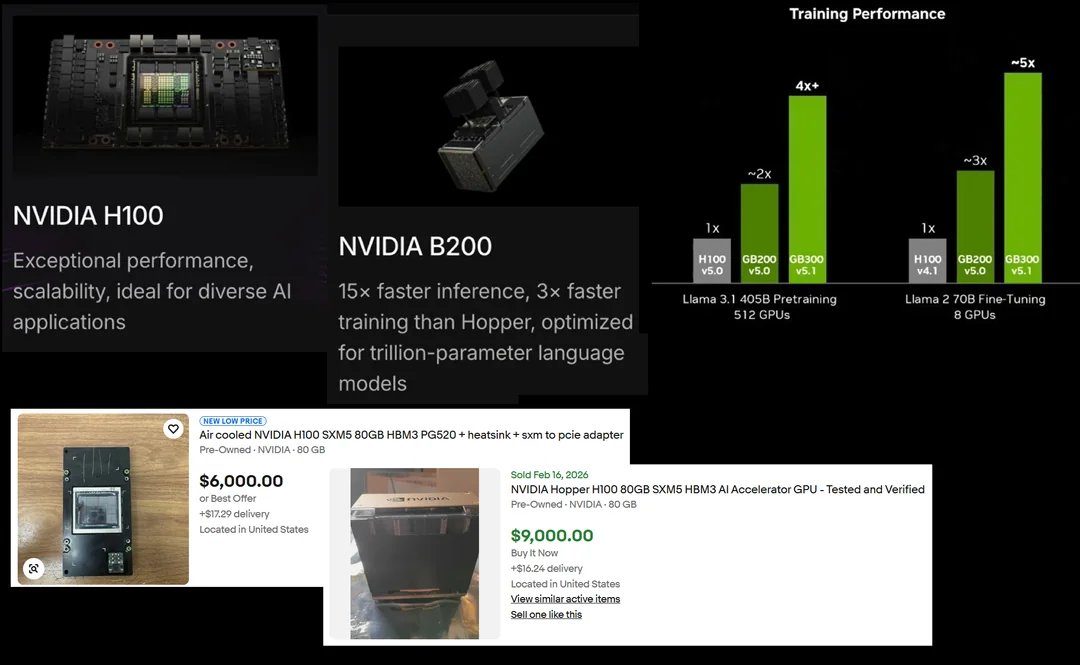
🦔 H100 GPUs that cost $40,000 new are now selling for around $6,000 on eBay, an 85% drop. The math on why is straightforward: it costs about 11x as much to run an H100 for inference as a B300. Anyone running H100s needs to charge dramatically more than competitors on newer hardware.
Upgrading isn't simple either. At a $50,000 price tag for a B200, it takes about 33 months to break even on the upgrade from an H100. And the B300s are already making B200s less attractive.
My Take
I've been covering the depreciation problem in AI infrastructure for a while now. Companies are booking these GPUs on five to six year depreciation schedules when Nvidia releases new generations every two years. Michael Burry flagged Big Tech lengthening depreciation timelines as suspicious because it hides the real losses. A hedge fund manager I wrote about found that industry insiders estimate actual component lifespans at 3-10 years, but the economics don't work at any of those numbers.
The hyperscalers are sitting on hundreds of thousands of GPUs that lose value every time Nvidia announces something new. David McWilliams called them "digital lettuce" because they go stale while you're still installing them. The difference between what the books say these assets are worth and what you could actually sell them for is enormous. At some point that gap has to be reconciled. H100s selling for 85% off on eBay is a preview of the writedowns coming to earnings reports.
Hedgie🤗