Excited to share our work to appear at #CVPR2025! This work in collaboration with @jacob__krantz and @stefmlee investigates if visual representations (imaginations) of natural language instructions can improve performance of vision-and-language navigation (VLN) agents.
TL;DR-yes
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
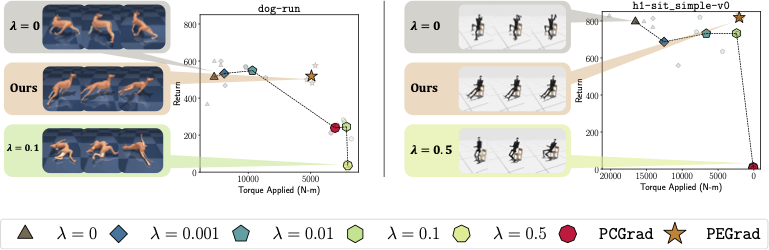
Introducing PEGrad, a hyperparameter-free method for energy-efficient robot control. By projecting energy gradients orthogonal to task rewards, it cuts energy use by up to 64% without hurting performance. Demonstrated on DM-Control, HumanoidBench, and real Unitree GO2 robots,
Energy usage in robots is a double-edged sword: spend too much and you drain batteries (or risk damage), spend too little and the robot fails.
Excited to share our work PEGrad, co-authored with Skand, @bikcrum and @stefmlee, accepted for an oral presentation at #CoRL2025
🧵👇
Key takeaways:
- Extends robot battery life and safety.
- Removes the need for tedious hyperparameter tuning between energy and task rewards.
- Brings us closer to sustainable, deployable energy-efficient RL robots.
@stefmlee@sanghyun_hong We also evaluated robustness under visual corruptions like motion blur and speckle noise, finding that while both baseline and our method degrade, the efficiency gains are preserved and de-noising helps recover performance.
Happy to share that our collaborative work, “Harnessing Input-Adaptive Inference for Efficient VLN” has been accepted to #ICCV2025 ! 🤖
Paper: https://t.co/pRWVicWAxs
(contd.)
@stefmlee@sanghyun_hong Combined, these methods achieve about 56% average reduction in computation, with only about 12% average drop in success rate (SR) across standard VLN benchmarks—and even higher savings (~87–90%) in continuous VLN environments with modest performance trade-offs.
Behind every great conference is a team of dedicated reviewers. Congratulations to this year’s #CVPR2025 Outstanding Reviewers!
https://t.co/z8w4YJKTep
Finally, they are encoded along with other modalities in a cross-modal encoder to sample agent actions. We observe performance improvements across agents and natural language instruction granularities. For more details, our work is available at https://t.co/uSe9ldQ5Xb.
Excited to share our work to appear at #CVPR2025! This work in collaboration with @jacob__krantz and @stefmlee investigates if visual representations (imaginations) of natural language instructions can improve performance of vision-and-language navigation (VLN) agents.
TL;DR-yes
We use a language-conditioned pre-trained diffusion model to generate imaginations by leveraging its strong priors. The imagination representations are aligned to corresponding noun-phrases from instructions using an auxiliary alignment loss.