This 2 hour Stanford lecture on AI careers will teach you more about winning in the AI race than every piece of AI content you have scrolled past this year.
Bookmark this & give it 2 hours, no matter what. It'll be the most productive thing you could do this weekend.
I gave a lecture at @Stanford CS 25.
Lecture video: https://t.co/Js7SThVO6S
AI is moving so fast that it's hard to keep up. Instead of spending all our energy catching up with the latest development, we should study the change itself.
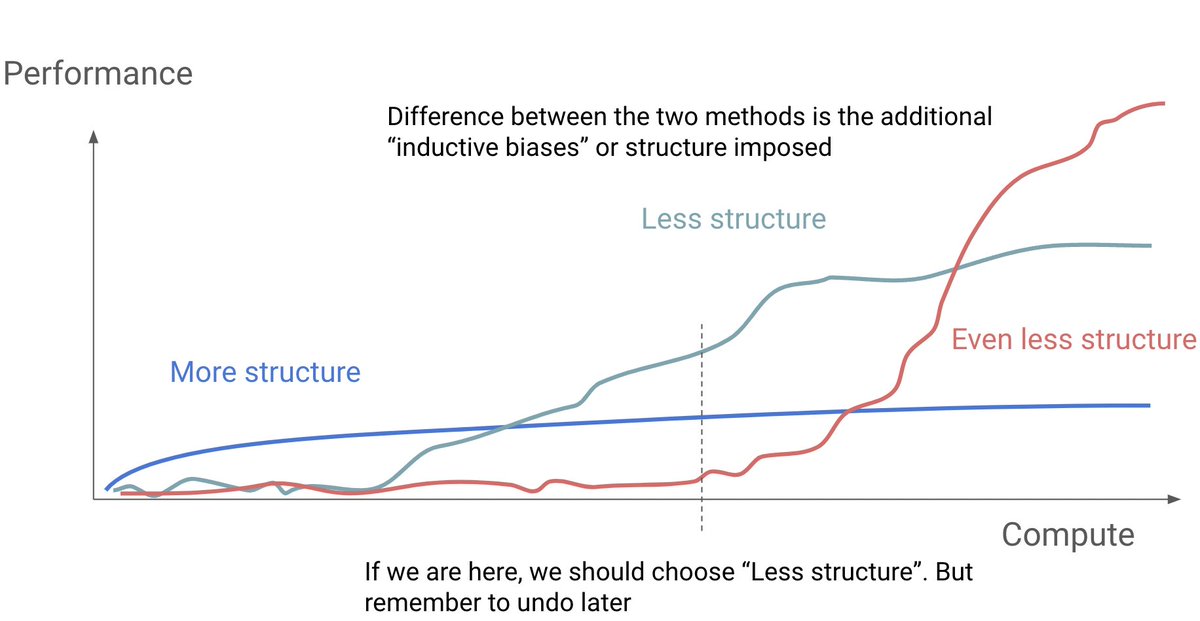
First step is to identify and understand the dominant driving force behind the change. For AI, a single driving force stands out; exponentially cheaper compute and scaling of progressively more end-to-end models to leverage that compute.
However this doesn’t mean we should blindly adopt the most end-to-end approach because such an approach is simply infeasible. Instead we should find an “optimal” structure to add given the current level of 1) compute, 2) data, 3) learning objectives, 4) architectures. In other words, what is the most end-to-end structure that just started to show signs of life? These are more scalable and eventually outperform those with more structures when scaled up.
Later on, when one or more of those 4 factors improve (e.g. we got more compute or found a more scalable architecture), then we should revisit the structures we added and remove those that hinder further scaling. Repeat this over and over.
As a community we love adding structures but a lot less for removing them. We need to do more cleanup.
In this lecture, I use the early history of Transformer architecture as a running example of what structures made sense to be added in the past, and why they are less relevant now.
I find comparing encoder-decoder and decoder-only architectures highly informative. For example, encoder-decoder has a structure where input and output are handled by separate parameters whereas decoder-only uses the shared parameters for both. Having separate parameters was natural when Transformer was first introduced with translation as the main evaluation task; input is in one language and output is in another.
Modern language models used in multiturn chat interfaces make this assumption awkward. Output in the current turn becomes the input of the next turn. Why treat them separately?
Going through examples like this, my hope is that you will be able to view seemingly overwhelming AI advances in a unified perspective, and from that be able to see where the field is heading. If more of us develop such a unified perspective, we can better leverage the incredible exponential driving force!
Slides: https://t.co/RccKFOqK7e
That’s actually a real person doing that.
Ray Castoldi has been the stadium organist at Madison Square Garden since 1989, best known for playing during all the Knicks and Rangers games. He has played more shows at MSG than Billy Joel.
[📹 newyorknico]
https://t.co/JZxire88me
My team at Google is looking to hire a PhD student intern for research on AI-based coupled Earth system modeling. This would be a full-time ~3 month position in summer or fall 2024 working in-person in Cambridge, MA with @dkochkov1 and @janniyuval.
A 2023 update of the CS224N Natural Language Processing with Deep Learning YouTube playlist is now available with new lectures on pretrained models, prompting, RLHF, natural language and code generation, linguistics, interpretability and more. #NLProc
https://t.co/6hb0EIaR5Z
NEW §
In her 5th memo about exploring GenAI for software development, Birgitta Böckeler answers the frequently asked question if coding assistants are making the practice of Pair Programming obsolete. Spoiler alert: They don't.
https://t.co/NJZPrLebEb
The European Union has just agreed on a Compromise Text for its EU AI Act.
The EU AI Act will set the global standard for how AI systems must be built. Think of it as the GDPR for AI.
I'm going through the text to highlight important changes... 🧵 1/n