So many exciting releases from FAIR @AIatMeta
Super happy to see Spirit LM now open-sourced.
Spirit LM unlocks expressive speech generation through interleaving speech-text training and phonetic(hubert)+pitch+style-specific tokenization.
Available here:
Weights: https://t.co/FI5pPznwaE
Code: https://t.co/GNgt3ATfUk
Paper: https://t.co/CwmzjWz17Z (soon to be presented at #EMNLP2024 )
Open science is how we continue to push technology forward and today at Meta FAIR we’re sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1.
This work is another important step towards our goal of achieving Advanced Machine Intelligence (AMI).
What we’re releasing:
• Meta Spirit LM: An open source language model for seamless speech and text integration.
• Meta Segment Anything Model 2.1: An updated checkpoint with improved results on visually similar objects, small objects and occlusion handling. Plus a new developer suite to make it easier for developers to build with SAM 2.
• Layer Skip: Inference code and fine-tuned checkpoints demonstrating a new method for enhancing LLM performance.
• SALSA: New code to enable researchers to benchmark AI-based attacks in support of validating security for post-quantum cryptography.
• Meta Lingua: A lightweight and self-contained codebase designed to train language models at scale.
• Meta Open Materials: New open source models and the largest dataset of its kind to accelerate AI-driven discovery of new inorganic materials.
• MEXMA: A new research paper and code for our novel pre-trained cross-lingual sentence encoder with coverage across 80 languages.
• Self-Taught Evaluator: a new method for generating synthetic preference data to train reward models without relying on human annotations.
Access to state-of-the-art AI creates opportunities for everyone. We’re excited to share this work and look forward to seeing the community innovation that results from it.
Details and access to everything released by FAIR today ➡️ https://t.co/P3XkdN2WQN
If Gemini-3 proved continual scaling pretraining, DeepSeek-V3.2-Speciale proves scaling RL with large context.
We spent a year pushing DeepSeek-V3 to its limits. The lesson is post-training bottlenecks are solved by refining methods and data, not just waiting for a better base.
🚀 Introducing the Latent Speech-Text Transformer (LST) — a speech-text model that organizes speech tokens into latent patches for better text→speech transfer, enabling steeper scaling laws and more efficient multimodal training ⚡️
Paper 📄 https://t.co/4nUsbC1YKF
Introducing @CodeWordsAI , the fastest way to go from idea to automation, simply by chatting with AI.
No more drag-and-drop and configuration. Save time by doing less.
Available today for free, for everyone. The Cursor moment for automation is here.
We ran Llama 4 Maverick through some HELM benchmarks. It is 1st on HELM capabilities (MMLU-Pro, GPQA, IFEval, WildBench, Omni-MATH), but…
https://t.co/uKMHRe7xKF
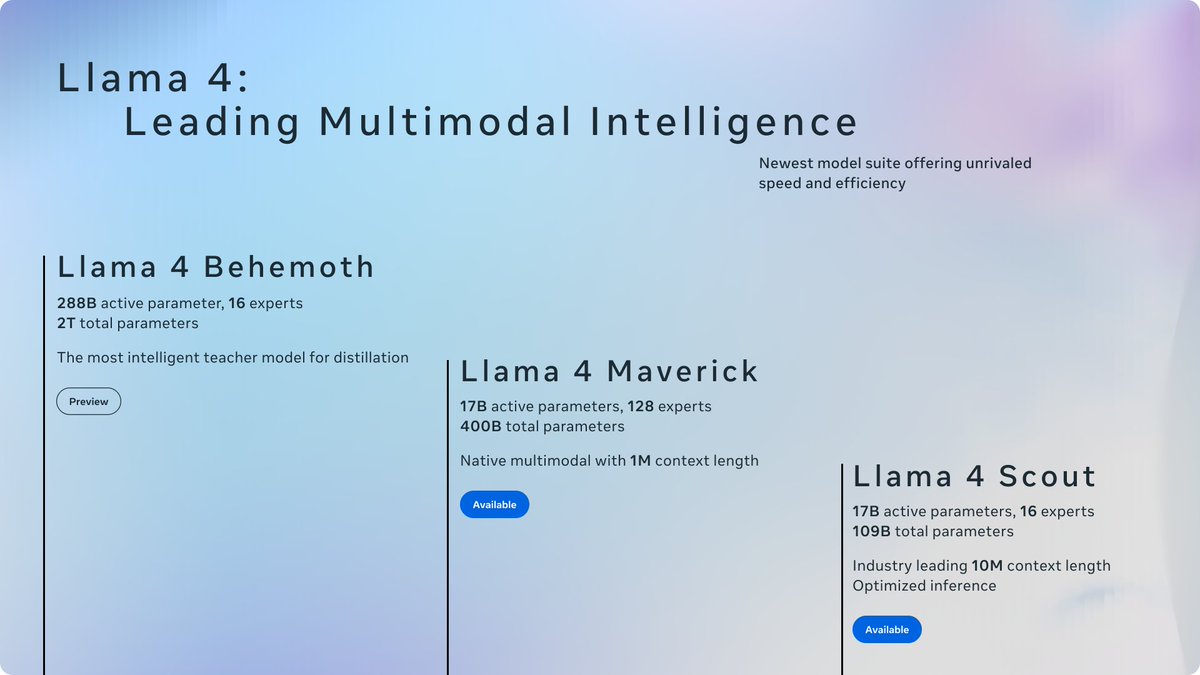
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
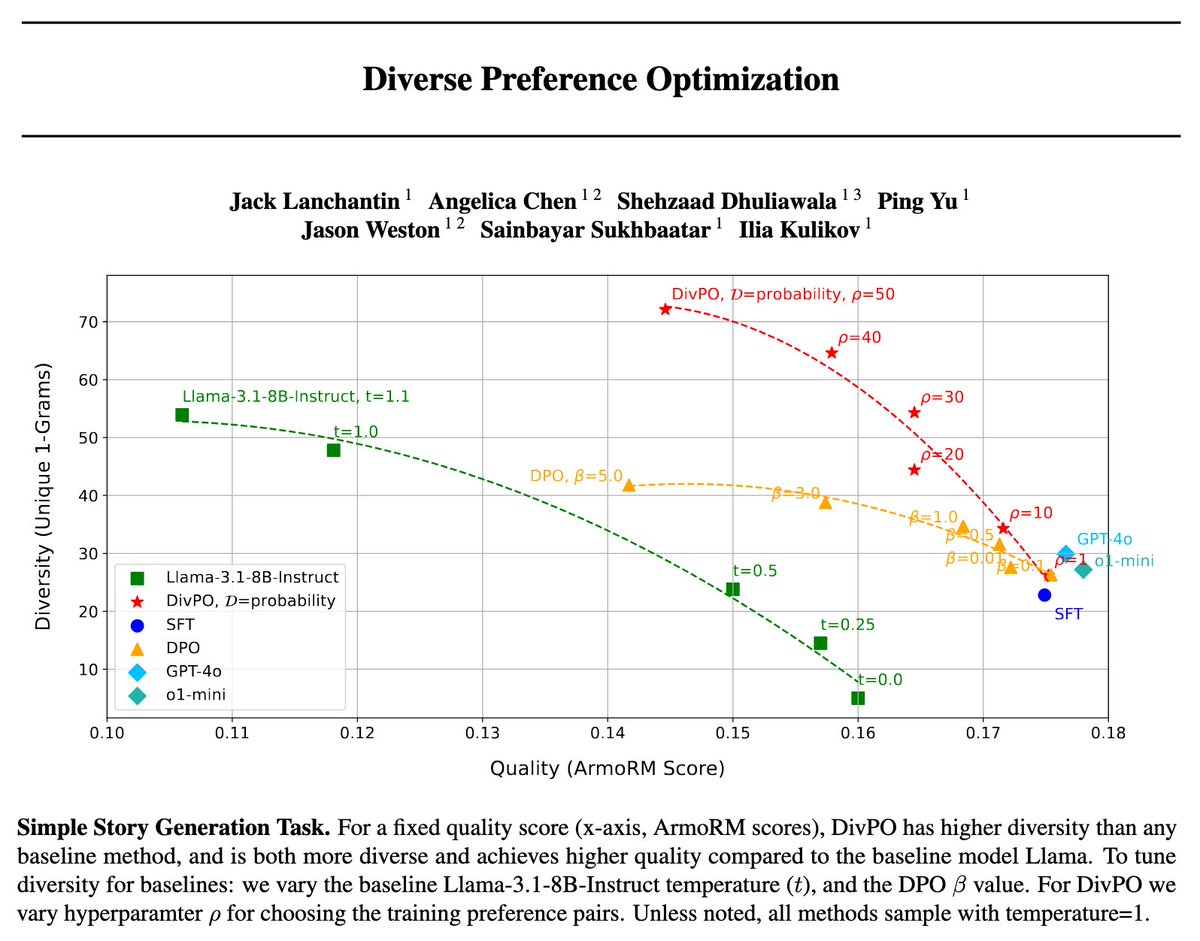
🚨 Diverse Preference Optimization (DivPO) 🚨
SOTA LLMs have model collapse🫠: they can't generate diverse creative writing or synthetic data
🎨 DivPO trains for both high reward & diversity, vastly improving variety with similar quality.
Paper 📝: https://t.co/bRwq3d3wJq
🧵below
We released new research - Byte Latent Transformer(BLT)
BLT encodes bytes into dynamic patches using light-weight local models and processes them with a large latent transformer. Think of it as a transformer sandwich!
New from Meta FAIR — Byte Latent Transformer: Patches Scale Better Than Tokens introduces BLT, which for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency & robustness.
Paper ➡️ https://t.co/0iamZCRnMN
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯
Paper 📄 https://t.co/5QGrlJdK0y
Code 🛠️ https://t.co/jCdDI5BXwe
Excited to share more about our background, vision and where we're headed at @agemoai with @r1ddhi at @BusinessInsider
𝗢𝘂𝗿 𝘃𝗶𝘀𝗶𝗼𝗻 𝗶𝘀 𝘁𝗼 𝗲𝗻𝗮𝗯𝗹𝗲 𝗮𝗻𝘆𝗼𝗻𝗲 𝘁𝗼 𝗰𝗿𝗲𝗮𝘁𝗲 𝘀𝗼𝗳𝘁𝘄𝗮𝗿𝗲 – from an idea to fully deployed software. The critical path to achieve it requires building AI systems that can reason about software at a fundamental level.
𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝘀 𝗮𝗿𝗲 𝗻𝗼𝘁 𝘁𝗵𝗲 𝘀𝗼𝗹𝗲 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻, 𝗯𝘂𝘁 𝗮𝗿𝗲 𝗽𝗮𝗿𝘁 𝗼𝗳 𝘁𝗵𝗲 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻. Since inception, our research focus at agemo has been on leveraging neurosymbolic methods to build a reasoning system for software. With the first implementation and training of this system done, we have been iterating on a platform for non-coders to generate software.
We are fortunate to be backed by @FlyVC and @firstminutecap alongside pioneers in the field at @GoogleDeepMind and @Meta .
Read more about our story at https://t.co/hqDmgFPdvX
🌍 I’ve always had a dream of making AI accessible to everyone, regardless of location or language. However, current open MLLMs often respond in English, even to non-English queries!
🚀 Introducing Pangea: A Fully Open Multilingual Multimodal LLM supporting 39 languages! 🌐✨
https://t.co/lHP1CSNNVe
https://t.co/RkMdE4JSQg
The Pangea family includes three major components:
🔥 Pangea-7B: A state-of-the-art multilingual multimodal LLM capable of 39 languages! Not only does it excel in multilingual scenarios, but it also matches or surpasses English-centric models like Llama 3.2, Molmo, and LlavaOneVision in English performance.
📝 PangeaIns: A 6M multilingual multimodal instruction tuning dataset across 39 languages. 🗂️ With 40% English instructions and 60% multilingual instructions, it spans various domains, including 1M culturally-relevant images sourced from LAION-Multi. 🎨
🏆 PangeaBench: A comprehensive evaluation benchmark featuring 14 datasets in 47 languages. Evaluation can be tricky, so we carefully curated existing benchmarks and introduced two new datasets: xChatBench (human-annotated wild queries with fine-grained evaluation criteria) and xMMMU (a meticulously machine-translated version of MMMU).
🙌 This is a joint leading effort with @yueqi_song. Also kudos to the amazing team @AkariAsai, @seungonekim, @Jeande_d, @simi_97k, @anjali_ruban, @lintangsutawika, @Sathya8NR, @gneubig for their hard work!
Check out more results and insights we conclude from our training in the thread below. 👇
Thanks Tu :). Interesting! That's definitely relevant to our work, thanks for sharing!
In our case we found that merging/swapping language-specific expert layers and English Math expert layers transfers effectively at test time to target languages. Doing it in a parameter-efficient setting was degrading the test performance in our setup but there is definitely more work to be done there.
Recent LLMs (e.g. LLama 3 🦙) are increasingly good at Math.
However, this progress is reserved for languages with large amounts of task-specific instruct-tuning data.
In this work @AIatMeta (led by @LucasBandarkar ), we introduce a new model merging technique called **Layer Swapping** and find that combining Math and Language-Specific experts improves the performance of Llama 3 for specific languages (e.g. #Bengali) on Math queries
Arxiv and detail in the thread below 🧵
Cross-lingual transfer can be as easy as swapping model layers between LLMs! 🔀
Our model merging method can compose math and language skills by swapping top&bottom layers from a SFT’d target language expert into a math expert without retraining https://t.co/IN5JPdTYU4 🧵: [1/3]
























![LucasBandarkar's tweet photo. Cross-lingual transfer can be as easy as swapping model layers between LLMs! 🔀
Our model merging method can compose math and language skills by swapping top&bottom layers from a SFT’d target language expert into a math expert without retraining https://t.co/IN5JPdTYU4 🧵: [1/3] https://t.co/q4K5ZAiFtz](https://pbs.twimg.com/media/GZD6Oo5XwAACCAA.jpg)






























