Been using Dropstone Max myself.
Weekly cap is much higher than the others. Frankly absurd by category standards.
No session limit either. Matters more than people realize once you've coded for a full day.
Spending most of the next two weeks on the capacity layer.
@dropstoneio Dropstone CLI stands among our strongest internal tools, alongside Primus. We're proud of what the team has built and remain fully committed to its continued development.
The Dictionary at the End of the Wire.
Capital, compute, and energy spent on AI are rising sharply. New scientific knowledge is not.
More on this: https://t.co/ozn80wXQzW
Measuring weekly coding-turn capacity across frontier CLI plans at $15-$20 and $75-$100 tiers.
Methodology and cross-validation: https://t.co/IcsOupwln7
The Dropstone 1.5 Technical Report is live. It covers the runtime architecture, the eval methodology, and our measured prefix-cache hit rate in production coding sessions, sustaining 95%.
We re-baseline monthly to the best open-weight model.
Read more:
https://t.co/82ByzHpNty
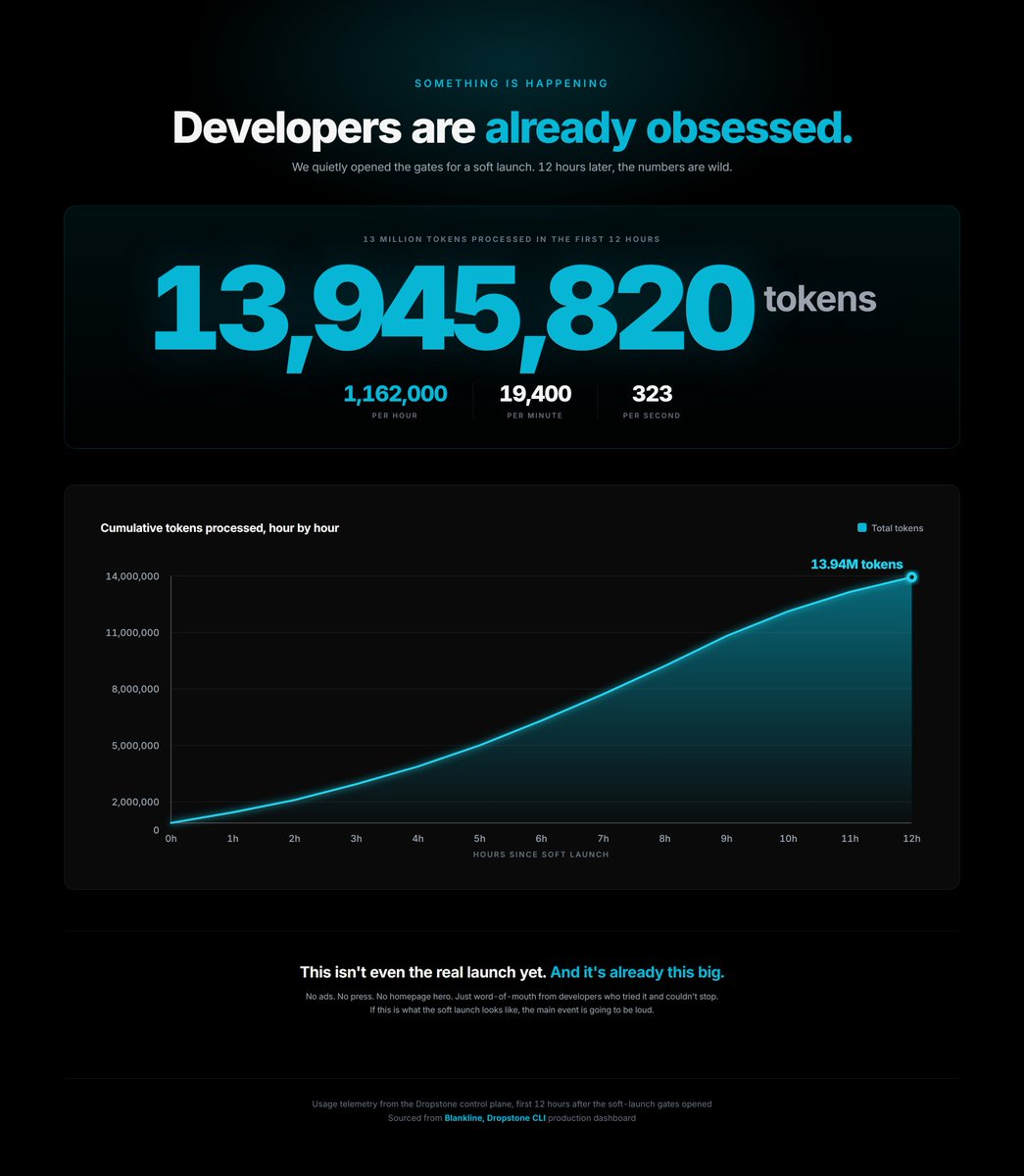
12 hours ago we opened Dropstone 1.5 quietly. No homepage, no press, no announcement. Developers have already run 13.9M tokens through it.
For organic usage with zero marketing, we can't find a stronger dev-tool soft launch on record.
Try it: https://t.co/v5OYShfvbA
Introducing Dropstone 1.5: frontier coding intelligence, for everyone.
Outperforms Claude Opus 4.7, GPT-5.5 Pro, and Gemini 3.1 Pro on real-world coding with full-time usage on every plan.
Available today.
Dropstone runs on the best open-weight frontier model each month DeepSeek V4 Flash for Fast Deepseek V4 Pro Pro, Moonshot Kimi K2.6 for Heavy on US-hosted infrastructure with zero data retention.
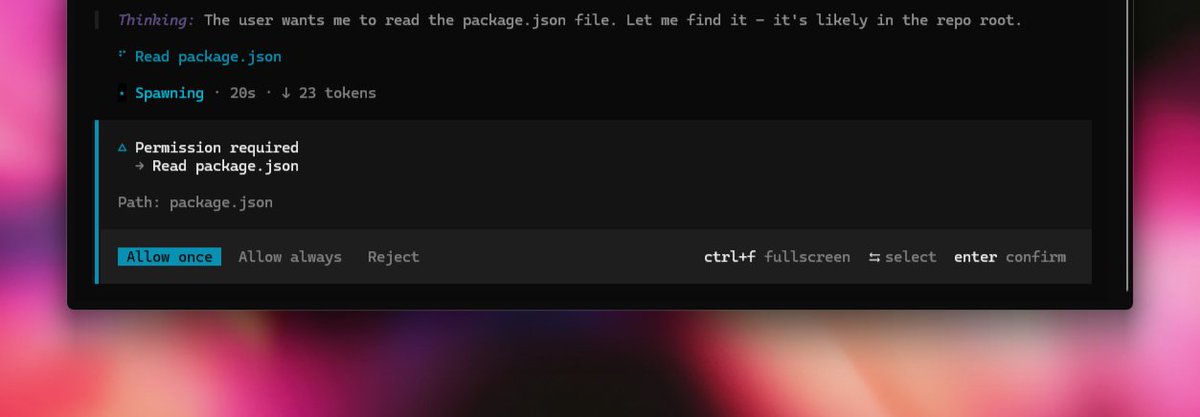
Every tool call needs your approval. Output is text until you authorize.
13 Million Tokens in less than 12 Hours for a soft launch is wild.
Guys slow down. I wonder what would happen at 6:30 PM IST.
I genuinely have no idea what we're about to walk into.
Live leaderboard and methodology: https://t.co/HRRy3uR2NE
Open repository (MIT + CC-BY 4.0): https://t.co/HgVAsxFB2M
Full research note: https://t.co/J81u3ksJ5o
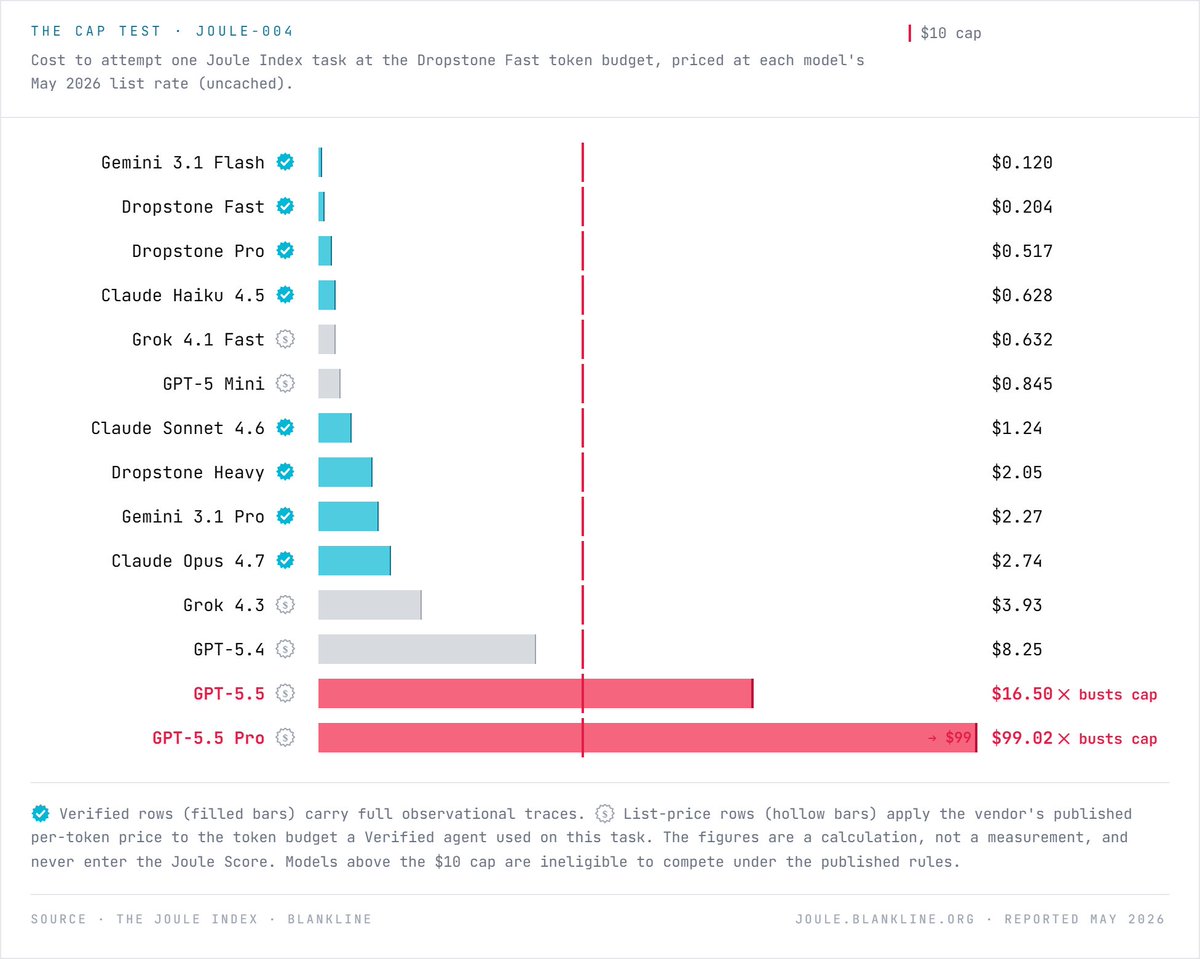
Same code. Twelve times the bill.
Three real May 2026 OSS bugs. Five AI coding agents from four vendors produced the same merged diff.
Cheapest cost $0.08. Flagship paid 12.5× that for
identical engineering output.
The Joule Index, released today by Blankline.
What does a Joule Index task actually cost on
unsubmitted frontier models, priced at each vendor's
own May 2026 list rate?
GPT-5.5 Pro: $99 per task.
The benchmark publishes a $10 per-task cap. That cap exists for a reason. Five frontier tiers can't compete.