Read on with our recently released preprint @biorxivpreprint :
https://t.co/TqtL6rIDWb
Many thanks to my collaborators @Al_Murphy_@n_skene, the @Bioconductor team, and the amazing users who contribute invaluable feedback and improvements!
🦠 🔁 🐟 🔁🐁 🔁 🐒 🔁 🏃♀️
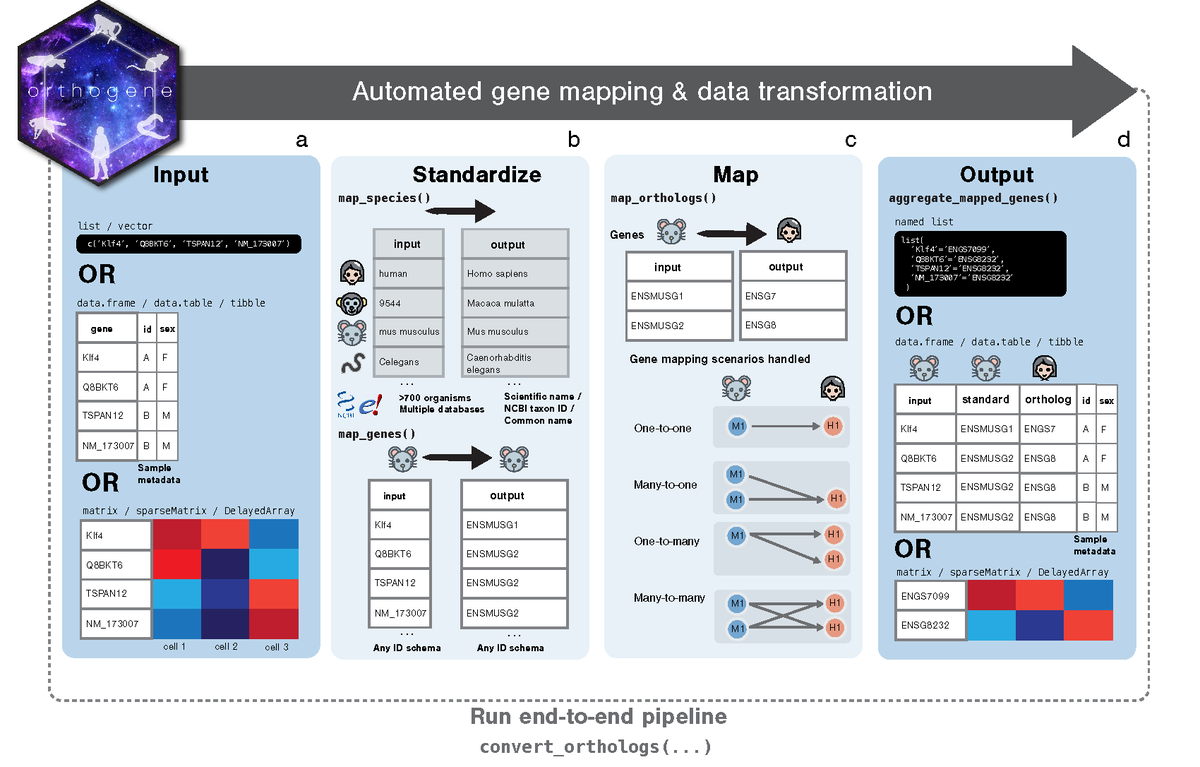
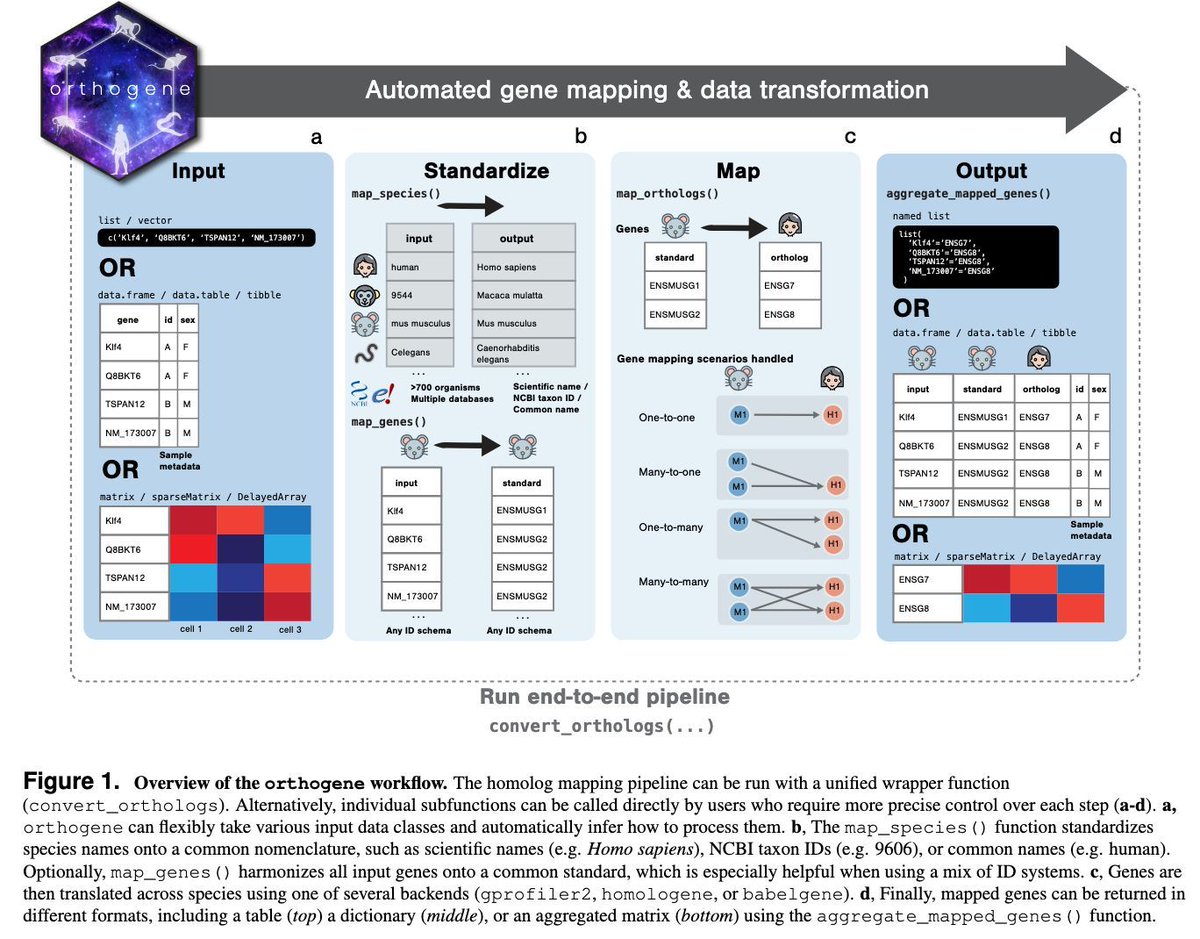
Mapping genes across ID systems 🆔🔁🆔 and species 🌱🦠🐛🐟🐭🐵🧓 is ubiquitous in biology ...and yet far harder than it should be.
orthogene makes this dead simple. It then goes beyond by handling complex homology (1:1, 1:many, many:many), a crucial step most tools ignore. 🧵
Run the whole workflow in one function or customize with exposed internals.
Let orthogene handle tedious gene mapping, so you can focus on your science. 👩🔬
📦 https://t.co/Ovf39ujgpy
📖 https://t.co/Dvds9nDyrv
#Genomics#Bioinformatics#Reproducibility#RStats#OpenScience
@grok@CRISPRKING@strnr Hey @CRISPRKING , lead developer of orthogene here. Confirming that @grok is indeed correct, orthogene was designed precisely to fill this gap and handle lots of different homology mapping scenarios gracefully (with strategies still user-adjustable)
🗨️ Just published in @NatureBiotech: Our CellWhisperer AI enables chat-based analysis of single-cell sequencing data. You can talk to your cells & figure out the biology without writing any computer code. Paper link and annotated walkthrough in the thread below (1/11)
Today @AnthropicAI released PubMed integration for Claude. No hallucinations. Just real science, real data. As a beta tester, this has been a game changer—like having a supercharged research assistant. Here are 6 prompts that will transform how you search the literature. A 🧵
Uncovering the Mechanistic Landscape of Regulatory DNA with Deep Learning
1. A new computational framework named SEAM (Systematic Explanation of Attribution-based Mechanisms) has been introduced, combining deep learning with explainable AI to map the mechanistic impact of genetic mutations on regulatory DNA.
2. SEAM deciphers complex cis-regulatory mechanisms by generating synthetic sequence libraries, computing attribution maps, clustering these maps to identify shared mechanisms, and analyzing how mutations rewire regulatory logic.
3. The framework reveals two distinct classes of regulatory signals: robust signals that are resistant to mutations and reprogrammable signals that can be easily altered by mutations.
4. SEAM demonstrates remarkable evolvability of regulatory DNA, showing that minimal sequence changes can significantly reconfigure motif syntax or activate new mechanisms.
5. Applied to human and Drosophila regulatory loci, SEAM uncovers functional binding sites and identifies mutations that preserve, disrupt, or create novel binding sites.
6. SEAM generalizes across diverse sequence libraries, including exhaustive mutagenesis libraries, optimized libraries from directed evolution, and global libraries probing broad properties of motifs and their context.
7. The study highlights SEAM's potential to bridge AI-based modeling with experimental data across diverse biological domains, advancing regulatory genomics toward mechanism-level reasoning.
💻Code: https://t.co/jqRABhS49u
📜Paper: https://t.co/5b21PaSyWY
#DeepLearning #RegulatoryDNA #Genomics #AI #ComputationalBiology #SEAM
MetaGraph: Searching the world’s DNA at petabase scale
Modern biology is drowning in data. Public sequencing archives now hold more than 67 petabases of DNA and RNA—yet, paradoxically, most of it is beyond search. Finding a gene, variant, or viral fragment across this ocean typically requires massive downloads and alignment pipelines that take days or weeks.
Mikhail Karasikov and coauthors present MetaGraph, a system that makes this global collection of raw sequencing data searchable. Instead of storing billions of DNA fragments as static files, MetaGraph organizes them into an enormous interconnected graph—where similar sequences are linked and context is preserved. This structure compresses the data dramatically and allows searches to run directly on it, skipping the need for costly preprocessing or data movement.
With this reimagined architecture, the team can track antibiotic-resistance genes across ecosystems, uncover hidden RNA molecules in cancer samples, and discover new viruses in environmental data—all at speeds and costs that make such analyses accessible to ordinary research labs.
The implications go far beyond genomics. Tools like MetaGraph blur the boundary between data storage and computation—much like in-memory computing is reshaping AI hardware. In essence, biology now gains its own version of a “search engine,” one that could soon power large biological models and continuously updated genomic maps.
A striking step toward an era where life’s code becomes as searchable and useful as the web itself.
Paper: https://t.co/BgFm6E9shO
Which mutations rewire function of regulatory DNA?
Excited to share SEAM: Systematic Explanation of Attribtuion-based Mechanisms. SEAM is an explainable AI method that dissects cis-regulatory mechanisms learned by seq2fun genomic deep learning models.
Led by @EESetiz
1/N 🧵👇
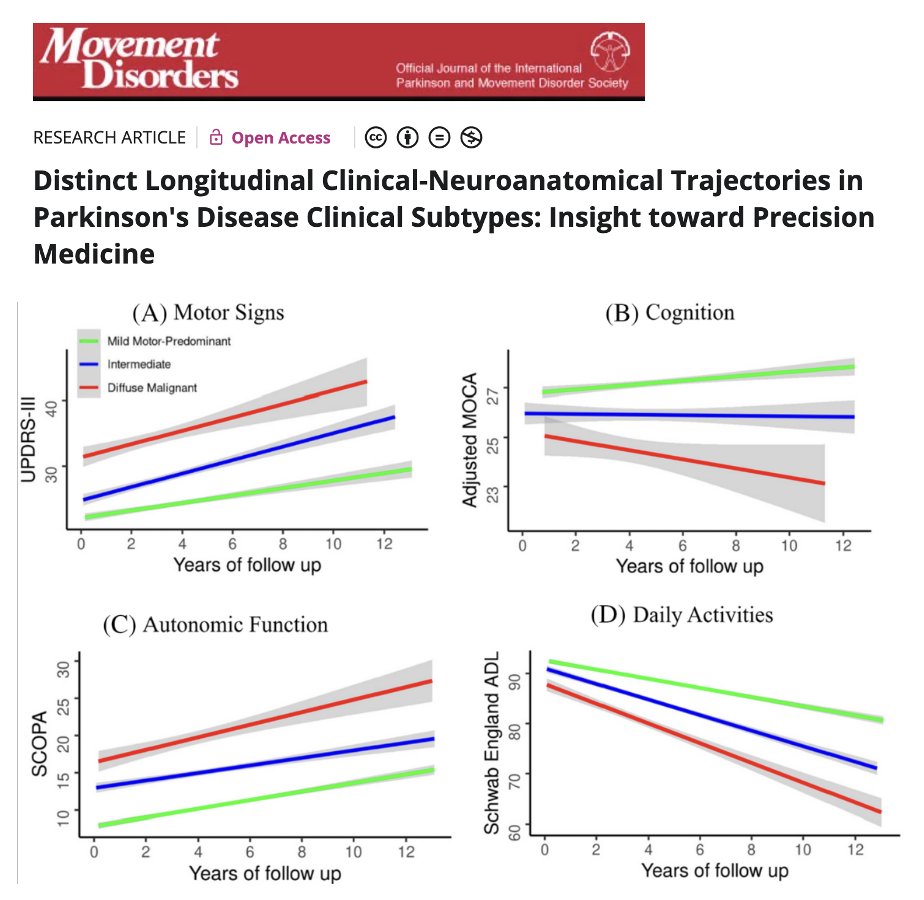
When Parkinson’s subtypes just won't stay in their lane, what do you do? Is it time to rethink the clinical phenotypes? For years, we’ve tried to box Parkinson’s into tidy clinical subtypes like tremor-dominant, postural instability and gait subtype (PIGD), and also the akinetic-rigid subtype. However a growing body of research reveals a truth: Parkinson’s phenotypes don’t stay still. They shift over time, leaving us chasing a moving target. Seyed-Mohammad Fereshtehnejad and colleagues ask the question whether longitudinal trajectories can help us?
Key Points:
- Longitudinal studies show that up to half of people with Parkinson’s change phenotypic subtype w/in a few years.
- The tremor-dominant subtype frequently evolves into a more gait-affected, cognitively vulnerable pattern.
- These shifts challenge how we design trials, track progression, and personalize treatment.
My take: There are 5 key messages that emerge from this paper. 1- Parkinson’s disease is not static. Classifications like tremor-dominant are important to appreciate more as simple snapshots and not as lifelong identities. 2- Phenotypic drift affects everything. From drug response to fall risk and also cognitive changes. Clinicians must stay clinically flexible and open minded. 3- Rigid subtyping (no pun intended) can mislead. What helps in early diagnosis may fail in long-term care or in trial design. We need dynamic tracking tools. 4- Wearables, biomarkers, and evolving models must replace these one-time classifications. 5- It’s time to treat the person, not the phenotype. Real-world changes that inevitably emerge in Parkinson’s progression demand a real-time, more personalized approach.
https://t.co/I7ulj69e7D
Su and colleagues also recently described PACE subtypes of PD using AI and trying to predict longer term disease trajectories.
https://t.co/awc4vztlDn
#Parkinsons #PhenotypeShift #NeurologyResearch #PrecisionMedicine @ParkinsonDotOrg@FixelInstitute
The premier conference on Machine Learning for Computational Biology is Sep 9-10 at the NY Genome Center in NYC!
Submission deadline is June 1 for 2-page abstracts and 8-page papers (eligible for proceedings track).
Registration is now open! (Link below)
Please retweet!
Thank god for @biorxivpreprint - why does a benchmarking paper for a novel technology require 3.5 years in review and 168 pages of review responses? Do we not all have better things to do?