“Pure Python” and “fast” don’t usually go together.
We used mypyc to speed up SQLGlot by up to 5x without rewriting it in Rust or changing the codebase.
This post breaks down how we squeezed as much performance from a large Python project as possible: https://t.co/izaL1iIcPL
SQLMesh is a Python framework that makes writing and orchestrating SQL easier. All you have to do is write SQL and SQLMesh will figure out the rest. It can find dependencies automatically (no need for ref). It understands what has been done and what needs to be done (cron and version tracking). It even performs syntax checking and validations so you don't always have to send your queries to the warehouse.
But I guess if you are truly five years old, it'd be something like.
Your mommy and daddy help companies understand what's going on every day. When people buy things on the internet, computers get information. SQLMesh helps your mommy and daddy turn that information into numbers so that they can look at them in pretty pictures to make decisions.
Exciting new feature for @SQLMesh. Custom signals / triggers.
SQLMesh's built-in scheduler controls which models are evaluated when the sqlmesh run command is executed.
It determines whether to evaluate a model based on whether the model's cron has elapsed since the previous evaluation. For example, if a model's cron was @daily, the scheduler would evaluate the model if its last evaluation occurred on any day before today.
Unfortunately, the world does not always accommodate our data system's schedules. Data may land in our system after downstream daily models already ran. The scheduler did its job correctly, but today's late data will not be processed until tomorrow's scheduled run.
You can now use signals to prevent this problem!
Just write a function in Python to determine which intervals are ready to be processed.
https://t.co/2CwaUj89WK
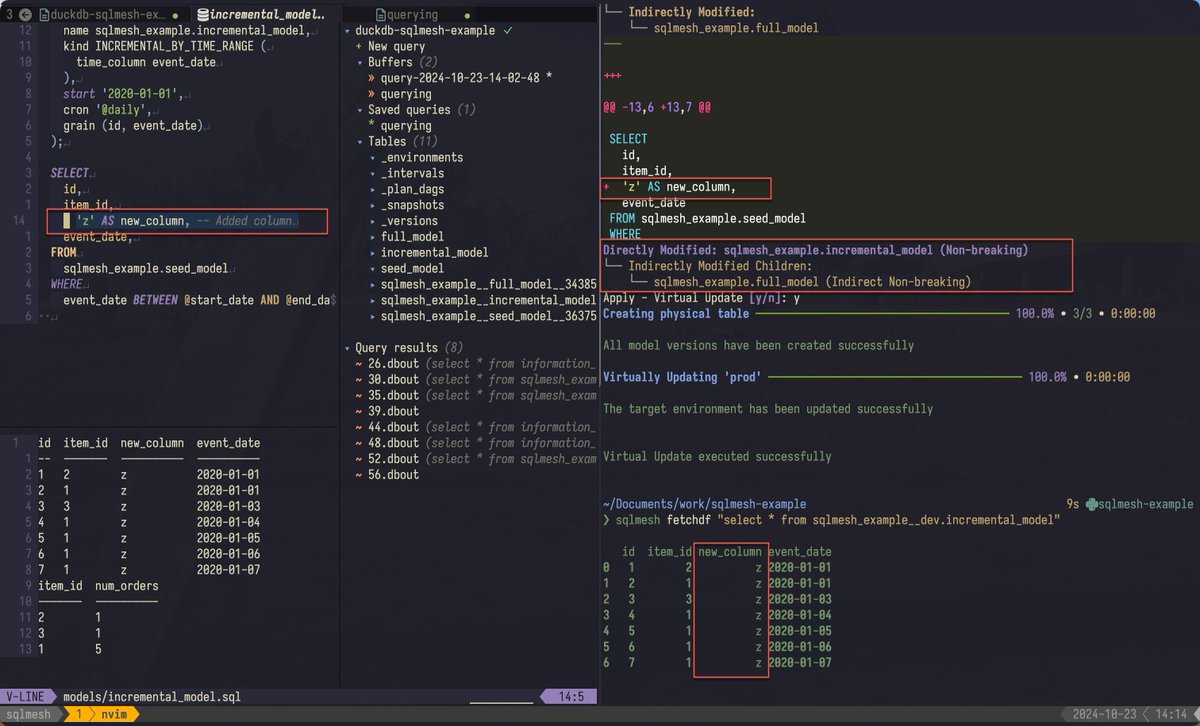
SQLMesh concepts with plans that apply to different environments (prod, dev) are elegant. Even `fetchdf` is integrated into the CLI.
Also, on the right, you see SQLMesh auto-detecting the new columns as non-breaking and simply applying the (virtual) changes `y`.
⚠️⚠️Read this before you start using dbt's microbatch models. There are three large gaps that could lead to serious data issues.
Due to fundamental architectural design choices of dbt, the microbatch implementation is very limited. At its core, dbt is a stateless scripting tool with no concept of time, meaning it is the user's responsibility to figure out what data needs to be processed.
1. dbt's microbatch can lead to silent data gaps
2. dbt's lack of scheduling requires manual orchestration which could lead to incomplete and incorrect data
3. Mixed time granularities in microbatch can cause incomplete data and wasted compute
https://t.co/kh8xK6RXor
Tired of messy data pipelines? 🥹🫣
Check out the @SQLMesh + @dltHub integration for seamless metadata handovers, faster scaffolding, and incremental processing. 💻
Simplify your data workflows! 🔗
https://t.co/F1B1qSTRlp
#DataEngineering#DataPipelines
@SQLMesh is so good it's banned from dbt's Coalesce conference.
If you're interested in learning about what makes it amazing, I'll be in Vegas for the duration of the event.
* Tired of unmaintainable Jinja?
* Want free column level lineage?
* Can't afford expensive full refreshes?
* Incremental models becoming out of sync / needing repair?
* Sick of waiting 10 minutes for your warehouse to tell you you're missing a parenthesis?
Hit me up and we can grab a coffee to talk about how we fix some of the pain.
The wait is over! You can now use Athena with @SQLMesh. Both Iceberg and Hive are supported but we heavily recommend Iceberg since it's a way better experience.
And if you're still stuck on dbt, don't worry, we also have support for the dbt-athena adapter so you can have a seamless migration!
Like always, if you run into any issues, feel free to file an issue or let us know on Slack. We're abnormally responsive :)
https://t.co/6bhvznIpF9
Featuring SQLMesh on this week's episode of Open-Source Spotlight, our series where we're discovering open-source tools.
@TobikoData's Toby Mao, @Captaintobs, joined us in demonstrating how this tool can help data team workflows.
Watch the demo here: https://t.co/3hRx56uZgT
Join @Captaintobs and @Al_Grigor from @DataTalksClub on their Open-Source Spotlight series, where they talk through the benefits of @SQLMesh like:
♦ Column-level lineage
♦ Environment Management
♦ Instant Prod deployments
and much more!
https://t.co/SvUDjvygel
If you’re gonna be at Coalesce in Vegas, make sure to come to @TobikoData’s happy hour October 8 at 5pm!
Also if you just wanna meet up with me and grab a coffee, I’d love to chat! DM me!
https://t.co/UlgyCvPNWM
As a data engineer, you should consider how changes can be done in a non-breaking way.
A non-breaking change to a data model is something that won't have any down stream impact, like adding a column or re-ordering columns. Adding columns only impacts down stream models when they do SELECT * statements, which is one of the reasons why it's best practice to avoid them.
On the other hand, a breaking change will have significant impact on down stream models and usually requires expensive back-fills. An example of a breaking change is modifying a WHERE statement which changes the cardinality of a table.
If you're working at any significant scale where it's expensive and time consuming to back-fill many tables, consider whether or not a change can be done in a backwards compatible way and how expensive a breaking change would be. If it's not very expensive to make a breaking change, it can be easier to maintain since all models are kept up to date without any legacy, so there's always a trade-off.
Even if it's not too costly to back-fill many tables, it can be time consuming communicating breaking changes to stakeholders or validating all data consumers are up to date. Arguably, this is even more challenging than the technical/compute costs of breaking changes.
As a software engineer, it's commonplace to consider whether changing an API or a database model should be done in a breaking or non-breaking fashion. I believe this best practice should be adopted by data teams as well.
That's why we designed #SQLMesh to provide automatic detection of breaking and non-breaking changes by analyzing your SQL queries. This allows you to assess the impact of your changes at compile time and understand potential costs (both compute and organizational) before you finalize your changes.
https://t.co/0kahh6t0qJ