We've lost an absolute giant today. RIP Dimitri Bertsekas. His probability and optimization books got me through my masters. Massive loss for the MIT community and the field.
@Sagar_kr_Maity@AnnaLeptikon You absolutely have to read Paul Diarac’s biography, The Strangest Man.
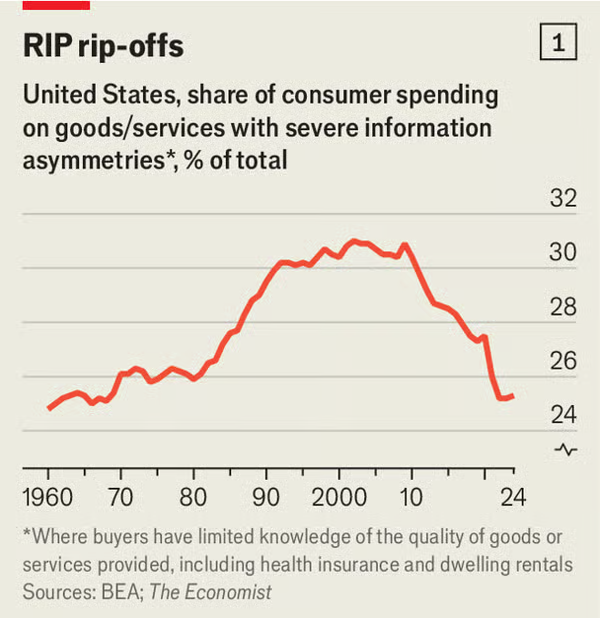
This was one of the best biographies I’ve ever read.
We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
Gemini 3 Pro 🤝 Nano Banana Pro
New SOTA image generation and editing.
🍌Production-ready visuals with improved precision and control
🍌Images grounded in Gemini’s real world understanding
🍌Superior text rendering
🍌Localization in multiple languages
🍌Physically accurate lighting and dynamics.
And character consistency across 14 (fluffy) inputs!
https://t.co/WfRDyUueWu
Tired of chasing references across dozens of papers? This monograph distills it all: the principles, intuition, and math behind diffusion models. Thrilled to share!
Awesome to see Veo 3.1 top the LMArena video leaderboards by a large distance with big improvements over Veo 3.0 for text-to-video (+30) and image-to-video (+70)! 🔥Huge congrats to the team! Try it for yourself in https://t.co/QgTpxTL8DQ and the @GeminiApp
Veo is getting new precision editing capabilities that let you easily add or remove elements from a scene - all while preserving the integrity of your original video. 🎥
Congratulations to Jesse, Jared @jdlichtman, and Christian @ChrSzegedy on this great result! (They told me and Terry about it weeks ago, but released it while I was giving a lecture series in Italy last week, followed by speaking at a conference this week at Harvard -- where I got to chat some more with Jared; so I’m only now getting around to perusing the blueprint+code.) What I’m impressed by:
(cont'd)
We’re announcing a major advance in the study of fluid dynamics with AI 💧 in a joint paper with researchers from @BrownUniversity, @nyuniversity and @Stanford.
Something fun we discovered: you can use #Genie3 to step into and explore your favorite paintings.
Here's a short visit to Edward Hopper's "Nighthawks".
Yesterday we announced Genie 3. One feature of the model that's especially fun to play with is starting worlds from existing videos. Here's a drone shot generated by Veo 3, with me taking control mid-flight.
Introducing Genie 3, our state-of-the-art world model that generates interactive worlds from text, enabling real-time interaction at 24 fps with minutes-long consistency at 720p. 🧵👇
Excited to introduce Genie 3, our general purpose world model that creates interactive, playable environments from any text prompt. It can generate dynamic worlds at 720p and 24 FPS, with each frame created in response to user actions in *real-time*.
So sad to hear we lost the legendary theatre icon Robert Wilson. Einstein on the Beach 13 yrs ago was a truly formative experience. I went for Philip Glass' music (loved) but Wilson's stage design blew my mind! Sharing a few scenes from works I had the privilege to see. RIP.
I'm observing a mini Moravec's paradox within robotics: gymnastics that are difficult for humans are much easier for robots than "unsexy" tasks like cooking, cleaning, and assembling. It leads to a cognitive dissonance for people outside the field, "so, robots can parkour & breakdance, but why can't they take care of my dog?" Trust me, I got asked by my parents about this more than you think ...
The "Robot Moravec's paradox" also creates the illusion that physical AI capabilities are way more advanced than they truly are. I'm not singling out Unitree, as it applies widely to all recent acrobatic demos in the industry. Here's a simple test: if you set up a wall in front of the side-flipping robot, it will slam into it at full force and make a spectacle. Because it's just overfitting that single reference motion, without any awareness of the surroundings.
Here's why the paradox exists: it's much easier to train a "blind gymnast" than a robot that sees and manipulates. The former can be solved entirely in simulation and transferred zero-shot to the real world, while the latter demands extremely realistic rendering, contact physics, and messy real-world object dynamics - none of which can be simulated well.
Imagine you can train LLMs not from the internet, but from a purely hand-crafted text console game. Roboticists got lucky. We happen to live in a world where accelerated physics engines are so good that we can get away with impressive acrobatics using literally zero real data. But we haven't yet discovered the same cheat code for general dexterity.
Till then, we'll still get questioned by our confused parents.
Want to be part of a team redefining SOTA for generative video models? Excited about building models that can reach billions of users? The Veo team is hiring! We are looking for amazing researchers and engineers, in North America and Europe. Details below:
Btw as an aside, we didn’t announce on Friday because we respected the IMO Board's original request that all AI labs share their results only after the official results had been verified by independent experts & the students had rightly received the acclamation they deserved