New paper:
We present a "Unified Neural Scaling Law" functional form that accurately models & extrapolates the multivariate scaling behaviors of artificial neural networks as the variables listed in this attached video are varied.
(1/N)
ever been here?
open overleaf → write a paragraph → "hmm...this needs a citation" → open 15 different tabs → skim 8 abstracts → find the 1 actually relevant paper → format bibtex → paste it back on overleaf
if so, i built a plugin just for you. meet openleaf:
→ reads your paper paragraph by paragraph
→ searches major academic databases
→ filters out irrelevant papers using ai
→ one click to add BibTeX to your .bib
you'll also find the 🤝 friendly and 🔥 fire reviewers there. i don't think i need to tell you what they do :)
free. open source. no account. no data collection.
works with ollama, openrouter, openai api and more.
https://t.co/XvX03iem38
dear algorithm, please show this to my fellow researchers in need 🙏
#overleaf #latex #opensource #academictwitter
I gave a talk on LLM zero-sum learning dynamics last week at MSR Montreal. I went over a few things that were not in the paper but that I'm particularly excited about; one of those is the connection between generalization and zero-sum learning. https://t.co/di3iLLytvO
Mila's annual supervision request process is now open to receive MSc and PhD applications for Fall 2026 admission! For more information, visit https://t.co/r01eLcY1P4
New to ML research? Never published at ICML? Don't miss this!
Check out the New in ML workshop at ICML 2025 — no rejections, detailed feedback, awards, and ICML tickets for selected authors.
Deadline: June 10 (AoE)
Submit: https://t.co/xNiccKTelq
Info: https://t.co/1dBY6bnGji
LLMs have complex joint beliefs about all sorts of quantities. And my postdoc @jamesrequeima visualized them! In this thread we show LLM predictive distributions conditioned on data and free-form text.
LLMs pick up on all kinds of subtle and unusual structure: 🧵
This is fun because LLMs can condition on free-form side information, and make predictions about anything. This turns qualitative knowledge into quantitative predictions.
Here we condition Llama 3 on two datapoints, plus text. Changing the text changes the meaning of the data.
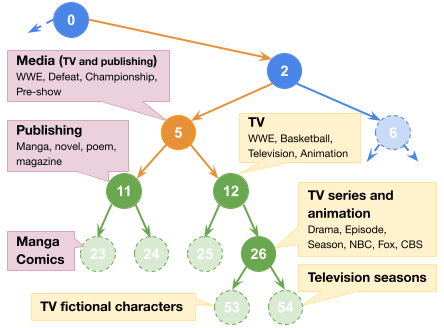
🚀 We have released our paper on ReTreever! 🌳🔍
ReTreever organizes and represents documents in a binary tree across various granular levels, balancing cost & utility while enhancing retrieval transparency.
📜 Read it here: https://t.co/4VlePz5e1K
#AI@ServiceNowRSRCH
🧵👇
Happy to announce AlignVLM📏: a novel approach to bridging vision and language latent spaces for multimodal understanding in VLMs! 🌍📄🖼️
🔗 Read the paper: https://t.co/czaL8NrlZL
🧵👇 Thread
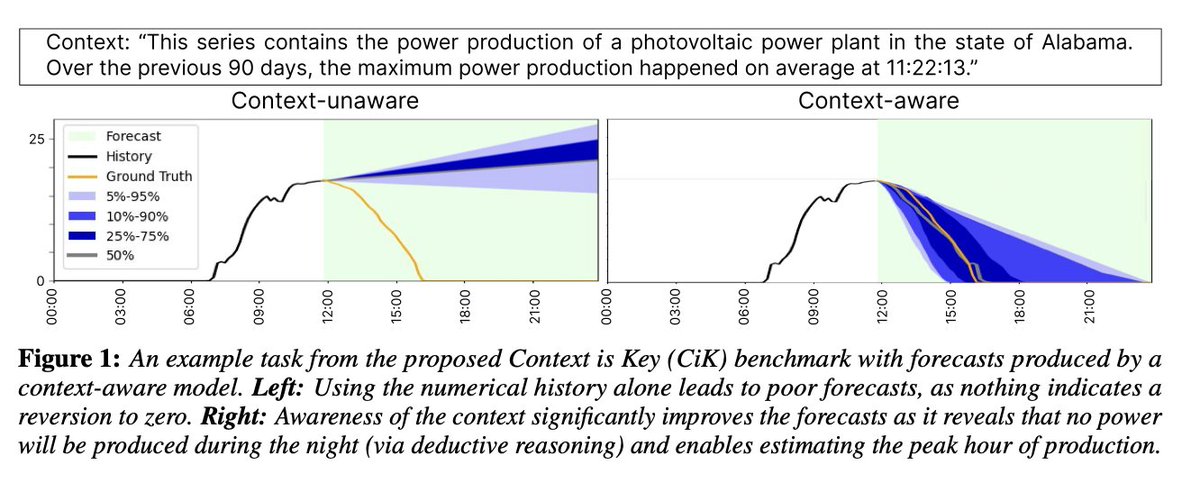
this is paper is kinda wild. turns out that if you simply ask an LLM to straight out predict a timeseries like this:
```
<history>
(t1, v1) (t2, v2) (t3, v3)
</history>
<forecast>
(t4, v4) (t5, v5)
</forecast>
```
making sure to prepend the prompt like this:
```
Here is some context about the task. Make sure to factor in any background knowledge, satisfy any constraints, and respect any scenarios.
<context>
((context))
</context>
```
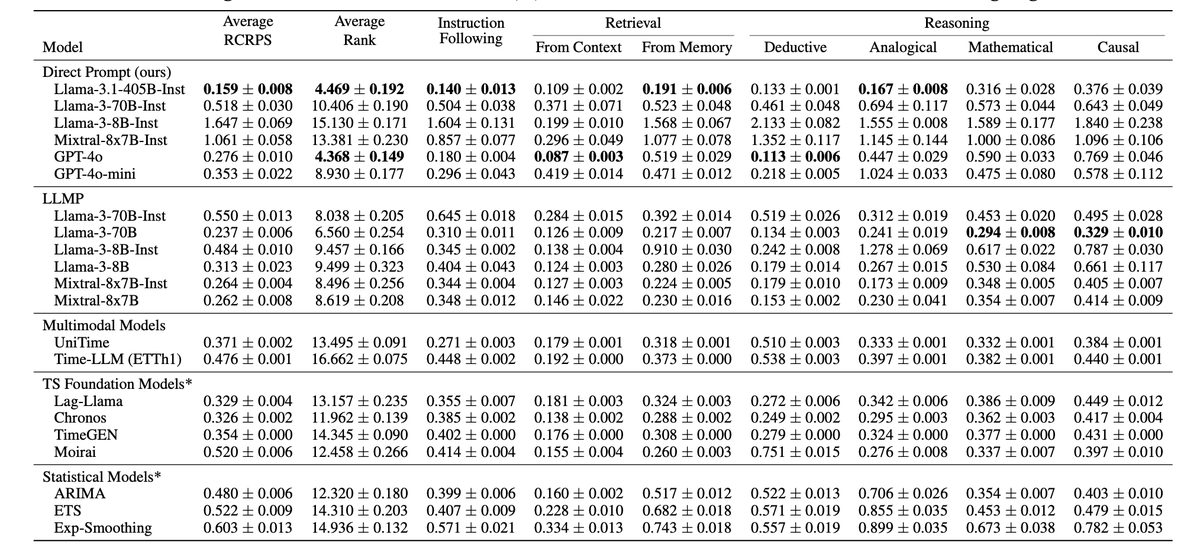
it will just… do it? beating SOTA timeseries forcasting?!
llama 3.1 405b directly prompted is more precise at forecasting real-world series than:
- stats-based timeseries models (ARIMA, ETS)
- foundation models specifically trained for time series (eg. chronos)
- multimodal forecasting models (eg, time-LLM)
peak 'bitter lesson' behavior lol
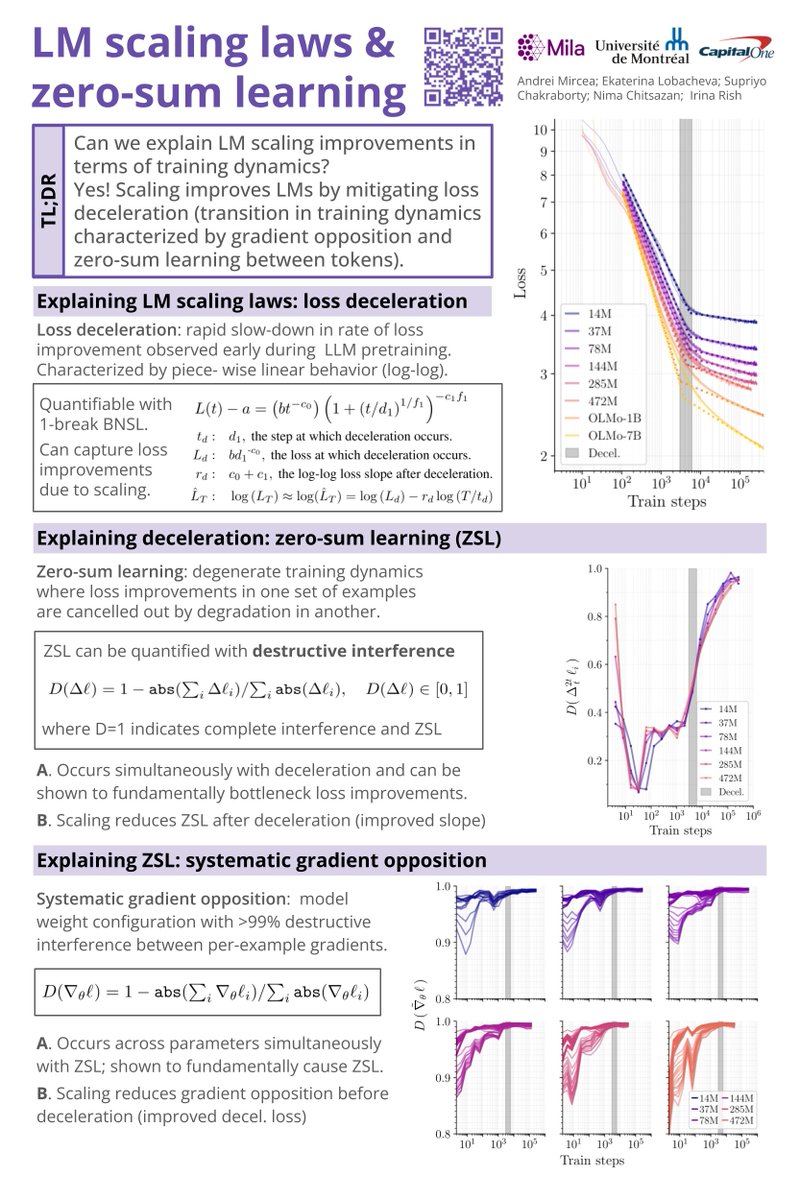
📢 New paper “Language model scaling laws and zero-sum learning” @scifordl#NeurIPS2024
ℹ️https://t.co/abMHR2C75M
TL;DR: scaling improves LMs by mitigating zero-sum learning, a mechanism that could be targeted directly and independent of scale.
W205 @ 4:30pm
(1/12)🧵
Starting the workshop on Time Series in the Age of Large Models (TSALM) at #NeurIPS2024 with @tomaspfister's invited talk on Multimodal Time Series Modeling!
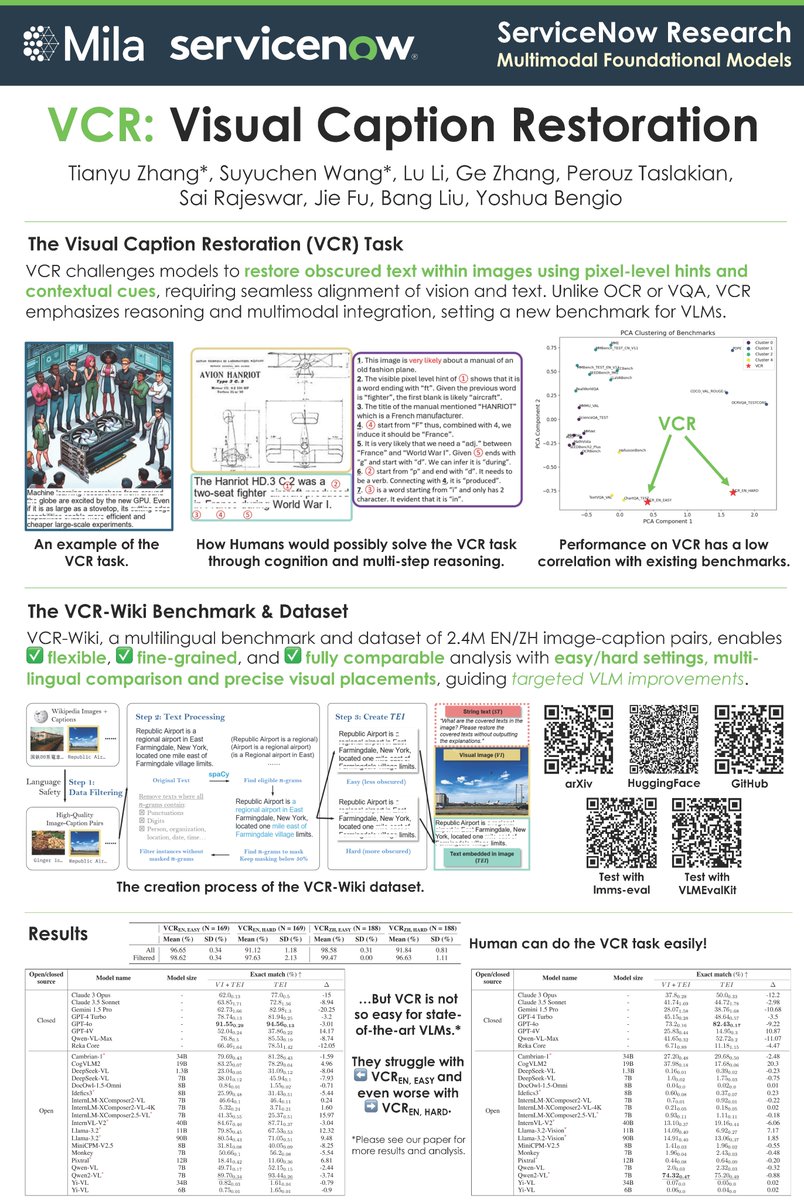
🚀 Excited to present our work on VCR: Visual Caption Restoration – the 1st and unique VLM benchmark testing if VLMs can focus on tiny but crucial details!
📍 Join us at #NeurIPS24 on Sunday, Dec 15, West Ballroom B
🛠️ Dive into the details: https://t.co/GRUljO3TFg
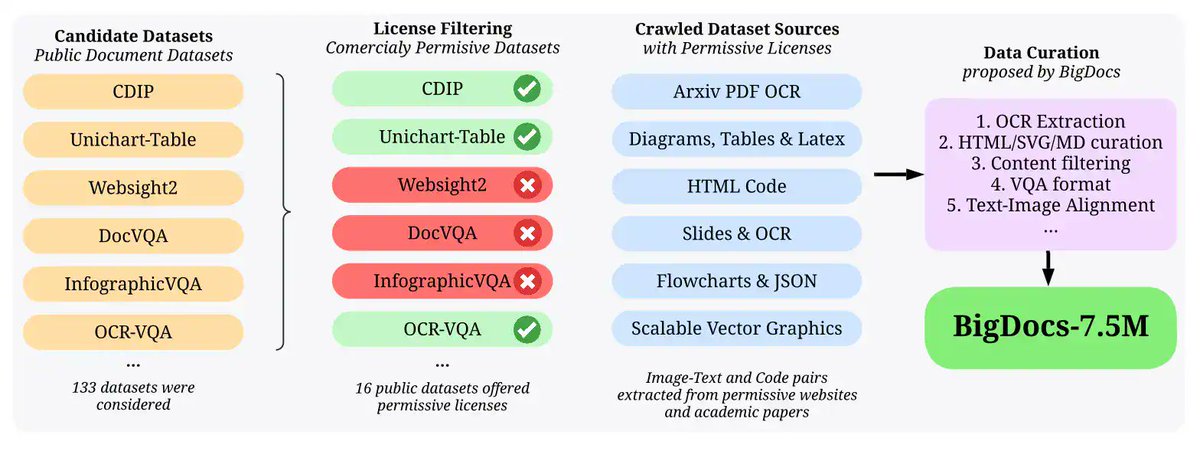
🚀A game-changer for open-access multimodal AI! BigDocs is paving the way for transparent, accountable, and innovative document reasoning and code generation. Check it out! 💡👏
Learned optimizers can’t generalize to large unseen tasks…. Until now! Excited to present μLO: Compute-Efficient Meta-Generalization of Learned Optimizers! Don’t miss my talk about it next Sunday at the OPT2024 Neurips Workshop :) 🧵https://t.co/UiCr4EQ5s9 1/N
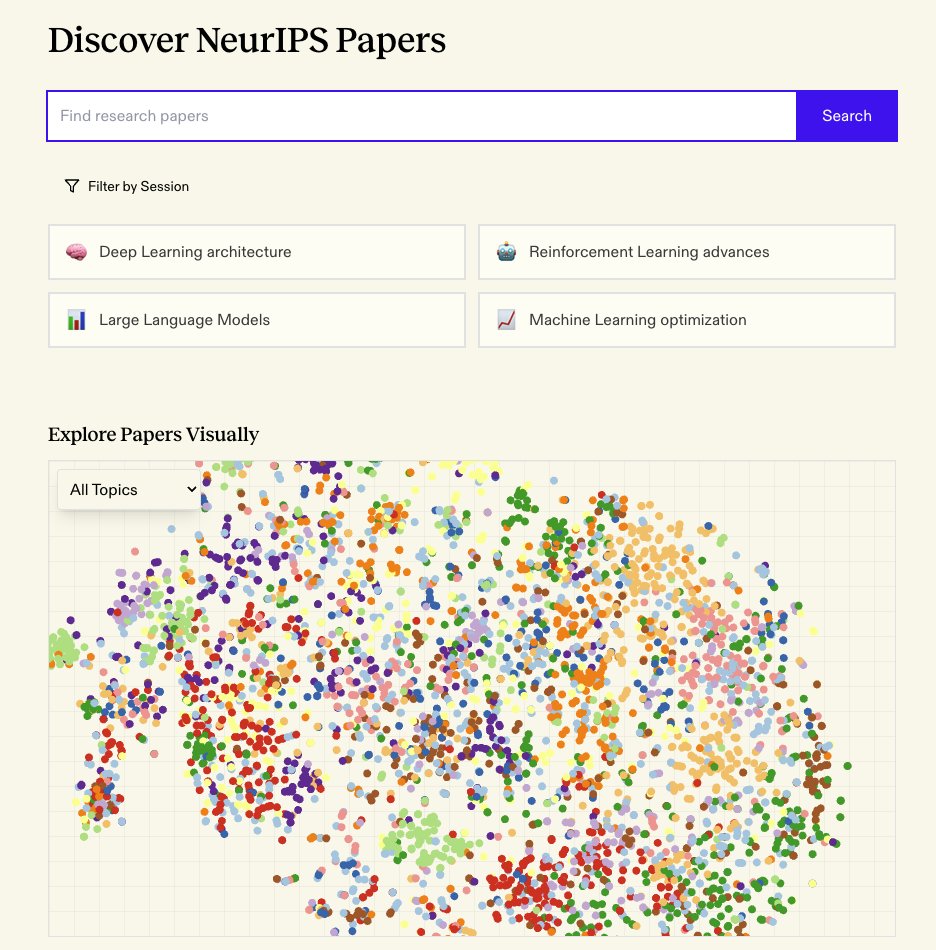
Spent the weekend hacking together Exa embeddings over 4500 NeurIPS 2024 papers - https://t.co/gazgno2hfk
Let's you:
- do otherwise impossible searches ("transformer architectures inspired by neuroscience")
- explore a 2D t-SNE plot
- chat with Claude about multiple papers
🌟🌟🌟 We just released BigDocs: An Open Multimodal Dataset — our latest work on scaling document understanding across diverse data types! 📄
👉 Dive into the details: https://t.co/KfOKZKARDS
🧠 or come see us at the #NeurIPS2024 RBFM workshop!
#AI@ServiceNowRSRCH#bigdocs