Qwen 3.5 has the best SLMs to fine-tune!
Its 4B model is really smart if you train it on a well structured dataset.
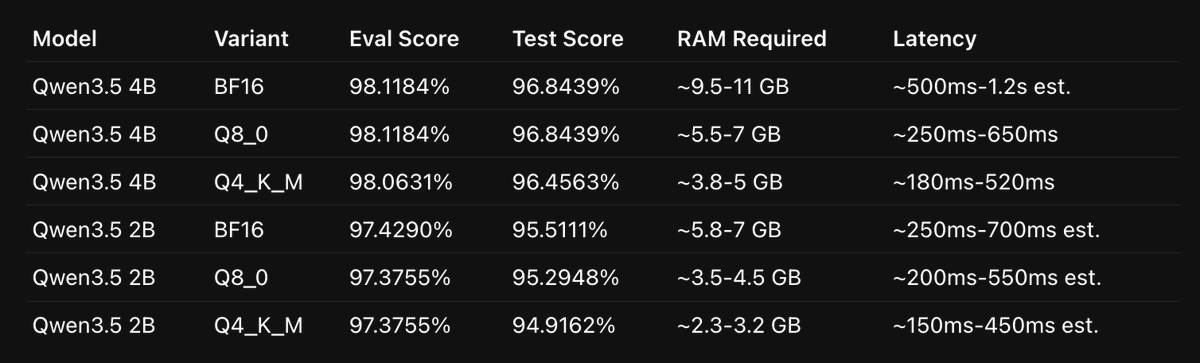
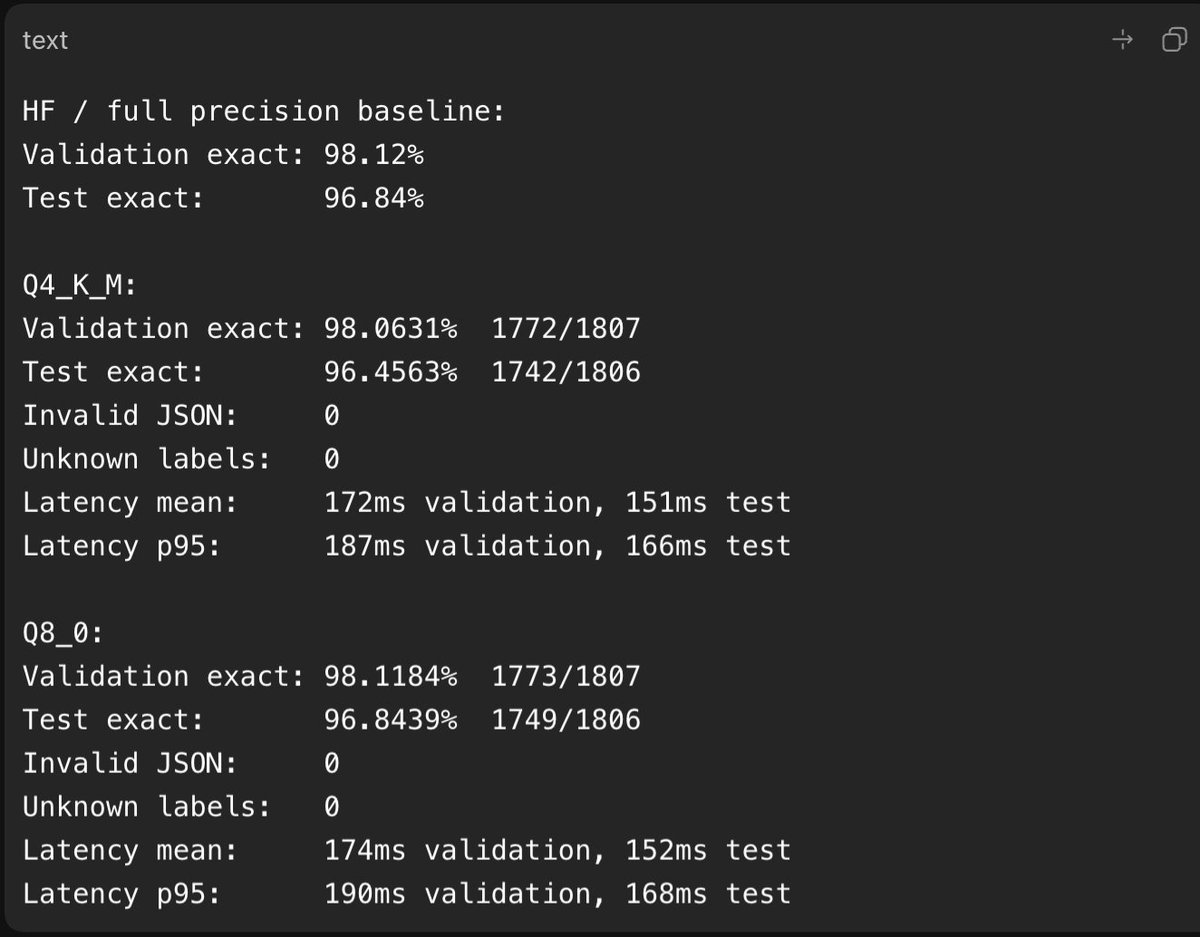
I fine-tuned the model on a 135M dataset generated by Codex 5.5 + DeepSeek v4 Pro.
I achieved 96%+ accurate results with Qwen 3.5 4B.
And 95% on Qwen 3.5 2B (that only requires 3.5GB RAM).
For context, on the same pipeline:
> Sonnet 4.6 achieved 89%
> GPT 5.4 Mini achieved 85%
> Haiku 4.5 achieved 72%
I don't trust evals, so I ran a 7000+ row hard-boundary test, and the results of Qwen 3.5 were consistent.
A 4B fine-tuned model beating a 20x bigger model in accuracy and latency is no joke.
It cost me $173 in total to generate the dataset and cover the cloud GPU cost to fine-tune both models.
I said this before, and I'll say it again: not everything requires a 1T-parameter LLM. We need ELMs (Expert Language Models) that are specialized for one domain only.
ELMs > LLMs.
I'll be writing more about how SLM fine-tuning works. So stay tuned.
If you love fine-tuning open-source models (like me), then listen.
> Start with 1B, 2B, 4B, and 8B models. (Don't start with a 27B model or bigger at first.)
> Use WebGPU providers. I use Google Colab Pro for any model smaller than 9B. A single A100 80GB costs around $0.60/hr, which is cheap. Enough for small models.
> Don’t buy GPUs unless you fine-tune 7 to 10 models. You'll understand the nitty-gritty in the process.
> Use Codex 5.5 × DeepSeek v4 Pro to create datasets. Codex to plan, DeepSeek v4 Pro to generate rows.
> Use Unsloth's instruct models as a base from Hugging Face. Yes, there are others too, but Unsloth also provides fast fine-tuning notebooks.
> Use Unsloth's fine-tuning notebooks as a reference. Paste them into Codex, and Codex will write a custom notebook with the configs you need.
> Spend 1 day learning about:
- SFT (supervised fine-tuning)
- RL training (GRPO, DPO, PPO, etc.)
- LoRA / QLoRA training
- Quantization and types
- Local inference engines (llama.cpp)
- KV cache and prompt cache
> Just get started. Claude, Codex, and ChatGPT can design a step-by-step plan for how you can fine-tune your first AI model.
Future tech is moving toward small 5B to 15B ELMs (Expert Language Models) rather than general 1T LLMs.
So fine-tuning is an important skill that anyone can acquire today.
Tune models, test them, use them. Then fine-tune for companies and make a career out of it. (Companies pay $50k+ to fine-tune models on their data so they can get personalized AI models.)
Shoot your questions below. I'll be sharing in-depth raw findings about this topic in the coming days.
As an AI Infrastructure Engineer.
Please learn:
- GPU/VRAM fundamentals, quantization & batching
- vLLM / TensorRT-LLM / inference optimization
- KV caching, speculative decoding & token throughput
- Distributed training basics (DDP/FSDP/DeepSpeed)
- Model serving & autoscaling
- Vector DB retrieval pipelines
- Prompt caching & cost optimization
- Observability for LLM apps
This is what production AI teams actually care about.
Introducing Swiggy Builders Club
We’re opening @Swiggy commerce infrastructure to developers and enterprises to build on top - build AI agents, apps, and integrations on top of Swiggy’s Food, Instamart, and Dineout ecosystems - with real APIs, real data, and real users.
What you get:
3 MCP Servers (Food, Instamart, Dineout)
18+ API tools covering the full convenience stack
Production data access from day one
Direct engineering support
Who it’s for:
Individual developers with bold ideas
Startups building AI-native commerce products
Enterprises looking to integrate Swiggy into their platforms
Smart grocery restock bots. AI ordering assistants. Dining recommendation agents. Group ordering tools, health first products.
If it makes commerce better for users, we want to see it.
Ship something great and we’ll feature it. Ship something exceptional and our recruiting team might reach out.
Kimi K2.6 raises the bar for open-source models.
🦙 available on Ollama's cloud!
Try it with OpenClaw:
ollama launch openclaw --model kimi-k2.6:cloud
Try it with Hermes Agent:
ollama launch hermes --model kimi-k2.6:cloud
Try it with Claude Code:
ollama launch claude --model kimi-k2.6:cloud
more integrations 🧵
If I had to become an AI engineer in 90 days, I would not start with courses.
I would build projects from these 10 GitHub repos.
1. LangChain
The LLM application framework on almost every AI engineer JD. If you want to build production LLM apps, start here.
repo → https://t.co/alIh6rDDIu
2. LangGraph
Stateful agents as graphs. The repo JDs mean when they say "agentic workflows."
repo → https://t.co/bzVBn9uecV
3. LlamaIndex
The go-to framework for RAG and document agents. Every "retrieval pipeline" JD points here.
repo → https://t.co/m4oJ9FiCrX
4. CrewAI
Multi-agent teams with roles and tasks. Used in production by enterprises across the Fortune 500.
repo → https://t.co/0xohE065sD
5. Qdrant
A production vector database written in Rust. JDs name it alongside Pinecone, Chroma, and FAISS.
repo → https://t.co/ziSSXW2dzZ
6. Ragas
The standard framework for evaluating RAG pipelines. Hallucination, faithfulness, relevancy, all measurable.
repo → https://t.co/vgOInvREU5
7. Ollama
Run open-source LLMs locally in one command. JDs ask for local inference for cost and privacy reasons.
repo → https://t.co/gyZhUdzsnZ
8. Awesome MCP Servers
Model Context Protocol is the newest skill on JDs. This repo indexes every production MCP server out there.
repo → https://t.co/ejVOgkRJDX
9. Awesome LLM Apps
100+ end-to-end templates for RAG, agents, multi-agent teams, voice agents, and MCP. Real working code.
repo → https://t.co/oXrD5A8K6a
10. AI Agents for Beginners
Microsoft's free 12-lesson curriculum covering the full AI agent stack. No paywall, no signup.
repo → https://t.co/7dNsDw6bTj
AI engineer job descriptions in 2026 keep asking for the same things: RAG, agents, vector databases, evals, MCP.
These 10 repos teach all of it.
Pick one. Build one project. Push it to GitHub. That's how you start.
100% free. 100% open source.
If you want to become an AI engineer in 2026 and don't know where to start.
Here's the complete list of free resources you actually need.
1. Stanford CS229- Machine Learning
The course Andrew Ng built before he became Andrew Ng. Full lectures on YouTube. Problem sets on the Stanford site. Audit free on Coursera.
Link: https://t.co/K2kFE3dHQ8
2. Harvard CS50 AI - Intro to AI with Python
The cleanest beginner AI course on the internet. Harvard puts it out for free. No excuses.
Link: https://t.co/LMf6IJeOZp
3. MIT 6.S191 - Deep Learning
MIT's official intro to deep learning. Updated every year. Guest speakers from Google, Microsoft, MIT labs.
Link: https://t.co/N7WsOA7UDZ
4. UC Berkeley - LLM Agents MOOC
Guest lectures from Anthropic, OpenAI, Google DeepMind, and NVIDIA on how agents actually work. The most industry-relevant free course on agents right now.
Link: https://t.co/hLGAcVNd5u
5. Hugging Face LLM Course
Covers transformers, fine-tuning, deployment, and advanced LLM techniques. Built by the team that ships the tools you'll actually use on the job.
Link: https://t.co/apLq1Y652G
6. Hugging Face AI Agents Course
Goes from theory to production. You build with smol-agents, LangGraph, and LlamaIndex. Free certificate included.
Link: https://t.co/8QYPr5l6gM
7. Anthropic Academy – Developer Deep Dive
13 free courses from the team that built Claude. Covers the API, MCP, prompt engineering, and production integration patterns. Launched March 2026. No paywall.
Link: https://t.co/JLRiDIzbPe
8. Anthropic Prompt Engineering Course
9 chapters, hands-on exercises, runs directly in Claude. The only prompt engineering course where you learn from the people who built the model.
Link: https://t.co/ZIiTGzEdo8
9. DeepLearningAI Short Courses
88 free courses. Each one runs 1–2 hours. Built with OpenAI, LangChain, Anthropic, and Mistral. Start with "ChatGPT Prompt Engineering for Developers."
Link: https://t.co/btuHWx2zEo
10. fast AI - Practical Deep Learning for Coders
Jeremy Howard's course. Code-first. No math gatekeeping. The fastest way to go from zero to actually building neural networks.
Link: https://t.co/yWbkhFTbuu
All of it is free.
None of it requires a paid subscription.
If you could only pick ONE of these to start with in 2026, which would it be?
I trained a 12M parameter LLM on my own ML framework using a Rust backend and CUDA kernels for flash attention, AdamW, and more.
Wrote the full transformer architecture, and BPE tokenizer from scratch.
The framework features:
- Custom CUDA kernels (Flash Attention, fused LayerNorm, fused GELU) for 3x increased throughput
- Automatic WebGPU fallback for non-NVIDIA devices
- TypeScript API with Rust compute backend
- One npm install to get started, prebuilt binaries for every platform
Try out the model for yourself: https://t.co/TB2itlmCVT
Built with @_reesechong. Check out the repos and blog if you want to learn more.
Shoutout to @modal for the compute credits allowing me to train on 2 A100 GPUs without going broke
cc @sundeep@GavinSherry
@Alibaba_Qwen Thank you for supporting open-source! We just made GGUFs so you can run the model locally on 23GB RAM / Mac for 4-bit. 💜🥰
Qwen3.6-35-A3B: https://t.co/VlyW8UwDjw
These are actual high-demand next-level AI skills, not RAG:
- Data prep for instruction fine-tuning
- @UnslothAI ecosystem for fine-tuning, reasoning models, quantization, etc.
- Fine-tuning embedding models
- Backend design using FastAPI, Redis caching, queue workers, rate limiting
- Making LLM inference layer using @vllm_project
- @DeepSpeedAI for multi-GPU training
- Learn NVIDIA Triton for running any vision and object detection models along with LLMs
- Learn about Docker and CUDA setup
- Use of @huggingface ecosystem
- Distributed systems using @anyscalecompute
- Kubernetes and Terraform setup for serving your model
- Learn about @modal for low-config setup deployment
- Deploying LLM on Ollama for easier calls
- Context engineering
- Agent memory harness
- Multi-agent orchestration
- LLM as a judge
These skills are more focused towards inference engineering to ensure that your model runs smoothly in production.
Memory, inference, and orchestration matter a lot more than frontier models.
I am learning inference engineering and agent harness nowdays.
Totally worth exploring!
This peanut-sized chinese model just dethroned Gemini at reading documents.
It’s called glm-ocr. it’s a tiny 0.9b parameter vision-language model that is about to replace every expensive ocr api you use.
→ Handles text, tables, formulas, handwriting
→ Scored 94.62 on OmniDocBench V1.5
→ 8 languages
→ vLLM, SGLang, Ollama
And it’s 100% open-source.
Don’t overcomplicate it.
• Build a File Search Tool to learn recursion and indexing
• Build a Markdown to HTML Converter to practice parsing
• Build a Rate Limiter to understand queues and timing
• Build a JSON Database to learn serialization and storage
• Build a Chat Server (CLI) to understand sockets and concurrency
• Build a Static Site Generator to learn templates and file systems
• Build a Git-like Version Tracker to understand diffs and commits
• Build a Task Scheduler to learn cron like logic and timing
• Build a Cache System to understand TTL and eviction strategies
• Build a Load Balancer (simple) to understand routing logic
• Build a Port Scanner to learn networking basics
• Build a Config Manager to learn env files and parsing
• Build a Search Autocomplete using prefix trees (Trie)
• Build a Notes App with tagging to learn indexing
• Build a Simple Queue System to learn producers & consumers
• Build a Backup Tool to learn file copying and versioning
• Build a Feature Flag System to learn toggles and configs
• Build a Simple API Client (like Postman CLI)
• Build a Diff Tool to compare files line-by-line
• Build a Mini Template Engine to learn string processing
Build Projects, Not just tutorials.
My recent 4 articles on X:
- KV Cache in LLMs
- Paged Attention in LLMs
- Causal Masking in Attention
- Byte Pair Encoding in LLMs
X is a knowledge sharing platform.
Working on a RAG system that works locally!
A code migrator
LLMs: Qwen coder, gptoss
Embedding model: qwen-embedding (since code is involved)
VectorDB: FAISS
Any suggestions on how this can be done better?
Better tools, workflows?
#community#llms#rag#qwen#gpt