@Moniica1789 6/ 👉 L’État prélève donc environ 56,3 % du coût employeur sous forme de charges, impôts et TVA.
📉 Le salarié ne dispose que de 43,7 % en pouvoir d’achat réel.
Let's ask #GPT4 (#DALLE) to draw us a chick and then try an experiment: let's only say "Creepier" 10 times.
Results are insane 😱
Here's the amazing result I got =>🧵
1/10
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
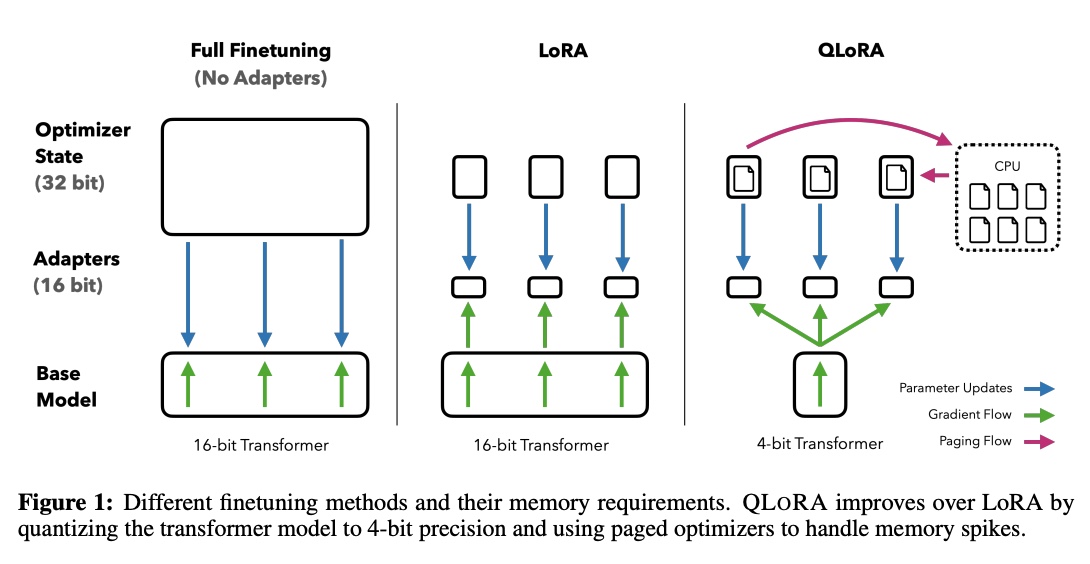
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and fine-tune LLMs on consumers' GPUs.
In a few words:
QLoRA reduces the memory usage of LLM fine-tuning without any performance tradeoffs compared to standard 16-bit model fine-tuning.
This method enables 33B model fine-tuning on a single 24GB GPU and 65B model fine-tuning on a single 46GB GPU. This is incredible! 😍
More specifically, QLoRA uses 4-bit quantization to compress a pre-trained language model. The LM parameters are then frozen, and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters.
During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the original LoRA paper (https://t.co/54Lsb4DBFi). 🤓
QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters, which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference. Beautiful!😱
QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the OpenAssistant dataset (OASST1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning.
Their Guanaco models are reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of fine-tuning on a single GPU. You can actually do it in Google Colab.
📚 Links-
QLoRA Paper - https://t.co/srUrDq4PS6
Colab for inference - https://t.co/iBtmLleCLf
Colab for fine-tuning - https://t.co/8eZQLxKozM
GitHub Repository- https://t.co/Jo50Ltn1Xw
Use it with HuggingFace - https://t.co/TWT0xPfr2g
Kryll is listed in the https://t.co/vCNztATkNg App 🔔
Buy $KRL at true cost with USD, EUR, GBP, and 20+ fiat currencies.
Download the App to start trading #KRL now!
👉 https://t.co/jt6bDD8HsI
For more details - https://t.co/OPgicSVEU4
@kryll_io