We’re hiring research interns at @NVIDIA 🚀
You’ll work on interactive world models and explore how GenAI will shape the next generation gaming experience. Interns are encouraged to publish papers on top-tier conferences(CVPR/Siggraph/ICCV/ICLR,etc).
If you are interested, send your CV to [email protected]
#GenAI #DLSS #DLSS45 #Internships
Introducing DLSS 4.5:
⚫️Second-gen Super Resolution transformer model for all RTX GPUs
⚫️Dynamic Multi Frame Gen for RTX 50 Series GPUs in Spring '26
⚫️6X Multi Frame Gen for RTX 50 Series GPUs in Spring '26
⚫️DLSS Overrides in NVIDIA app
Learn More → https://t.co/LpsMmqDiIU
A new era of computer graphics is emerging through AI, with new speaker Edward Liu joining NVIDIA Research and Engineering leaders Jan Kautz and Ming-Yu Liu.
Join the 'SIGGRAPH 2026 Sponsored Keynote, Next Era of Graphics — Neural Rendering, World Models, and Simulation'
This session will explore the latest advances in neural rendering, world foundation models, and AI-driven simulation through breakthrough research and live demonstrations. https://t.co/J8BynNbUli
Glad to share our PixelDiT work to the community! Many thanks to all coauthors and contributors. This is the first research project I initiate and lead after joining NVIDIA. Thanks for the support from our ADLR team. We will continue pushing the research on pixel diffusion. Check our project page for paper, code, and weights: https://t.co/fzqcJyAPqm
Heading to #CVPR2026! I’m excited to present our work:
I-Scene: 3D Instance Models are Implicit Generalizable Spatial Learners
📍 Denver
🗓 June 6, 4:45–6:45 PM MDT
For years, learning-based interactive 3D scene generation has been shaped and constrained by 3D-FRONT. Methods learn layout distributions from this dataset, making their spatial priors tightly coupled to its limited diversity, and spatial relation statistics.
In I-Scene, we answer a key question:
❓ Where do spatial priors for interactive 3D scene generation come from when data is limited?
Our finding is surprisingly simple: strong 3D instance models already encode rich spatial priors. By reprogramming an instance-level model with scene-context attention and view-centric space, I-Scene can generalize to interactive 3D scenes without relying on heavily annotated scene datasets.
🌟 Key takeaways:
1️⃣ View-centric space matters for spatial relationships
2️⃣ Randomly composed objects can provide surprisingly strong supervision
3️⃣ Strong instance models can serve as a foundation for real-to-sim 3D scene generation
Come by and chat if you’re interested in #GenAI, #SpatialIntelligence, #RealToSim, or #EmbodiedAI!
“Carve nature at its joints.” — after Plato
We built WALL-WM, an event-centric World Action Model.
Fixed chunks cut by clock.
Semantic events cut by embodied dynamics.
Instead of predicting fixed-length action chunks, WALL-WM learns through action-grounded events: reach, grasp, lift, move, place.
The surprising part: this was not just a cleaner formulation. It gave much stronger real-world generalization across language, scenes, and tasks.
Maybe the next token for robots should be an event.
🚀 Want to see how we do real-to-sim from a single input image?
We’re releasing the code for I-Scene #CVPR2026!
✨Highlights:
- Stronger scene generalization trained on randomly composed objects
- Scalable data generation for downstream tasks
- Supports both 3D Gaussian Splatting and mesh outputs
Try the online Hugging Face demo and play with I-Scene yourself!
GitHub: https://t.co/nA8HICjDwz
Demo: https://t.co/vPCUL10VRW
Project: https://t.co/wo9hHFXvEb
Glad to be selected as an Outstanding Reviewer. Appreciate the AC’s recognition.
For reviewers who worked hard but were not selected: please don’t be discouraged. The process can be random. I’ve tried to keep my review quality high for years, and only got selected this year.
Every responsible reviewer is a hero, selected or not. Your effort is not wasted — you are helping the community and making the right choice for science.
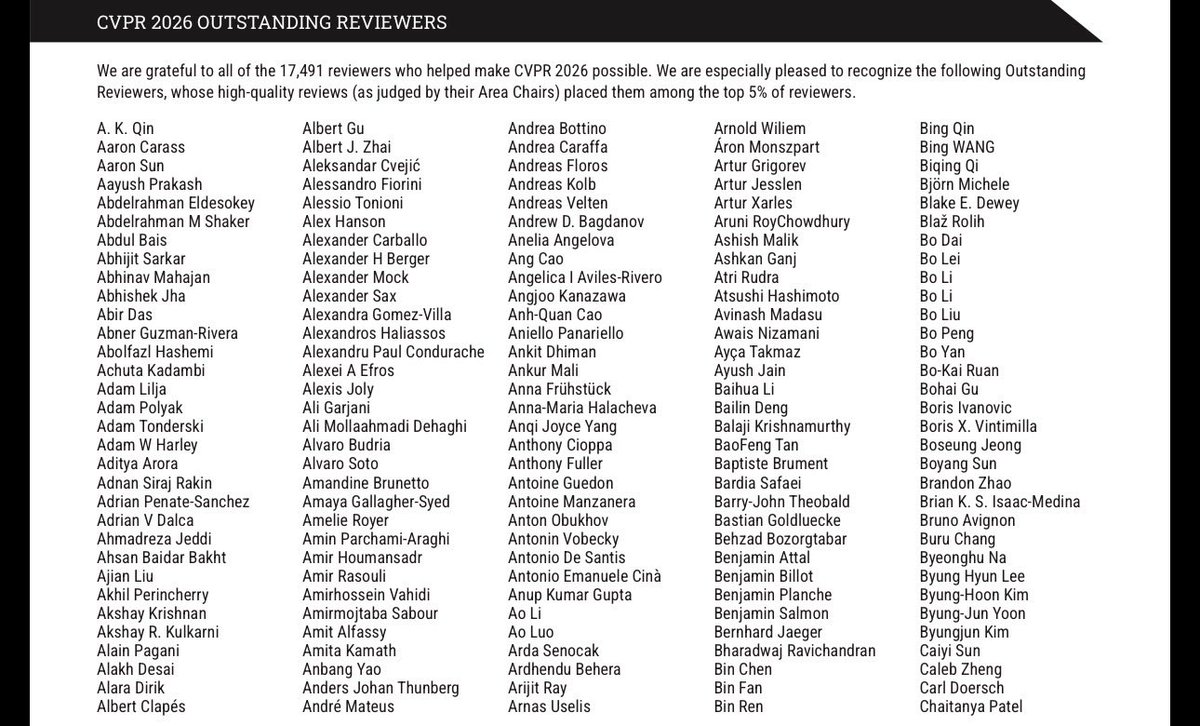
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
Very impressive! We observed a similar finding in I-Scene — directly mapping 2D observations into canonical 3D space makes pixel-to-3D correspondence hard to learn. Coordinate reparameterization really matters! And that is even more important for scene generation.
https://t.co/wo9hHFXvEb
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.
PixelDiT has been accepted to #CVPR2026 as an oral paper.
Here is our code/checkpoint relase: https://t.co/SydgwR8p5N
Paper: https://t.co/HtjBJR08cS
Project: https://t.co/Yd4jGJAZXm
Kudos to Yongsheng and @WeiX1762273!
🚀 Excited to share that our paper, PixelDiT: Pixel Diffusion Transformers for Image Generation, has been accepted to #CVPR2026 as an Oral Presentation. This is a collaboration between NVIDIA and University of Rochester. Today, we release the code and checkpoints of both our class-conditional model and our 1.3B text-to-image (1024x1024 res) model for research purposes. Feel free to use them and leave comments.
PixelDiT is a single-stage, end-to-end diffusion model that eliminates the need for VAEs or any vision encoders and learns the diffusion process directly in pixel space. It works well on both class-conditioned generation and text-to-image generation. Our approach completely avoids the information loss introduced by encoder's compression, which can benefit a wide range of applications, including low-level vision, image editing, etc. Pixel-space diffusion models have advanced rapidly in recent months, and our model remains state-of-the-art among models of comparable scale. We believe this represents a promising new paradigm for training visual generative models.
Notably, in the paper, we specifically incorperate a section "Things We Tried But Did Not Work" (see appendix section G), to share empirical observations and negative results that may be informative for future research on pixel-space diffusion models. We hope this can benefit the community.
Code&Checkpoint: https://t.co/LuKOnwLvid
Latest Paper: https://t.co/CUiDZ7SlPW
Project Page: https://t.co/yJfUHTpkej
📒 Phota 101: Profile Setup covers best practices to help you get the most out of Phota Studio.
Profiles are at the center of Phota.
Built from your personal album, your identity models learn the details of your appearance so edits and generations across different contexts preserve your identity.
Your photos and models are owned by you and are not used for any other model training.
Here's some of the DLSS 5 material we saw in the demos but didn't get a chance to film. Here I think you can see the strengths of DLSS 5 - reflections become much more attractive. Starfield doesn't have great lighting to begin with, so the differences can be profound.
@CVPR What does accept and suggest to finding mean? It means accept only to finding workshop or accept to main conference and also get suggested to finding workshop?
Computerbase did a blind video image quality test with thousands of votes and several games, and found a strong preference for DLSS 4.5 image quality at 2X upscaling over Native full resolution rendering.
When we launched the Turing GPU generation, we knew the day would come when Neural Rendering even at a low resolution would be more detailed and better looking than traditional methods, while also being significantly faster.
And we are just getting started!
https://t.co/45a0n7AuOV