📊 Strategic insights at the core of tech | Cloud, AI, Data | Curated for professionals, founders & digital leaders | #TechIntelligence @CoreTechInsight
5:**
🌐 **Top Cloud Providers**:
- 🚀 AWS – Market leader
- 🧩 Azure – Microsoft integration
- 🔍 GCP – Strong in data & AI
- ☁️ IBM, Oracle – Enterprise focus
Each has strengths. Multi-cloud is rising.
#AWS#Azure#GCP#CloudPlatforms#CloudStrategy
5
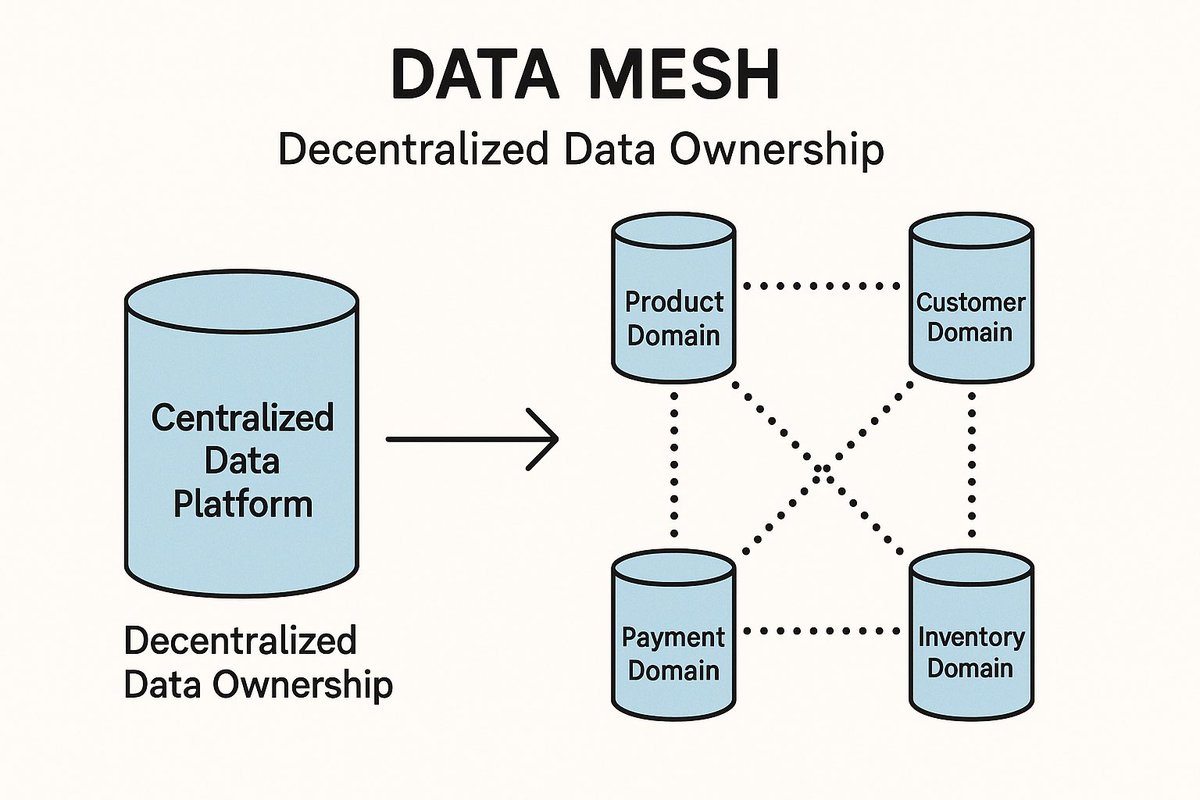
Think of Data Mesh as treating data like APIs.
Each domain provides clean, well-documented, and discoverable data to others — like products.
Decentralized doesn’t mean chaos — it means ownership with standards.
#DataStrategy#DataDriven#NextGenDataPlatform
4
Why adopt Data Mesh?
✔️ Avoid bottlenecks from central data teams
✔️ Enable faster insights
✔️ Improve data quality and accountability
✔️ Scale with organization growth
#DataDemocratization#DecentralizedData#AgileData
5: Enterprise Ready
PySpark is trusted by top enterprises for high-volume data workloads in production.
It’s scalable, fault-tolerant, and battle-tested for modern data platforms.
#EnterpriseAI#CloudDataEngineering#PySparkAtScale
4: Seamless Integration
Use familiar Python libraries (Pandas, NumPy, scikit-learn) with Spark’s scalability. Connect to HDFS, Hive, Cassandra, AWS S3, and more.
#PythonDataScience#CloudAnalytics#DataOps