Integration by parts turns products of functions into simpler integrals.
If u(x) and v(x) are continuously differentiable, then ∫u dv = uv − ∫v du.
Use the ILATE rule to pick u: Inverse, Logarithmic, Algebraic, Trigonometric, Exponential.
Example: ∫(log x)⋅1 dx = x log x − x + C.
Engineers rely on it to compute work from variable forces in physics and to solve signals in electrical and mechanical systems.
#LaTeX es una poderosa herramienta para poder escribir #matemáticas de forma impecable. Este manual (2ª ed.) está especialmente dirigido al alumnado, profesorado o investigadores que deseen iniciarse y adquirir soltura en su manejo https://t.co/CUWhQxwQUQ
@PublicacionesUA
He estado explorando la integración de IA con el lenguaje de análisis de datos R 📊⚙️
Producto de eso he subido varios tutoriales para incluir IA en procesamiento de datos, hacer que la IA acceda a datos con R, crear chatbots especializados, y más! 🤖
👉🏼 https://t.co/62tDG12LCs
Con R es muy fácil crear sistemas de IA que respondan informados por documentos, estudios y textos! No más respuestas ambiguas ni "alucinaciones" gracias al RAG ⚙️📝
Tutorial: https://t.co/pYFPqesCu6
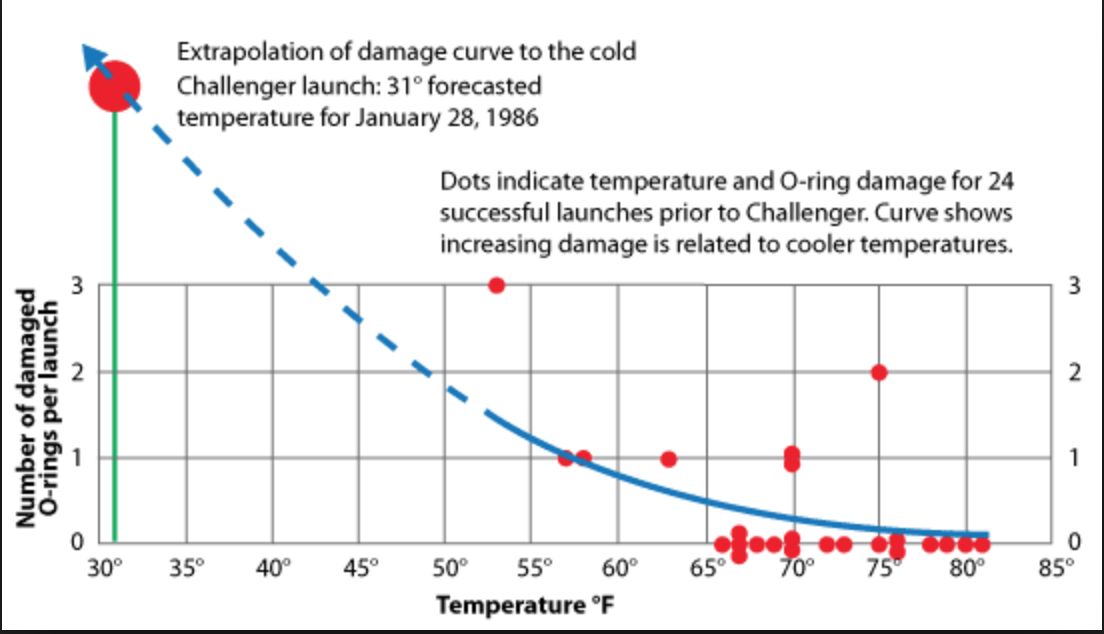
📊El error gráfico que costó 7 vidas y una lección sobre el "Sesgo de Selección"
¿Sabías que el desastre del transbordador espacial Challenger en 1986 no ocurrió por falta de datos, sino por un error catastrófico al elegir cuáles datos mostrar?
Lecciones para tu próximo gráfico👇
What if I told you a neural network understands local change before it understands the full picture?
That idea is deeply connected to something called the Jacobian Matrix.
At first, it looks terrifying. A big matrix full of partial derivatives. But the intuition behind it is actually beautiful.
The Jacobian measures how small changes in input variables affect the output of a system.
Imagine slightly changing the pixels of an image.
Or changing one feature in a dataset.
How much does the prediction change?
The Jacobian tells us exactly that.
You can think of it as a “sensitivity map” for transformations.
If a system transforms one space into another, the Jacobian describes how the geometry changes locally.
Tiny squares can stretch, rotate, compress, or skew into completely different shapes.
That is why Jacobians are everywhere in AI & machine learning.
For example:
- Backpropagation relies heavily on Jacobians through the chain rule
- Neural networks use them to understand gradient flow
- Normalizing Flows use Jacobian determinants for probability density transformations
- Computer Vision uses them in geometric warping and image alignment
- Robotics uses Jacobians for motion and control systems
- Diffusion models and generative models often depend on transformations between latent spaces
The interesting part is this:
Most ML models are basically learning transformations.
And the Jacobian is what tells us how those transformations behave locally.
Step-by-step intuition:
- Start with an input vector
- Apply a transformation
- Measure how each output changes with respect to each input
- Store those local relationships inside a matrix That matrix becomes the Jacobian.
Carl Gustav Jacob Jacobi introduced this mathematical idea long before AI existed.
But today, modern deep learning silently runs on top of concepts like this every second.
Sometimes the most important parts of AI are not the flashy models.
They are the mathematical structures underneath them.
Sigo sin entender, cómo tan poca gente usa herramientas de IA.
La mayoría solo conoce ChatGPT y Claude❌
Aquí tienes 11 JOYAS OCULTAS que necesitas conocer AHORA.
Guárdalo ahora o te arrepentirás👇
The television show The Simpsons, in the “Treehouse of Horror” episode from the sixth season, revealed the following counterexample to Fermat’s Last Theorem:
1782¹² + 1841¹² = 1922¹²
We leave it as an exercise for you to make peace between this example and Andrew Wiles’s celebrated proof.
Source: Mathematical Apocrypha