Excited to share that "TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space" got accepted to SIGGRAPH 2025!
It tackles disentangling complex visual concepts from as little as a single image and re-composing concepts across multiple images into a coherent result.
https://t.co/MMr8Ssv9cx
#SIGGRAPH2025
Even today, with powerful image editing models, making fine-grained structural changes to 3D shapes remains a major challenge.
In our new #SIGGRAPH2026 paper, Prox-E, we use primitive-based abstraction to leverage VLMs for precise, reasoning-based 3D editing!
👇
Excited to share our work accepted to #SIGGRAPH2026 ! Video generation models struggle with something few talk about: their transformations don't evolve smoothly. You get long boring stretches... then a sudden semantic jump where everything "catches up" at once.
1/7
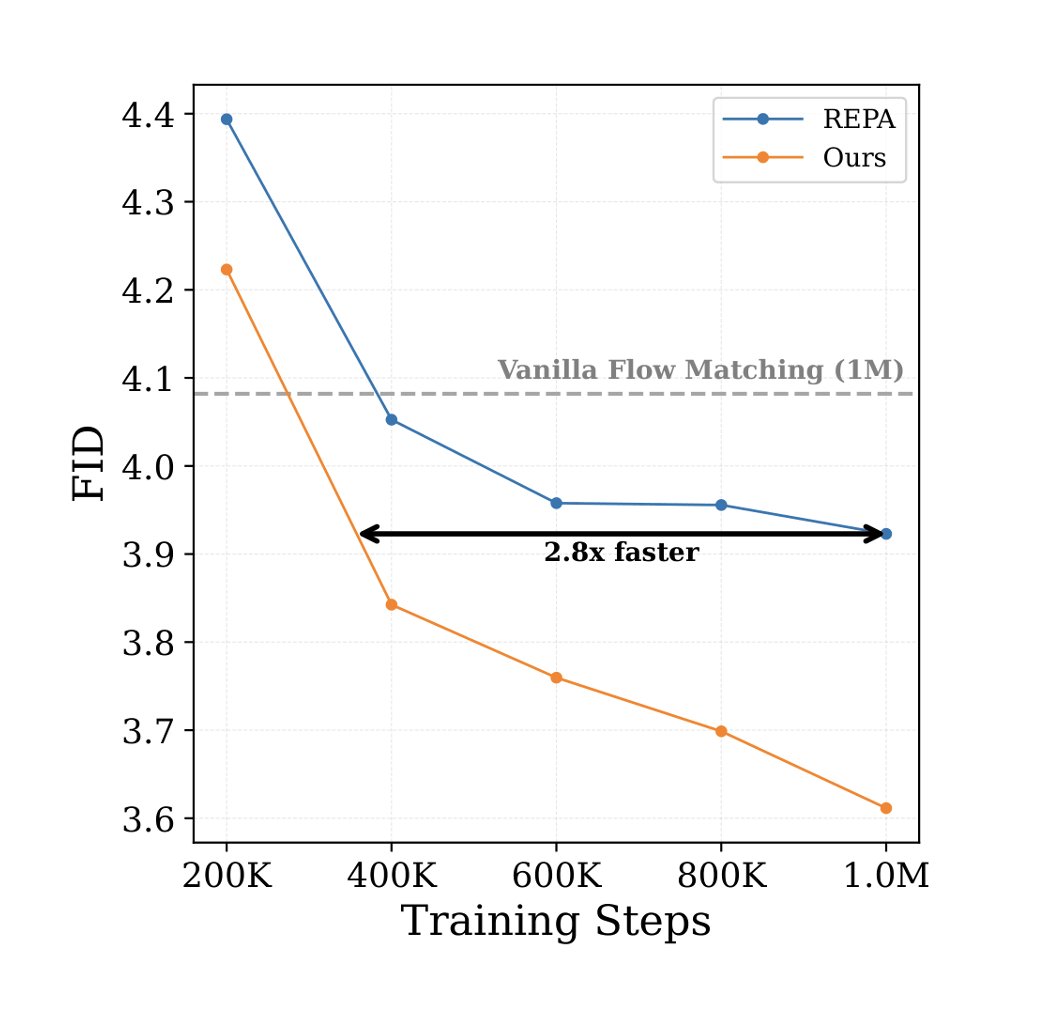
When rewards conflict, what should RL post-training of diffusion models optimize?
In visual generation, objectives are often in tension:
Prompt adherence can conflict with source preservation.
Photorealism can conflict with stylization.
In our new paper, ParetoSlider, we introduce a multi-objective RL framework that trains a single diffusion model for continuous control over competing reward objectives 🧵
Do you like image editing? Don't like prompt engineering? Want to see what a giraffe-duck hybrid looks like?
If you answered yes at least once, you may like our new #SIGGRAPH2026 paper: LooseRoPE, which presents a new, prompt-free way to edit images using simple visual cues 👇
3D editing has long relied on workarounds: per-asset optimization, 2D view propagation, or hacking frozen priors. The bitter lesson is the same one image editing already learned. Train a native model, end-to-end.
Introducing ShapeUP, accepted to SIGGRAPH 2026 💫
[1/5] Is Text Enough for Control? 🐇
Text-driven video editing lets you describe *what* to change. But what about *how much*?
We introduce Adaptive-Origin Guidance (AdaOr).
A joint work with @DecartAI and @TelAvivUni 🧪
accepted to #SIGGRAPH2026.
Many styles are not just textures or colors — they reshape geometry.
Abstraction in Style (AiS) introduces an abstraction stage before stylization, enabling extreme abstraction-driven styles previously out of reach.
https://t.co/DnPpdcodGc
Modern T2I DiTs are incredibly powerful, but have a serious diversity problem.
We introduce a surprisingly simple and efficient inference-time fix
(+2s for Flux-dev, +1s for SD3.5-Turbo).
Excited to share our SIGGRAPH 2026 (conditional) paper:
“On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers”
DLSS 5 is all over the timeline, and for good reason. In my internship at @AIatMeta we had the same idea: use a video model as a learned second-stage renderer on top of game engines. In our paper RealMaster, we make synthetic video look real while preserving scene fidelity 👇
Check out DynaEdit - our new training free video editing method from @GoogleDeepMind .
It allows enough flexibility for the edit to induce dynamic changes without deviating from the original video.
Some cool examples in the video and on our website https://t.co/nBlS1gT7L5
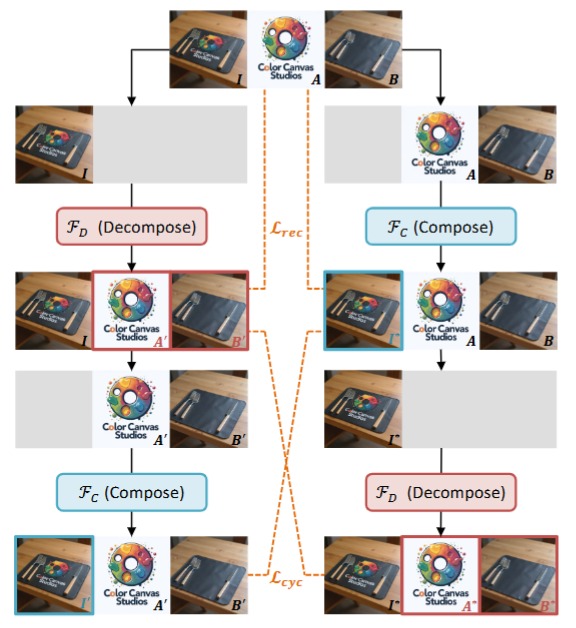
Cycle consistency is a powerful and cool idea.
Here we use it to learn image decomposition: decompose an image into components, recombine them, and enforce consistency both ways.
A cool training principle with surprisingly strong results.
New research from @bfl_ml 🥳
Meet Self-Flow: our self-supervised framework for image, audio, video & world models 🤖
https://t.co/AshY8IkSEe
Do generative models really need DINO to learn strong representations? We propose teaching them directly via a joint framework instead 🧵
SemanticMoments - Semantic motion similarity
How do you find videos with similar motion?
It’s harder than it sounds.
Models like VideoMAE and V-JEPA encode motion, but their embeddings are dominated by appearance.
So how do we build a compact embedding for motion similarity?
Joint work with @kfir99@OPatashnik@BenaimSagie@MokadyRon
Imagine you see a cool visual effect, and want to apply that visual effect to your own video - all while preserving motion and context? You can even edit the strength of the effect as well as the input video preservation! More coming soon... 😶🌫️😶🌫️ #VideoEditing#AI
The GenAI LoRA ecosystem is a dense jungle. 🌿
Introducing CARLoS 🕵️♂️ - a system that retrieves LoRAs by how they alter diffusion behavior, and links these metrics to key concepts in copyright law. ⚖️
🔗 https://t.co/eKBjI8Y1GZ
📄 https://t.co/VEhqFOm0hF
🧵[1/6]
[1/4] Sync about it… 💭✨
Editing a portrait video yet keeping it fully synced with the original across the entire sequence.
Read more about Sync-LoRA: https://t.co/4sAnR8FcZ1 🚀
Hey @iclr_conf, reverting scores is unnecessary punishment for the majority of the authors who had nothing to do with this incident and had successful rebuttals. Instead of detecting collusions on your end (you have a ton of metadata) why is this everyone’s burden to bear?
Introducing Canvas-to-Image (C2I): A new paradigm where you define all controls within a single RGB canvas. 🎨
We simplify complex generation into one intuitive interface. Place specific Identities, Poses, and Boxes to control exactly who appears, how they pose, and where they stand.
C2I interprets your design and generates your vision faithfully. You are the designer.
Generating an image from 1,000 words.
Very excited to release Fibo 😃, the first ever open-source model trained exclusively on long, structured captions.
Fibo sets a new standard for controllability and disentanglement in image generation
[1/6] 🧵
Visual Diffusion Models are Geometric Solvers
We cast geometry as images: a plain diffusion model denoises into valid solutions. It is simple, general and effective.
Shown on Inscribed Square, Steiner Tree, and Maximum Area Polygonization - all classic hard problems.

























![shaharsarfaty's tweet photo. The GenAI LoRA ecosystem is a dense jungle. 🌿
Introducing CARLoS 🕵️♂️ - a system that retrieves LoRAs by how they alter diffusion behavior, and links these metrics to key concepts in copyright law. ⚖️
🔗 https://t.co/eKBjI8Y1GZ
📄 https://t.co/VEhqFOm0hF
🧵[1/6] https://t.co/EznopXUbaM](https://pbs.twimg.com/media/G8dJZ_XWQAA81Lj.jpg)
![MokadyRon's tweet photo. Generating an image from 1,000 words.
Very excited to release Fibo 😃, the first ever open-source model trained exclusively on long, structured captions.
Fibo sets a new standard for controllability and disentanglement in image generation
[1/6] 🧵](https://pbs.twimg.com/media/G4cM-ovWYAAvL05.jpg)































