Catch @DarrylBarnhart speak @NVIDIAGTC today about our exciting work @LatentSpaceAI on scaling LLM with retrieval! 📚
There’ll be an open QA in 30 mins: https://t.co/C42yjpjEi1
@wightmanr Reminds me a lot of the equalized learning rate ideas from Tero Kerras et al in the StyleGan lineage. Also by using std norm init, the variance scaling in optimizers like ADAM is better defined. The grad has the same expected var as the weights (one).
Excited to share our @nvidiaai work on reconstructing high-quality 3D models from monocular photographs and making StyleGAN a controllable neural renderer.
@ChenWenzheng@HuanLing6@JunGao33210520 Yinan Zhang, Antonio Torralba @FidlerSanja
paper: https://t.co/EkcppBDzyT
Check out Performer, a generalized attention framework based on the Transformer architecture, which implements the novel FAVOR+ algorithm to provide linearly scalable, low-variance and unbiased estimation of attention mechanisms. Read more at https://t.co/lLzhXJRIbh
@SebAaltonen I'd be curious to trade notes on this, as I implemented something very similar about a year ago. Rust + vulkan using atlased mipmaps. I also had a raster pipeline to generate SDF tiles for real time streaming of analytic surfaces.
Purposefully overfit neural networks are an efficient surface representation for solid 3D shapes
In https://t.co/m4heg8orD7 with Thomas Davies, @DerekRenderling, we make a few observations:
v1.6: native mixed-precision support from NVIDIA (~2x perf improvement), distributed perf improvements, new profiling tool for memory consumption, Microsoft commits to developing and maintaining Windows PyTorch.
Release Notes: https://t.co/7LMXQYlaAd
Blog:https://t.co/0cwKG82iOB
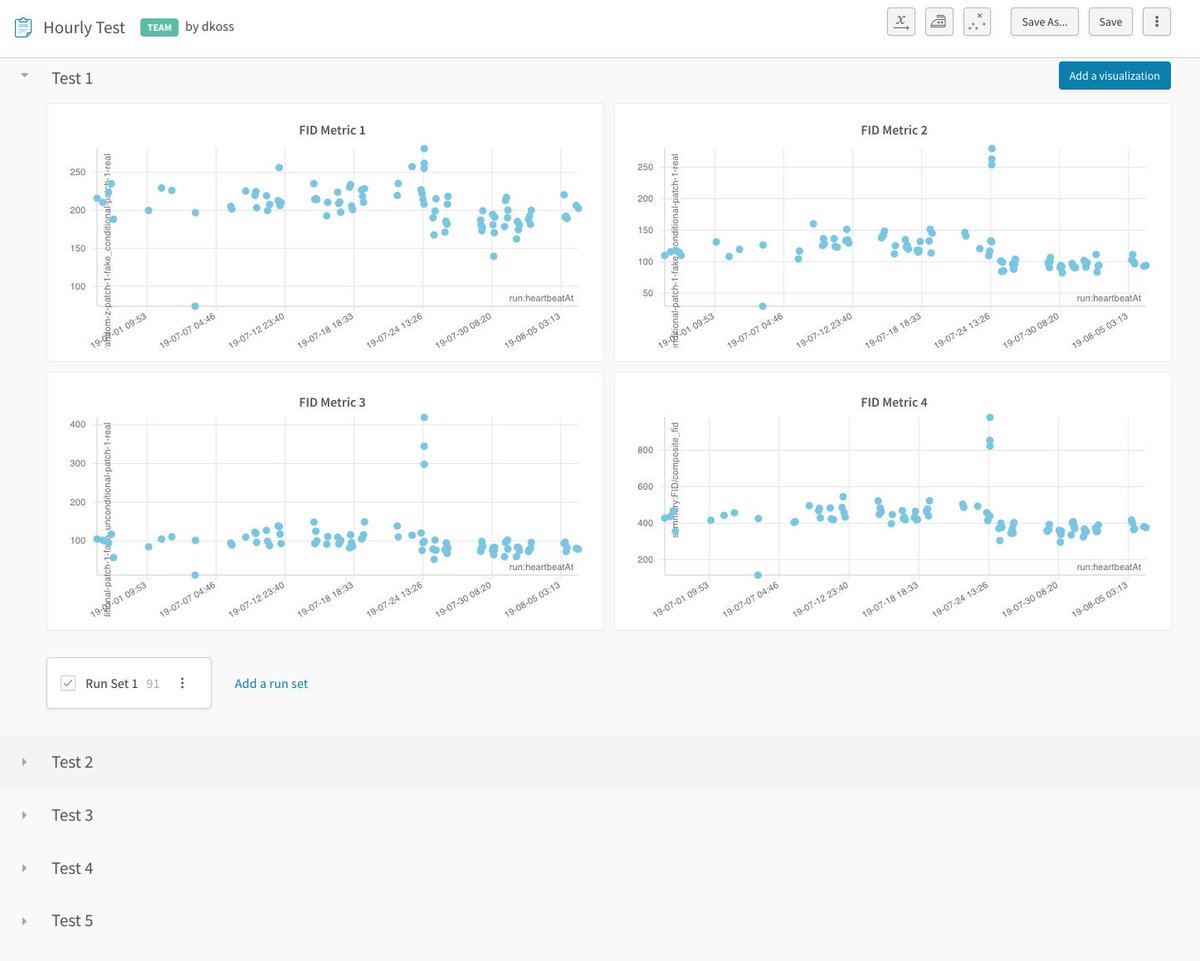
See how ML teams, like @LatentSpaceAI, working on cutting edge deep learning research use W&B Reports to collaborate remotely, debug models iteratively and to showcase results as mini research papers.
#machinelearning#deeplearning#100daysofmlcode
https://t.co/OkAbp5MEwz
@ProgrammerLin I've done something similar but with sparse textures and lods as well. Let's you do 65k render distance with similar performance numbers. But pretty complicated to implement! Your materials are way nicer too.
@wightmanr We're using your repo to do finetuning with some of these models. Noticed that using the Adam optimizer instead of SGD+Momentum (default) yields a much higher test accuracy on our datasets (e.g. 95% vs 89%). Is this expected?
We're at #NeurIPS2019 — Come chat with us about scaling generative models for real-time, applied ML use cases (hint: a game! 👾👾👾)
Reach out to @latentcodes and @iantbd who will be onsite!
After 7 years, Manifold Garden has finally launched! It is available now on @AppleArcade & @EpicGames.
Trailer: https://t.co/b5kzDk2aGO
Apple Arcade (iOS, tvOS, macOS) - https://t.co/SsQmNMTmfV
Epic Games Store (Windows) - https://t.co/J324hWiQSV
Thank you for your support.
Our #siggraphasia paper "Non-linear sphere tracing for rendering deformed signed distance fields" is online now!
Sphere trace deformed SDFs without inverting your deformation function!
https://t.co/yF7V9lmg2C
@wkjarosz@_AlecJacobson@DerekRenderling