DatFlash tracks dataset transactions across the AI data economy; licenses, acquisitions, releases, and benchmarks; creating a normalized record of global data.
For years, organizations have treated data quality as the primary challenge. But what if the bigger problem isn't the quality of individual datasets—it's the inability of systems to work together?
As AI adoption accelerates, more data is being collected than ever before. Yet much of it remains trapped in silos, disconnected from the broader context needed to create meaningful outcomes.
This article explores a different perspective: interoperability may be more important than perfection. When data can be connected, evaluated, and recombined across systems, organizations unlock value that isolated datasets can never provide.
Read more:
https://t.co/wCBxSxnm3D
Most organizations assume their AI bottleneck is compute, so they buy more GPUs, expand storage, collect more data, and scale infrastructure.
But what if the real problem starts much earlier?
A surprising amount of AI and enterprise compute is consumed by unclear objectives, weak evidence, incompatible data, and projects that were never properly defined in the first place.
This article explores a different approach: increasing effective capacity by reducing waste before it enters the system. Define the outcome first, admit only the evidence that matters, and stop unnecessary complexity from consuming resources downstream.
If you're involved in AI, data strategy, interoperability, governance, or digital transformation, this perspective may challenge some common assumptions about what actually limits performance.
Read the full article at https://t.co/XrAZJwWU06
#datacapactiy #datacenters #dataprocessing
Feel you, but its just a tool.. similarly when Adobe Suite came out.. artists around the world panicked, but then adapted. Decades later a new tool emerges, AI, artists and designers panic..but you'll look back on this in 10 years and realize it was the start of a new era, not the end.
Early conversations about the AI data economy treated data like a single interchangeable asset class. Collect it, upload it, sell it. But digital economies rarely mature that way.
Books, music, software, movies, games, news, and social platforms all developed different monetization structures because they behaved differently economically. Data will likely follow the same pattern.
Reach the full article, now live on DataUniversa
https://t.co/pqfGDuPtYw
Every major technological breakthrough follows the same pattern: a new layer emerges that reduces friction, standardizes complexity, and allows entirely new systems to scale on top of it.
This article explores why AI may be approaching that same transition point, not through larger models alone, but through the creation of interoperable, governed, machine-usable data layers that make reliable execution possible at scale.
From transportation networks to cloud infrastructure to modern APIs, transformative systems rarely win because they are “smarter.” They win because they make coordination easier, reduce waste, and allow other systems to build on top of them. AI and data infrastructure may now be entering that same phase.
https://t.co/yhx2wieOdK
The AI data licensing market is rapidly becoming more structured.
What started as a handful of large AI training deals is evolving into an entirely new economic layer around live information access, attribution, and machine-to-machine payments.
Three major shifts are emerging:
• AI companies are moving toward pay-per-use and micropayment models instead of flat licensing agreements
• Big Tech firms are building large publisher syndication networks to formalize AI training and retrieval pipelines
• Publishers and creators are beginning to organize collectively to demand standardized compensation and transparency
The broader shift is important:
AI systems no longer just “scrape the internet.”
They increasingly rely on structured, commercially licensed, continuously refreshed information supply chains.
This may become one of the defining infrastructure markets of the AI era.
Full article below:
https://t.co/eSyyimckWL
#dataeconomy #datalicensing #consumptionratepay
Every major technological breakthrough removes a constraint and reshapes what humans are capable of producing.
From fire and agriculture to software, the internet, and AI, each era has increased leverage while reducing the number of people required to create large-scale impact. But AI has exposed a new limitation: fragmented, incompatible data systems.
This article explores why the next major shift is not just more intelligence or more compute, but interoperability; the ability for data to move, combine, validate, and participate across systems. The result is not simply greater efficiency, but a structural change in who can create value in the AI economy.
https://t.co/ebZTzDSXAe
How is global south data collected? Why is it so scarce in the global AI economy?
What it actually takes to build a global ground truth data collection team, by DataUniversa Founder, John F. Groom
https://t.co/7XmIHpaeHi
#dataeconomy#globalsouth#datacollection
Most enterprise AI systems were not built on governed, interoperable data environments. They were trained years ago across fragmented datasets, inconsistent schemas, unclear lineage, and operational workflows that were never designed for long-term scalability.
That is becoming one of the largest hidden constraints on effective AI capacity.
A significant amount of enterprise compute and engineering effort is now spent compensating for legacy data environments surrounding these models: repeated reconciliation work, duplicated transformation pipelines, unverifiable outputs, broken lineage tracking, and manual correction workflows. In many cases, the issue is no longer the model itself. It is the operational environment the model still depends on.
This is also why the problem cannot be solved through “data cleaning” alone.
Cleaning data improves the condition of individual datasets. But many legacy enterprise AI environments are already operating on technically clean datasets while still suffering from operational fragmentation between systems. The largest capacity losses often occur after the data has already been cleaned — through incompatible schemas, repeated transformations, invalid recombinations, manual downstream validation, and unresolved lineage or permissions issues across environments.
This is where DataUniversa approaches governance differently.
While modern governance frameworks often focus on governance at ingestion for newly collected data, DU can also govern the operational layer surrounding legacy AI systems already in production.
By enforcing interoperable inputs, validating admissibility before execution, aligning metadata structures, validating provenance and permissions, and reducing invalid or redundant computations, DU helps stabilize environments that were historically ungoverned.
The result is not simply better compliance or cleaner datasets. It is increased usable capacity from infrastructure enterprises already have deployed. Less operational waste, fewer correction cycles, improved reproducibility, and more trustworthy outputs all contribute to a more efficient AI environment without requiring immediate full-model replacement.
The next major increase in enterprise AI capacity may not come solely from larger models or more compute. It may come from governing the fragmented legacy environments those models still operate within.
#dataeconomy #datagovernance #legacyAI #Datauniversa
Great point! On behalf of our parent company DataUniversa, we believe this sort of governance begins at the point of ingestion. Structured ingestion eliminates the resource waste down the pipeline, and of course, avoids fines and auditing.
We wonder if companies are ready to take that leap and govern their data up front!
AI organizations are not actually limited by capital. They are limited by waste.
Not just compute waste, but engineering waste, reconciliation waste, validation waste, and endless time spent figuring out what data is actually usable.
A massive amount of AI infrastructure today is consumed by:
• repeated transformations
• schema mismatches
• invalid queries
• duplicate processing
• audit/reconciliation loops
• datasets that technically “exist” but still cannot be trusted or operationalized
The uncomfortable reality is that many organizations are scaling data centers and hiring more engineers to compensate for broken data environments.
But what if a meaningful portion of that capacity could be recovered instead, OR not lost at all?
Our latest article explores how interoperability and admissibility at the data layer can dramatically increase effective compute and engineering throughput, without adding infrastructure or headcount.
The future AI bottleneck may not be compute itself. It may be the inability to operationalize data efficiently.
Read the full article from DataUniversa at https://t.co/Fwer12kZKs
#datacapacity #dataeconomy
This is wild -- we used to work as a direct competitor to matterport. The leg up we had was a better, more robust tagging system. That is what this current system is lacking. I imagine though, as it is open source, it can be modeled to accommodate. This is a big breakthrough tech.
@bevbo1@adiix_official what robots are you speaking of -- you would literally be the human taking the capture yourself. Realtors spend thousands on matterport walkthroughs, that can so easily be replaced with just your own phone.
Most people think interoperability means systems can connect. APIs talk, databases link, pipelines run—and on paper, everything “works.” But connection isn’t the same as interoperability.
True interoperability shows up at the output. It’s not about whether data can be brought together—it’s about whether it can be used together immediately, without transformation, interpretation, or risk.
In most environments, combining datasets introduces friction instead of removing it. Structure doesn’t align, definitions drift, units vary, and context is incomplete. Even when data technically connects, teams still have to step in—cleaning, mapping, and reconciling before anything becomes usable. That extra layer is so common it’s often treated as normal. It shouldn’t be.
Interoperability, properly defined, exists only when that layer disappears—when datasets can be directly combined, compared, and reused across systems without additional handling. The output works on the first pass. This distinction has a broader impact than it might seem.
When interoperability is missing, systems consume capacity just to maintain themselves. Engineering time goes into fixing inconsistencies instead of building new capabilities. Compute is spent reprocessing and validating data that should have already been usable. Decisions are delayed because outputs can’t be trusted without further work.
When interoperability is present, that waste is removed. Processes that used to require multiple steps collapse into one. Data moves directly into analysis, AI models, or decision systems without needing translation layers. The same infrastructure and teams can produce more outcomes, not because they’ve expanded, but because less effort is lost.
This is what increasing effective capacity actually looks like. Not scaling resources, but reducing friction.
#dataeconomy #databottlenecks #effectivecapacity
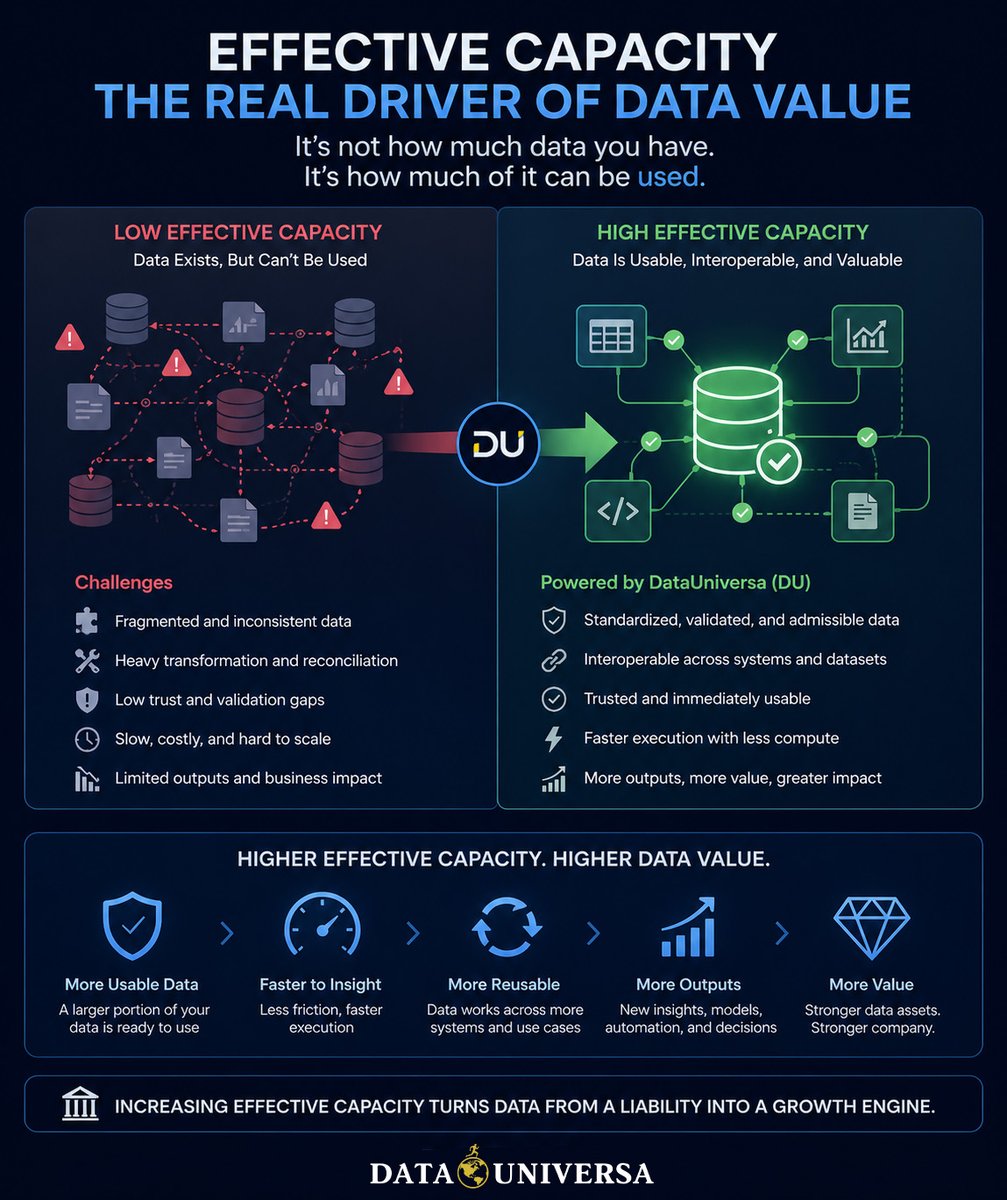
Data value is not driven by volume. It’s driven by usability.
The percentage of your data that can actually be used, your effective capacity, is what determines output, scalability, and ultimately valuation.
Most organizations are operating far below it. Large portions of their data exist, but can’t be reliably combined, executed, or reused without significant effort.
That gap is where value is lost.
Increase effective capacity, and you don’t just improve efficiency, you expand what your data is capable of doing, how often it can be used, and how much value it can generate.
Here’s why that matters: https://t.co/6wJlqku2YU
#dataeconomy #effectivecapacity #ML #Datflash
A lot of the capacity that already exists never turns into usable output. Data has to be located, verified, cleaned, and reshaped before it can even be used.
The same transformations get repeated across pipelines. Workflows run on data that ends up being incomplete or unusable, so they have to be reworked.
None of this is particularly visible, but it adds up.
You end up with a system where total capacity looks high on paper, but effective capacity is much lower in reality. Engineers spend time reconciling data instead of building, and compute gets consumed by work that doesn’t move anything forward.
Across different environments, the pattern is pretty consistent. The more fragmented the data, the more time is spent trying to make it usable, and the more compute gets burned along the way.
What’s interesting is that when you start removing that inefficiency at the data layer, the impact isn’t small. In many cases, a meaningful portion of capacity comes back just by eliminating repeated transformations, constraining execution to valid data, and structuring things so they can actually be reused.
It changes the system from something that is constantly compensating for its own data issues into something that can operate more directly.
At that point, adding more compute becomes a lot less urgent, because the real issue wasn’t how much capacity you had, it was how much of it you were actually able to use.
#dataeconomy #computepower
There’s a lot of focus on model performance and compute scaling.
Less attention is given to how much compute is being wasted before models ever run.
Most data pipelines are still inefficient. Data is duplicated, poorly structured, difficult to connect, and often processed multiple times just to make it usable.
The result is quiet but significant waste:
more compute, higher costs, and slower iteration cycles.
This isn’t just an engineering problem.
It’s a data problem.
If pipelines aren’t built on structured, interoperable data, inefficiency becomes the default.
A more efficient system doesn’t start with more compute, it starts with better data foundations.
That’s the shift that needs to happen, and DataUniversa plans to lead the way.
#dataeconomy #inferencecost #computewaste #datapipeline
https://t.co/CJiYR8XxLT
What does data actually cost?
Right now, there isn’t a clear answer.
Similar datasets can be sold for a few thousand dollars, or several million. Pricing is highly dispersed, terms vary, and most transactions happen without shared context. The market exists, but it’s difficult to observe in a structured way.
Because of that, most decisions around data are still made in isolation.
At the same time, there’s a push toward building a more standardized, reliable, and interoperable data economy. But those systems depend on something more basic: understanding where we are today.
That starts with visibility.
Before data can be structured, governed, or consistently valued, it needs to be more clearly observed.
#Datavalue #dataeconomy #dataasset
Data has been treated like an input for years.
Collected → used → forgotten.
But that’s changing.
Datasets are bought, sold, licensed, and reused.
They behave like assets.
What’s missing isn’t value.
It’s visibility.
There’s little shared context around:
comparable datasets
real pricing
how data is actually exchanged
So decisions happen in isolation.
In every other market, assets are understood through visibility.
Data hasn’t had that layer.
That’s starting to change.
As visibility improves, data becomes something that can be compared, evaluated, and understood more consistently.
That’s the shift.
Read more at https://t.co/GzBspFff9I
#dataeconomy #dataasset #Data #datagovernance