Introducing LobeHub: Agent teammates that grow with you.
LobeHub is the ultimate space for work and life: to find, build, and collaborate with agent teammates that grow with you.
We’re building the world’s first and largest human–agent co-evolving network.
Two years ago, we built LobeChat, an open-source interface for using different AI models.
Today, LobeChat has 70k+ GitHub stars and serves 6M+ users worldwide.
How to fully unlock the power of models has always been a shared mission between us and the community.
We started with interaction — a fundamentally new, agent-first experience.
Agents are no longer passive tools invoked in a single conversation.
They should be proactive, always-on units of work.
Treating agents as the minimal atomic unit is also the core of our agent harness infra.
Today’s agents are mostly one-off executors. Even with memory, it’s often global — and hallucinates.
We build long-term agent teammates that evolve with users.
Each agent has its own dedicated memory space, editable by users, allowing humans and agents to co-evolve over time.
This, in turn, allows us to design clearer rewards for reinforcement learning and create cleaner environments for continual learning.
Agent teammates can work in groups.
Through a multi-agent system, agent groups operate faster, more cost-effective, and go beyond what single-agent systems can achieve.
For example, a single agent often requires heavy user involvement to proceed step by step, whereas LobeHub can execute the same work from a single instruction, with a supervisor orchestrating agents that run in parallel or debate to produce better results.
We are building the collaboration network among agent teammates — and between humans and agent teammates as well.
Ease of use matters. AI intelligence and shared human intelligence are equally important.
With simple instructions and tool selection, you can effortlessly build and team up with agent coworkers to deliver complex, systematic work — even assembling a quant team to execute trades.
Through the LobeHub community, anyone can discover, reuse, and remix agents and agent groups, customizing them to fit their own workflows, preferences, and needs.
Last but not least, our vision started with LobeChat: multi-model support is the most efficient approach for users.
We believe different models excel in different scenarios. By routing across multiple models, LobeHub improves cost efficiency and unlocks capabilities that a single-model setup cannot easily support.
MCPMark Leaderboard Update 🚀
🌟 DeepSeek-V3.2-thinking jumps to the #1 spot among open-source models — and we’re honored to see MCPMark cited in the @deepseek_ai technical report.
⚡️ Gemini 3 Pro High @GoogleDeepMind now leads with the highest pass@1 and pass@4 success rates.
This update brings two newly released models onto the leaderboard: Gemini 3 and DeepSeek V3-2.
🚨Sensational title alert: we may have cracked the code to true multimodal reasoning.
Meet ThinkMorph — thinking in modalities, not just with them.
And what we found was... unexpected. 👀
Emergent intelligence, strong gains, and …🫣
🧵 https://t.co/2GPHnsPq7R
(1/16)
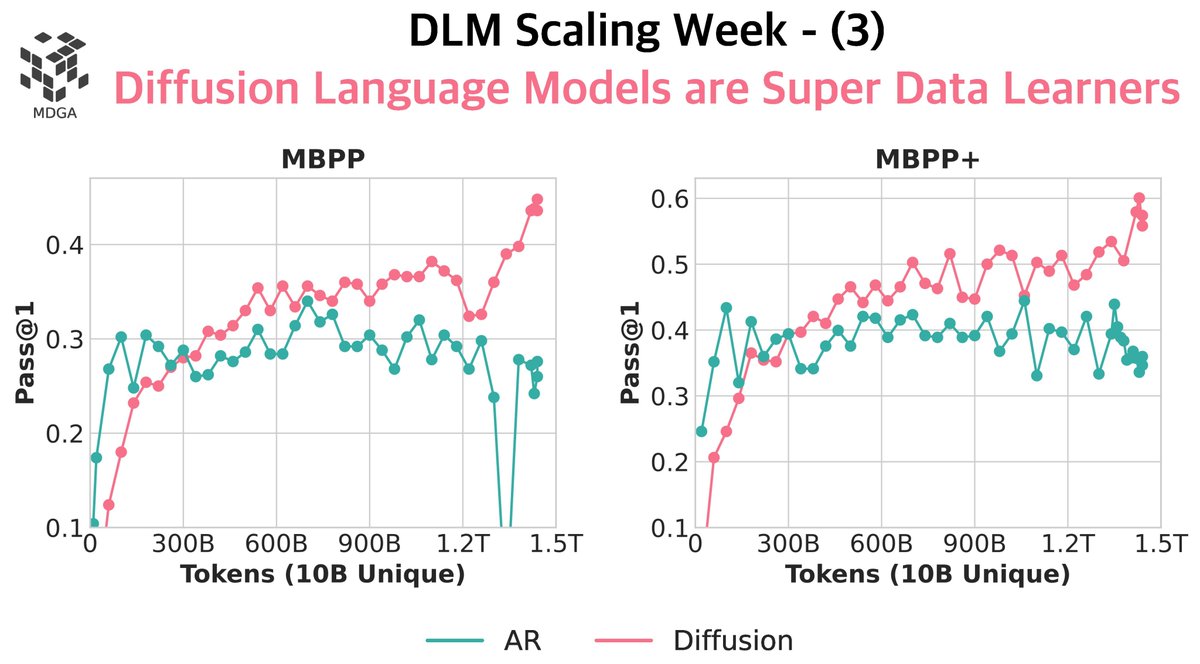
More repeats = more intelligence 🧬
We scaled up the crossover runs to 1.5 trillion tokens, with 10B unique.
The result?
😵 A clear crossover — and a strong 1.7B coder — without any fancy tricks.
We wrote a full paper on when and how diffusion language models surpass AR models, with 360° in-depth insights.
Paper (main url): https://t.co/SUcYUexAoc
Paper (backup url): https://t.co/VPoeRaakI5
GitHub: https://t.co/v9rSv9fiKj
🧵 1/7
Your agent can call tools; can it close the loop ?
We stress-tested MCP with 127 CRUD-heavy tasks across 5 MCPs and >30 models, using a minimal but general MCPMark-Agent for fair comparison.
📄 Paper: https://t.co/MfE5cce9r7
🌐 Website: https://t.co/uvSTQWA0Nn
💻 Code: https://t.co/iZIuvwl6LM
🤗 Daily Papers: https://t.co/HvBBz2gwbX
GPT-5 reaches 52.56% pass@1 and 33.86% pass^4, yet widely regarded strong models such as claude-sonnet-4 and o3 remain below 30% pass@1 and 15% pass^4. The newest Claude-sonnet-4.5 improves to 32.1% pass@1 and 16.5% pass^4 — just crossing the 30% line.
The full report dives into data distributions, failure modes, and case studies (PASS vs FAIL). Plus trajectory explorer to debug agents yourself.
👉 Our leaderboard already tracks by models and MCP servers, and will soon support agent submissions — we welcome the community to submit results!
Key insights in thread ⬇️
MCPMark Leaderboard Update 🚀
🌟 Qwen-3-Coder takes the #1 spot among open-source models, with an impressive per-run cost of just $36.46.
⚡️ Grok-Code-Fast-1 delivers the lowest per-run cost ($16.08) and the fastest average agent time (156.63s) across the top 10 models.
Kimi-K2-0905 outperforms Kimi2 in success rate, though at nearly double the per-run cost and average agent time.
Notably, Qwen-3-Coder achieves a success rate close to O3, but at roughly one-third the per-run cost — offering the community a highly cost-effective option for MCP tool-use applications.
This update introduces three newly released models to the leaderboard: Qwen-3-Max, Grok-Code-Fast-1, and Kimi-K2-0905.
🚀 🚀Just launched MCPMark, a challenging MCP benchmark I participated in. Its filesystem section include ops on files, structure exploration, reasoning, and multi-skill tasks. Most models show clear room for improvement, while GPT series excel in precise text manipulation
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
To me, diffusion LMs work because they remove unnecessary inductive biases. The left-to-right inductive bias is natural for human but is unlikely to be natural for AI. This gives more capacity to our models like Transformer having a bigger capacity than LSTM. Our experiment results show diffusion outperforms autoregressive in big margins.
We might enter a new paradigm if this trend holds for big models.🎅