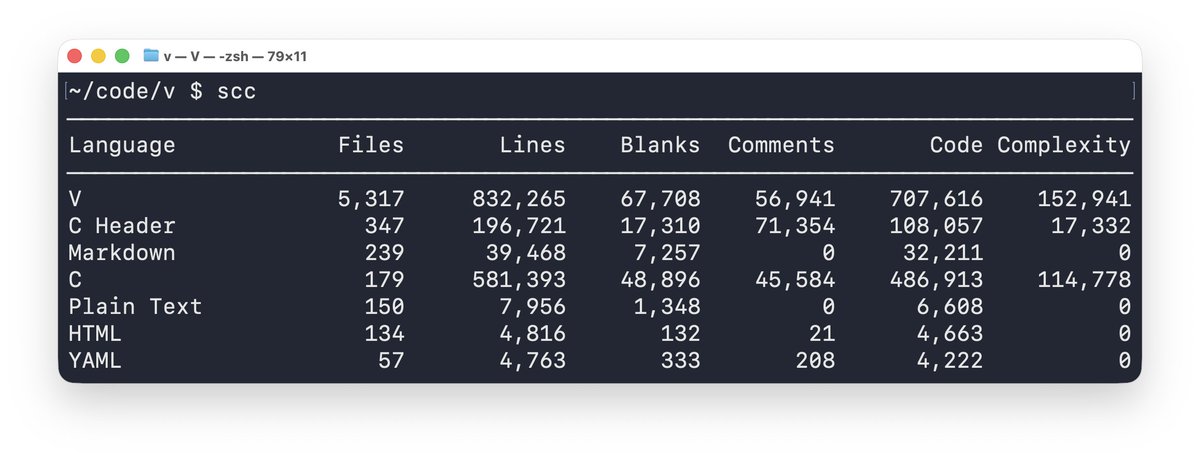
Ever wondered how a 35B parameter model can run on consumer GPUs? Qwen3.6-35B-A3B-NVFP4 is a Mixture of Experts model quantized to FP4, packing huge intelligence into a tiny memory footprint. This is the future of efficient AI.
I've had this side project on the backburner for a long time...
The XGecu line of universal programmers are awesome, but they come with some of the sketchiest proprietary Windows software ever. (XGPro)
MiniPro is an software program made to interact with the XGecu hardware. An open source XGPro alternative.
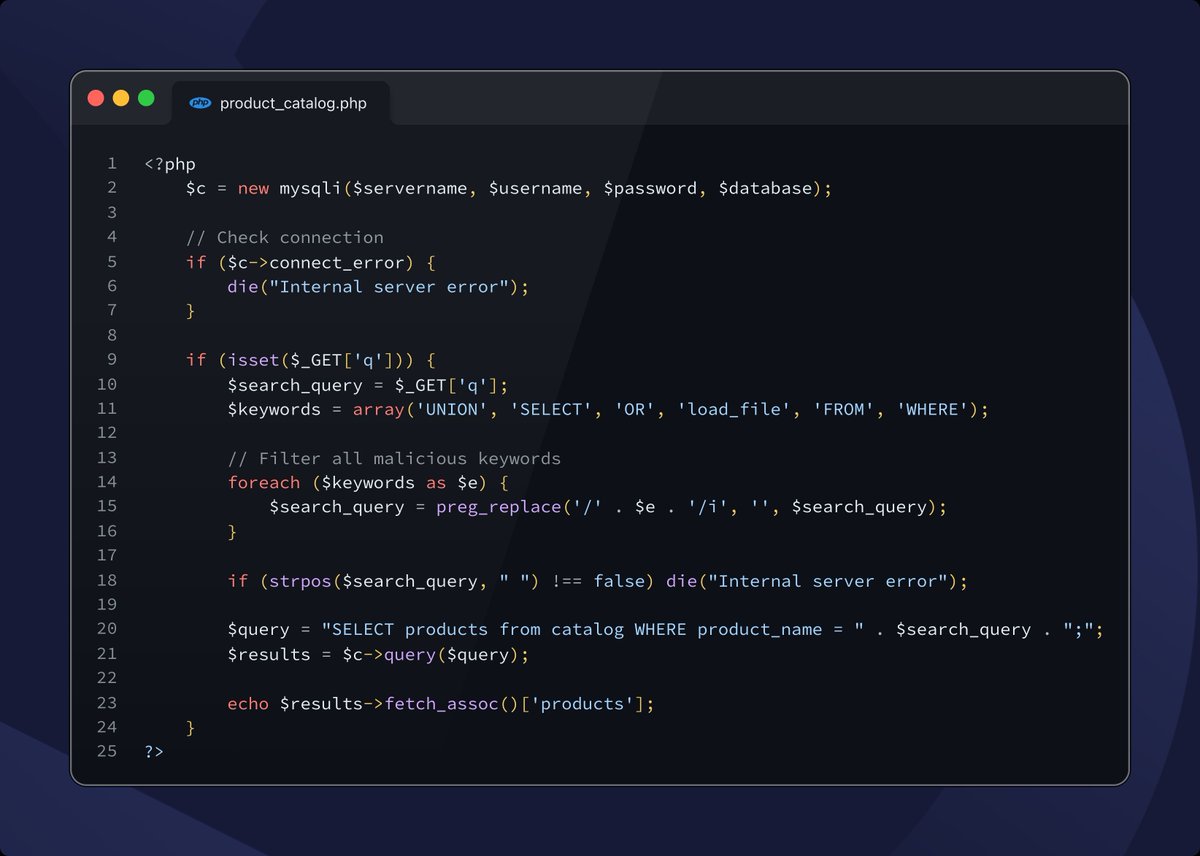
My First RCE by Reverse Engineering an EXE File With the Help of AI
A secure web app → a JS file leaking a download endpoint → a .NET binary → AI-assisted reverse engineering → a localhost WebSocket with no origin check → RCE
Write-up: https://t.co/CN6VM92hqA
i just ran Google's brand new Unsloth Gemma4 12B dense GGUF on my RTX 4060 using llama.cpp + CUDA 13.2
21 tokens per second. on a budget consumer GPU. locally.
no API. no cloud. no subscription.
and the benchmarks are absolutely cooked
# first let's talk architecture because this is genuinely different
every multimodal model you've used has a frozen vision encoder + frozen audio encoder + LLM backbone glued together
Gemma 4 12B is different
it's a single decoder only transformer. that's it. vision? raw 48×48 pixel patches → one matmul → projected directly into the LLM
audio? raw 16kHz signal sliced into 40ms frames → linear projection → same LLM input space
no encoder tax. no latency penalty. no fragmented memory
to put the encoder savings in perspective:
old Gemma 4 26B approach:
- 550M param vision encoder (frozen)
- 300M param audio encoder (frozen)
- LLM backbone
Gemma 4 12B:
- 35M param vision embedder (a single matmul)
- no audio encoder at all
- LLM backbone handles EVERYTHING 550M → 35M for vision alone. that's a 15x reduction
this is why the gemma-4-12b-it-Q4_K_M.gguf is just 6.6 GBs!!!
and it has 256K native context context
# Benchmarks:
AIME 2026 (math olympiad): 77.5%
GPQA Diamond (expert science): 78.8% LiveCodeBench v6 (real code): 72%
Codeforces ELO: 1659
MMLU Pro: 77.2%
MATH-Vision: 79.7%
BigBench Extra Hard: 53%
inference → llama.cpp, LM Studio, vLLM, SGLang
llamacpp flags:
-m "gemma-4-12b-it-Q4_K_M.gguf" -ngl 99 -c 8000 -v --port 8080
Available on huggingface now! Link below
Your government can't see what you're doing online.
obfs4 bridges + ProxyChains = encrypted noise.
No signatures. No flags. No trace.
New identity every 30 seconds.
This is why they want to ban encryption. 🧅
#Tor#ProxyChains#OPSEC#Cybersecurity#InfoSec
Spent 4 months building the ultimate mosquito killer: an artillery cannon guided by computer vision + deep learning.
Trained a custom model to detect and lock onto mosquitoes using a DSLR + zoom lens setup.
The dataset collection phase was brutal — the mosquitoes definitely fought back 🦟
Un grupo de estudiantes chinos compró 7 Mac Mini en eBay por un total de 1.600 $, los conectó mediante Ethernet para formar un solo sistema y luego abrió una firma financiera basada en IA directamente en su dormitorio universitario.
Su primer cliente le pagaba a un asesor financiero 8.400 $ al año. Ellos cobraron 240 $ al año por hacer lo mismo, pero mejor.
Claude lee los informes 10-K en unos segundos, construye modelos de asignación sin sesgos de comisiones, ejecuta escenarios de optimización fiscal y proyecta la jubilación al dólar exacto.
Un asesor financiero que gestiona un portafolio de 500.000 $ cobra unos 5.000 $ al año solo por existir, y el 92 % de ellos rinde peor que un simple fondo indexado en 15 años.
Warren Buffett apostó 1.000.000 $ a que un simple fondo indexado del S&P 500 superaría a cualquier fondo de cobertura en 10 años. Ganó con 854.000 $ de ventaja.
Siete Mac Mini, un archivo CLAUDE.md y 240 $ al año reemplazaron a un equipo de analistas. Primer mes: 8 clientes. Segundo mes: 20 gracias al boca a boca.
1.600 $ invertidos una sola vez. El resto son solo líneas en una hoja de cálculo del cliente.
📌 The @SatNOGS Network 📡 is tracking some of the #satellites 🛰️🛰️ of the CAS500-2 rideshare.
#Falcon9@SLDelta30
🌎🌍🌏
Follow all the updates at: https://t.co/p40WWLu4lk
DeepZero: Find Zero-Days While You Sleep with an Automated Kernel Driver Exploit Hunting Engine ⚙️💀
Parses → Decompiles → Scans → Ranks → LLM Analysis
Targets thousands of Windows drivers to uncover exploitable IOCTLs and hidden attack surfaces — fully automated pipeline with YAML.
Ghidra + Semgrep + LLMs + parallel execution + resumable state
Built for real vulnerability research, not surface-level scanning.
https://t.co/9YImng1JDb
#ZeroDay #VulnResearch #AppSec #ReverseEngineering #RedTeam #CyberSecurity
Last month, during a pentest I was able to obtain unauthenticated access to Concrete CMS configuration details by triggering a "Conflicting Headers" exception in Symfony. I did this by sending a request with both Forwarded and X-Forwarded-Host headers. From that, I was able to retrieve sensitive environment information such as SMTP credentials, application paths, and system configuration. I recently published a Nuclei template that can help identify this misconfiguration and surface useful information for your future pentest/bug-bounty operations.
Today, during a penetration testing engagement, I successfully bypassed the authentication form and gained admin access on the web application by exploiting a NoSQL injection using operators. To be honest, I always test it, but this is the first time it actually worked😄
https://t.co/LhA2dDQedB